
特征提取之Haar特征
一、前言(废话)
很久没有写博客了,一晃几年就过去了,为了总结一下自己看的一些论文,以后打算写一些自己读完论文的总结。那么,今天就谈一谈人脸检测最为经典的算法Haar-like特征+Adaboost。这是最为常用的物体检测的方法(最初用于人脸检测),也是用的最多的方法,而且OpenCV也实现了这一算法,可谓路人皆知。另外网上写这个算法的人也不在少数。
二、概述
首先说明,我主要看了《Rapid Object Detection using a Boosted Cascade of Simple Features》和《Empirical Analysis of Detection Cascades of Boosted Classifiers for Rapid Object Detection》这两篇论文。
2.1为什么需要Haar特征,为什么要结合Adaboost算法
我们知道人脸检测是很不容易的,我们在实际进行人脸检测的时候,需要考虑算法的运行速度,以及算法的准确度,单单实现这两个指标就已经很不容易了。传统的人脸检测方法(指的是在Haar-like特征出来之前的方法,也就是2001年之前了)一般都是基于像素级别进行的,常见的方法有基于皮肤颜色的方法,这些方法的缺点就是速度慢,几乎不能实现实时性。
2.2算法的大体流程
接下来就对算法的关键的步骤进行介绍。
3具体介绍
3.1图像预处理(归一化或者称为光照修正)
我们知道不同的光照对于所处理的图像有影响,为了减低这种影响我们需要首先对图像进行归一化(在《Rapid Object Detection using a Boosted Cascade of Simple Features》中称之为归一化,而在《Empirical Analysis of Detection Cascades of Boosted Classifiers for Rapid Object Detection》中称之为Lighting Correction,即光照修正)。
上述公式中 i¯(x,y) 表示归一化之后的图像,而 i(x,y) 表示原始的图像,其中 μ 表示图像的均值,而 σ 表示图像的标准差。计算方法很简单,均值就是图像中的所有像素值相加,然后除以像素的个数,而方差假定每个像素的概率相等如果一幅图像中有N个像素,那么每个像素的概率为 1N , σ2=1N∑xx2−μ2 ,注意这里的x是指的每个像素值, ∑x 表示对所有的像素值求和。
其实这里我看到《Rapid Object Detection using a Boosted Cascade of Simple Features》中第六页它写成了 σ2=μ2−1N∑xx2 。
3.2提取特征
计算特征很简单,就是拿黑色部分的所有的像素值的和减去白色部分所有像素值的和。得到的就是一个特征值。
说的很简单,但是在工程中需要进行快速计算某个矩形内的像素值的和,这就需要引入积分图的概念。
(1)使用积分图加速计算特征
需要注意的是这里的积分图输入的图像是经过归一化的图像哈。与上面用到的符号不一样了。
上述含义是指在位置 (x,y) 上,对应的积分图中的像素为该位置的左上角所有的像素的之和。
初始值 s(x,−1)=0,ii(−1,y)=0 .
上面这两个递归公式是什么意思呢?就是首先每一行都递归计算s(x,y)(公式中也可以看出是按行计算的),每一行首先都是计算s,计算完毕之后在每一列都计算ii(x,y)。这样扫描下去就可以计算好了积分图了。这种方法跟动态规划的思想有点类似。
好了计算好了积分图,我们接下来就可以利用积分图来加速计算某个方块内部的像素的和了。
(2)计算方块内的像素和

图2 计算某个方块内的像素和
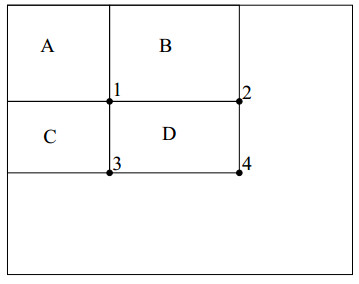
图中的大框是积分图,为了讲解如何计算任意矩形内的像素值,我们画出四个区域A、B、C、D,并且图中有四个位置分别为1、2、3、4。我们要计算D区域内部的像素和该怎么计算?
我们记位置4的左上的所有像素为 rectsum(4) ,那么
D位置的像素之和就是 rectsum(1)+rectsum(4)−rectsum(2)−rectsum(3) 。
是不是有了积分图,就可以很快地计算出了任意矩形内的像素之和了?
(3)提取的特征的个数有多少?
加起来一共有大约16000多个(不止16000哈)。可以自己算一下。
3.3使用Adaboost进行训练
在输入图像之后首先计算积分图,然后通过积分图在计算上述三种特征,如果窗口的大小为24*24像素,那么生成的特征数目有16000之多。
(1)弱分类器的定义
Adaboost算法中需要定义弱分类器,该弱分类器的定义如下:
10ifpjfj(x)<pjθjotherwise
上述公式中的 pj 是为了控制不等式的方向而设置的参数。
fj(x) 表示输入一个窗口 x ,比如24*24像素的窗口,通过
fj
(2)adaboost算法
假设训练样本图像为 (x1,y1),…,(xn,yn) ,其中 yi=0,1 ,0表示负样本,1表示正样本。
首先初始化权重 w1,i=12m ,初始化 yi为22l ,其中m表示负样本的个数,l表示正样本的个数。
For t=1,…,T :
(1).首先归一化权重: wt,i=wt,i∑nj=1wt,j 。
(2)对于每一个特征,我们都训练一个分类器(记为 hj ),每个分类器都只使用一种特征进行训练。
那么对于该特征的误差 ϵj 可以这么衡量: ϵj=∑iwi|hj(xi)−yi| ( j 表示的是某个特征的索引,而
i
(3)选择拥有最低误差的那个分类器记为 ht 。
(4)更新权重 wt+1,i=wt,iβ1−eit (如果分类正确则 ei=1 ,错误 ei=0 )。
End For
其中 αt=log1βt
4其他一些参数的确定
4.1如何确定有多少个级联的分类器,有多少个特征,阈值如何确定的。
如图3可以看出在训练过程当中需要确定究竟有多少个分离器级联才是最佳的,以及使用多少个特征,每个弱分类器的阈值如何确定,这些参数的确定基本不可能实现。
4.2 扫描窗口的时候的缩放如何确定
假设扫描的时候的步长为 Δ ,尺度为 s
那么当前的步长= [
s
4.3 合并检测出的多个窗口
检测到的子窗口的集合分成若干不相交的子集(每个子集中的子窗口都是相互重叠的),这些子集中的子窗口进行合并,集合中所有子窗口的左上角的坐标的平均即为该集合所确定的窗口的左上角的坐标。
5 补充说明
5.1 Haar-like特征的分类(Haar-like特征的变种)
图4中给出了四种分类分为将边缘特征、线特征、中心环绕特征以及对角线特征。
X 和
Y
计算公式如下
对于旋转45 °的特征其计算公式如下:
其中 z=w+h
至于怎么计算旋转45°的特征值,这里先挖个坑。过一段时间在补充上来。
5.2 Adaboost的变种
《Empirical Analysis of Detection Cascades of Boosted Classifiers for Rapid Object Detection》中介绍了三种变种分为Real Adaboost ,Discrete Adaboost以及Gentle Adaboost。差别不是很大。具体参考该论文。
6 参考文献
7 想要说的话
后期会分析一下Haar进行人脸检测的代码(matlab和OpenCV的实现),看时间允许不允许了。
http://www.mathworks.com/matlabcentral/fileexchange/29437-viola-jones-object-detection
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/203199.html原文链接:https://javaforall.net


