


全栈工程师开发手册 (作者:栾鹏)
python开发大全、系列文章、精品教程
数据挖掘的技术过程:
- 数据清理(消除噪音或不一致数据)
- 数据集成(多种数据源可以组合在一起)
- 数据选择(从数据库中提取与分析任务相关的数据)
- 数据变换(数据变换或统一成适合挖掘的形式;如,通过汇总或聚集操作)
- 数据挖掘(基本步骤,使用智能方法提取数据模式)
- 模式评估(根据某种兴趣度度量,识别提供知识的真正有趣的模式)
- 知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)。


可以挖掘的数据类型:
关系数据库、数据仓库、事务数据库、空间数据库、时间序列数据库、文本数据库和多媒体数据库。
关系数据库:是表的集合,每个表都赋予一个唯一的名字。每个表包含一组 属性(列或字段),并通常存放大量 元组(记录或行)。关系中的每个元组代表一个被唯一关键字标识的对象,并被一组属性值描述。
事务数据库:由一个文件组成,其中每个记录代表一个事务。通常,一个事务包含一个唯一的事务标识号(trans_ID),和一个组成事务的项的列表(如,在商店购买的商品)
数据抽样:
- 抽样方法
有许多抽样技术,但是这里只介绍少数最基本的抽样技术和它们的变形。最简单的抽样是简单随机抽样(simple random sampling)。对于这种抽样,选取任何特定项的概率相等。随机抽样有两种变形(其他抽样技术也一样):(1) 无放回抽样–每个选中项立即从构成总体的所有对象集中删除;(2) 有放回抽样–对象被选中时不从总体中删除。在有放回抽样中,相同的对象可能被多次抽出。当样本与数据集相比相对较小时,两种方法产生的样本差别不大。但是,对于分析,有放回抽样较为简单,因为在抽样过程中,每个对象被选中的概率保持不变。
当总体由不同类型的对象组成,每种类型的对象数量差别很大时,简单随机抽样不能充分地代表不太频繁出现的对象类型。当分析需要所有类型的代表时,这可能出现问题。例如,当为稀有类构建分类模型时,样本中适当地提供稀有类是至关重要的,因此需要提供具有不同频率的感兴趣的项的抽样方案。分层抽样(stratified sampling)就是这样的方法,它从预先指定的组开始抽样。在最简单的情况下,尽管每组的大小不同,但是从每组抽取的对象个数相同。另一种变形是从每一组抽取的对象数量正比于该组的大小。
例2.8 抽样与信息损失 一旦选定抽样技术,就需要选择样本容量。较大的样本容量增大了样本具有代表性的概率,但也抵消了抽样带来的许多好处。反过来,使用较小容量的样本,可能丢失模式,或检测出错误的模式。图2-9a显示包含8 000个二维点的数据集,而图2-9b和图2-9c显示从该数据集抽取的容量分别为2 000和500的样本。该数据集的大部分结构都出现在2 000个点的样本中,但是许多结构在500个点的样本中丢失了。
数据预处理
分箱法:
可以挖掘的模式类型:
挖掘频繁模式、关联和相关性
用于预测分析的分类与回归
聚类分析
离群点分析
使用的技术

面向的应用类型
商务智能、web搜索引擎
在挖掘中需要注意的东西
源数据特征方面:
数据间相似性和相异性的度量:
数据预处理方面(清洗、集承、归约、变换):

数据结果方面:
数据挖掘算法
分类器与聚类算法不同。聚类算法是非监督算法,只是对一群输入对象进行分组,每组属于什么类别是不知道的。而分类器是在没有任何数据前就已经定好了拥有哪些类。分类器是监督算法。对一批已知所属分类的数据集进行统计训练。然后再对新来的数据进行判定属于哪个分类。
分类过程概述:首先有一批已知分类的数据集。对每个输入对象提取特征,根据输入对象的特征属性和输入对象的所属分类,计算分类与特征属性之间的概率关系,以此来实现样本的训练。当对新的输入对象进行预测所属分类时,提取新输入对象的特征,根据训练好的概率,判断输入对象属于每个分类的概率。
python机器学习算法
参考:https://blog.csdn.net/luanpeng/article/details/
python机器学习库教程
参考:https://blog.csdn.net/luanpeng/article/details/
分类模型的评判
用什么评估:
混淆矩阵(Confusion Matrix)分析
怎么评估:
交叉验证
评估结果:
一个模型在训练数据上能够获得比其他模型更好的拟合, 但是在训练数据外的数据集上却不能很好地拟合数据,此时认为这个模型出现了过拟合的现象。出现这种现象的主要原因是训练数据中存在噪音或者训练数据太少。
例如下图
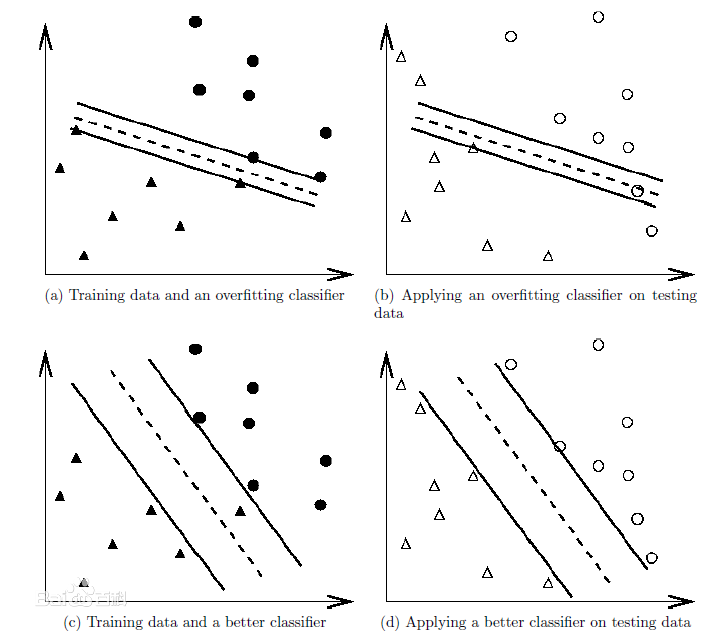
可以看出在a中虽然完全的拟合了样本数据,但对于b中的测试数据分类准确度很差。而c虽然没有完全拟合样本数据,但在d中对于测试数据的分类准确度却很高。过拟合问题往往是由于训练数据少等原因造成的。
由测量的样本数据,估计一个假定的模型/函数。根据拟合的模型是否合适?可分为以下三类:
欠拟合:

合适的拟合:

过拟合:

大数据工程师基技能图谱:

在博客的文章中我们会尽量给出数据中所设计的技术教程。
其中数据可视化中,我们给出了echart教程http://blog.csdn.net/luanpeng/article/details/
python中给出numpy和pandas库的使用
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/203249.html原文链接:https://javaforall.net

![eclipse 自动补全提示会卡死[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
