
本文以mnist数据集为例。estimator通常是和tf的dataset一起使用,故先制作tfrecord文件,在使用estimator进行测试。
文章结构:
1.文件目录
2. 制作tfrecord文件
3.使用estimator训练模型
4.tf.estimator.Estimator()参数介绍:
文件目录:

data目录下存放mnist数据集,并且tfrecord文件也将存放在data目录下。
result目录下保存训练的模型
make_record.py: 制作tfreocrd文件
mnist.py: 使用estimator训练模型、test结果
制作tfrecord文件:
from tensorflow.examples.tutorials.mnist import input_data import tensorflow as tf mnist = input_data.read_data_sets("./data/", one_hot=True) def tf_record(data, labels, path): #data是mnist图片 #labels是图片的标签 # path是tfrecord保存的路劲 writer=tf.python_io.TFRecordWriter(path) for example, label in zip(data, labels): tf_example=tf.train.Example( features=tf.train.Features( feature={ "image":tf.train.Feature(float_list=tf.train.FloatList(value=list(example))), "label":tf.train.Feature(float_list=tf.train.FloatList(value=list(label))) } ) ) writer.write(tf_example.SerializeToString()) writer.close()使用estimator训练模型:
from tensorflow.examples.tutorials.mnist import input_data import tensorflow as tf from make_record import tf_record flags = tf.flags FLAGS = flags.FLAGS tf.logging.set_verbosity(tf.logging.INFO) # 模型部分,使用2个卷积+全连接进行建模 def create_model(images): def weight_variable(shape): initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial) def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial) def conv2d(x, W): return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') def max_poo_2x2(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') image = tf.reshape(images, [-1, 28, 28, 1]) W_conv1 = weight_variable([5, 5, 1, 32]) b_conv1 = bias_variable([32]) h_conv1 = tf.nn.relu(conv2d(image, W_conv1) + b_conv1) h_pool1 = max_poo_2x2(h_conv1) W_conv2 = weight_variable([5, 5, 32, 64]) b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) h_pool2 = max_poo_2x2(h_conv2) W_fc1 = weight_variable([7 * 7 * 64, 1024]) b_fc1 = bias_variable([1024]) h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) W_fc2 = weight_variable([1024, 10]) b_fc2 = bias_variable([10]) prediction = tf.nn.softmax(tf.matmul(h_fc1, W_fc2) + b_fc2) return prediction # 将词函数传递给estimator的model_fn参数 # 关于estimator中的各个参数作用,见后 def model_fn(features,mode): is_training = (mode == tf.estimator.ModeKeys.TRAIN) prediction = create_model(images=images) if is_training: labels = features['label'] loss = tf.reduce_mean(-tf.reduce_sum(labels * tf.log(prediction))) train_op = tf.train.AdamOptimizer(1e-4).minimize(loss, global_step=tf.train.get_or_create_global_step()) return tf.estimator.EstimatorSpec( mode=tf.estimator.ModeKeys.TRAIN, loss=loss, train_op=train_op) if mode == tf.estimator.ModeKeys.PREDICT: labels = features['label'] return tf.estimator.EstimatorSpec( mode=tf.estimator.ModeKeys.PREDICT, predictions={ "ground_truth":tf.argmax(labels, axis=1), "prediction":tf.argmax(prediction, axis=1) }) # 此函数返回一个函数, 其返回train的dataset def input_fn_builder(input_file): def input_fn(): def pase(record): keys_to_features = { "image": tf.FixedLenFeature([784], tf.float32), "label": tf.FixedLenFeature([10], tf.float32) } parsed = tf.parse_single_example(record, keys_to_features) return parsed d = tf.data.TFRecordDataset(input_file) return d.map(pase).shuffle(buffer_size=100).batch(32).repeat(10) return input_fn # 此函数返回一个函数, 其返回test的dataset def input_fn_builder_test(input_file): def input_fn(): def pase(record): keys_to_features = { "image": tf.FixedLenFeature([784], tf.float32), "label": tf.FixedLenFeature([10], tf.float32) } parsed = tf.parse_single_example(record, keys_to_features) return parsed d = tf.data.TFRecordDataset(input_file) return d.map(pase).shuffle(buffer_size=100).batch(32).repeat(1) return input_fn def main(_): tf.logging.set_verbosity(tf.logging.INFO) tf.logging.info("read mnist dataset") mnist = input_data.read_data_sets('./data', one_hot=True) tf.logging.info("make train record") train = mnist.train.images labels = mnist.train.labels tf_record(train, labels, "./data/train_record") tf.logging.info("make test record") test = mnist.test.images labels = mnist.test.labels tf_record(test, labels, "./data/test_record") session_config = tf.ConfigProto(log_device_placement=True) session_config.gpu_options.per_process_gpu_memory_fraction = 0.5 # 运行配置,如空置显存,训练多少步(这里是2000)保存一次。 run_config = tf.estimator.RunConfig(session_config=session_config,,save_checkpoints_steps=2000) # model_dir是模型的保存路径 # model_fn是模型函数 # config是运行配置 estimator = tf.estimator.Estimator( model_dir="./result", model_fn=model_fn, config=run_config, ) input_fn = input_fn_builder("./data/train_record") input_fn_test = input_fn_builder_test("./data/test_record") # 训练 estimator.train(input_fn=input_fn) all_results = [] # 测试 for result in estimator.predict(input_fn_test, yield_single_examples=True): if len(all_results) % 1000 == 0: tf.logging.info("Processing example: %d" % (len(all_results))) label = int(result["ground_truth"]) prediction = int(result['prediction']) all_results.append([label, prediction]) acc = 0. for idx, result in enumerate(all_results): if idx == 0: print(type(result)) print(type(all_results)) print(len(all_results)) print(len(result)) if result[0] == result[1]: acc = acc + 1 print(acc/len(all_results)) if __name__ == "__main__": tf.app.run() 结果:
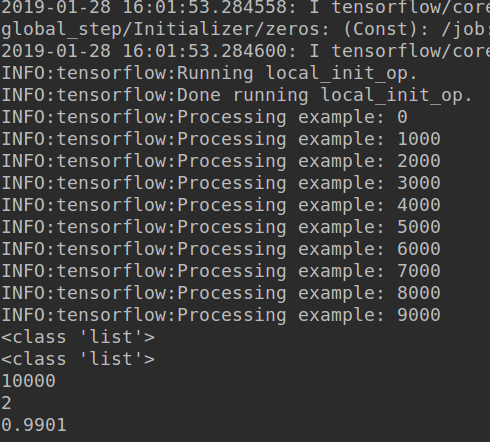
模型:

tf.estimator.Estimator()参数介绍:
这个只能自己看了
class Estimator(object): """Estimator class to train and evaluate TensorFlow models. The `Estimator` object wraps a model which is specified by a `model_fn`, which, given inputs and a number of other parameters, returns the ops necessary to perform training, evaluation, or predictions. All outputs (checkpoints, event files, etc.) are written to `model_dir`, or a subdirectory thereof. If `model_dir` is not set, a temporary directory is used. The `config` argument can be passed `RunConfig` object containing information about the execution environment. It is passed on to the `model_fn`, if the `model_fn` has a parameter named "config" (and input functions in the same manner). If the `config` parameter is not passed, it is instantiated by the `Estimator`. Not passing config means that defaults useful for local execution are used. `Estimator` makes config available to the model (for instance, to allow specialization based on the number of workers available), and also uses some of its fields to control internals, especially regarding checkpointing. The `params` argument contains hyperparameters. It is passed to the `model_fn`, if the `model_fn` has a parameter named "params", and to the input functions in the same manner. `Estimator` only passes params along, it does not inspect it. The structure of `params` is therefore entirely up to the developer. None of `Estimator`'s methods can be overridden in subclasses (its constructor enforces this). Subclasses should use `model_fn` to configure the base class, and may add methods implementing specialized functionality. @compatibility(eager) Estimators are not compatible with eager execution. @end_compatibility """ def __init__(self, model_fn, model_dir=None, config=None, params=None, warm_start_from=None): """Constructs an `Estimator` instance. See @{$estimators} for more information. To warm-start an `Estimator`: python estimator = tf.estimator.DNNClassifier( feature_columns=[categorical_feature_a_emb, categorical_feature_b_emb], hidden_units=[1024, 512, 256], warm_start_from="/path/to/checkpoint/dir") For more details on warm-start configuration, see @{tf.estimator.WarmStartSettings$WarmStartSettings}. Args: model_fn: Model function. Follows the signature: * Args: * `features`: This is the first item returned from the `input_fn` passed to `train`, `evaluate`, and `predict`. This should be a single `Tensor` or `dict` of same. * `labels`: This is the second item returned from the `input_fn` passed to `train`, `evaluate`, and `predict`. This should be a single `Tensor` or `dict` of same (for multi-head models). If mode is `ModeKeys.PREDICT`, `labels=None` will be passed. If the `model_fn`'s signature does not accept `mode`, the `model_fn` must still be able to handle `labels=None`. * `mode`: Optional. Specifies if this training, evaluation or prediction. See `ModeKeys`. * `params`: Optional `dict` of hyperparameters. Will receive what is passed to Estimator in `params` parameter. This allows to configure Estimators from hyper parameter tuning. * `config`: Optional configuration object. Will receive what is passed to Estimator in `config` parameter, or the default `config`. Allows updating things in your `model_fn` based on configuration such as `num_ps_replicas`, or `model_dir`. * Returns: `EstimatorSpec` model_dir: Directory to save model parameters, graph and etc. This can also be used to load checkpoints from the directory into a estimator to continue training a previously saved model. If `PathLike` object, the path will be resolved. If `None`, the model_dir in `config` will be used if set. If both are set, they must be same. If both are `None`, a temporary directory will be used. config: Configuration object. params: `dict` of hyper parameters that will be passed into `model_fn`. Keys are names of parameters, values are basic python types. warm_start_from: Optional string filepath to a checkpoint to warm-start from, or a `tf.estimator.WarmStartSettings` object to fully configure warm-starting. If the string filepath is provided instead of a `WarmStartSettings`, then all variables are warm-started, and it is assumed that vocabularies and Tensor names are unchanged. Raises: RuntimeError: If eager execution is enabled. ValueError: parameters of `model_fn` don't match `params`. ValueError: if this is called via a subclass and if that class overrides a member of `Estimator`. """若有问题欢迎评论指出!!转载请标明地址:https://mp.csdn.net/postedit/
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/202881.html原文链接:https://javaforall.net


