
pytorch LSTM 时间序列预测
#%% import pandas as pd import numpy as np import torch from torch import nn from torch.nn import functional as F from torch.utils.data import TensorDataset, DataLoader import torchkeras from plotly import graph_objects as go from sklearn.preprocessing import MinMaxScaler #%% # 导入数据 # 数据下载:https://www.kaggle.com/kankanashukla/champagne-data # 下载地址2:https://gitee.com/jejune/Datasets/blob/master/champagne.csv df = pd.read_csv('champagne.csv', index_col=0) df.head() Month Sales 1964-01 2815 1964-02 2672 1964-03 2755 1964-04 2721 1964-05 2946 #%% # 数据预览 fig = go.Figure() fig.add_trace(go.Scatter(x=df.index, y=df['Sales'], name='Sales')) fig.show() 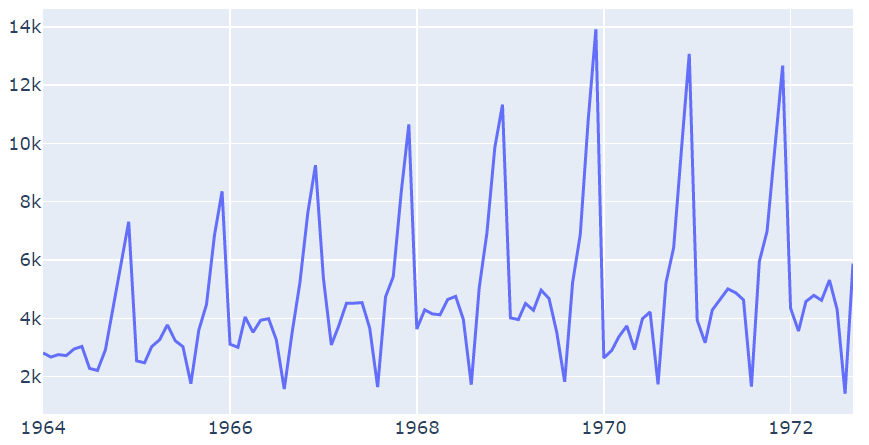

#%% # 数据处理 # 归一化 [0, 1] scaler = MinMaxScaler() predict_field = 'Scaler' df[predict_field] = scaler.fit_transform(df['Sales'].values.reshape(-1, 1)) df.head() Month Sales Scaler 1964-01 2815 0. 1964-02 2672 0. 1964-03 2755 0. 1964-04 2721 0. 1964-05 2946 0. #%% def create_dataset(data:list, time_step: int): arr_x, arr_y = [], [] for i in range(len(data) - time_step - 1): x = data[i: i + time_step] y = data[i + time_step] arr_x.append(x) arr_y.append(y) return np.array(arr_x), np.array(arr_y) time_step = 8 X, Y = create_dataset(df[predict_field].values, time_step) #%% # cuda device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 转化成 tensor->(batch_size, seq_len, feature_size) X = torch.tensor(X.reshape(-1, time_step, 1), dtype=torch.float).to(device) Y = torch.tensor(Y.reshape(-1, 1, 1), dtype=torch.float).to(device) print('Total datasets: ', X.shape, '-->', Y.shape) # 划分数据 split_ratio = 0.8 len_train = int(X.shape[0] * split_ratio) X_train, Y_train = X[:len_train, :, :], Y[:len_train, :, :] print('Train datasets: ', X_train.shape, '-->', Y_train.shape) Total datasets: torch.Size([96, 8, 1]) --> torch.Size([96, 1, 1]) Train datasets: torch.Size([76, 8, 1]) --> torch.Size([76, 1, 1]) #%% # 构建迭代器 batch_size = 10 ds = TensorDataset(X, Y) dl = DataLoader(ds, batch_size=batch_size, num_workers=0) ds_train = TensorDataset(X_train, Y_train) dl_train = DataLoader(ds_train, batch_size=batch_size, num_workers=0) # 查看第一个batch x, y = next(iter(dl_train)) print(x.shape) print(y.shape) torch.Size([10, 8, 1]) torch.Size([10, 1, 1]) #%% # 定义模型 class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.lstm = nn.LSTM(input_size=1, hidden_size=6, num_layers=3, batch_first=True) self.fc = nn.Linear(in_features=6, out_features=1) def forward(self, x): # x is input, size (batch_size, seq_len, input_size) x, _ = self.lstm(x) # x is output, size (batch_size, seq_len, hidden_size) x = x[:, -1, :] x = self.fc(x) x = x.view(-1, 1, 1) return x #%% # torchkeras API 训练方式 model = torchkeras.Model(Net()) model.summary(input_shape=(time_step, 1)) model.compile(loss_func=F.mse_loss, optimizer=torch.optim.Adam(model.parameters(), lr=1e-2), device=device) dfhistory = model.fit(epochs=50, dl_train=dl_train, log_step_freq=20) ---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ LSTM-1 [-1, 8, 6] 888 Linear-2 [-1, 1] 7 ================================================================ Total params: 895 Trainable params: 895 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.000031 Forward/backward pass size (MB): 0.000374 Params size (MB): 0.003414 Estimated Total Size (MB): 0.003819 ---------------------------------------------------------------- Start Training ... ================================================================================2022-03-28 12:21:58 +-------+-------+ | epoch | loss | +-------+-------+ | 1 | 0.045 | +-------+-------+ ================================================================================2022-03-28 12:21:59 +-------+-------+ | epoch | loss | +-------+-------+ | 2 | 0.054 | +-------+-------+ ... +-------+-------+ | epoch | loss | +-------+-------+ | 50 | 0.003 | +-------+-------+ ================================================================================2022-03-28 12:22:00 Finished Training... #%% # 模型评估 fig = go.Figure() fig.add_trace(go.Scatter(x=dfhistory.index, y=dfhistory['loss'], name='loss')) fig.show() 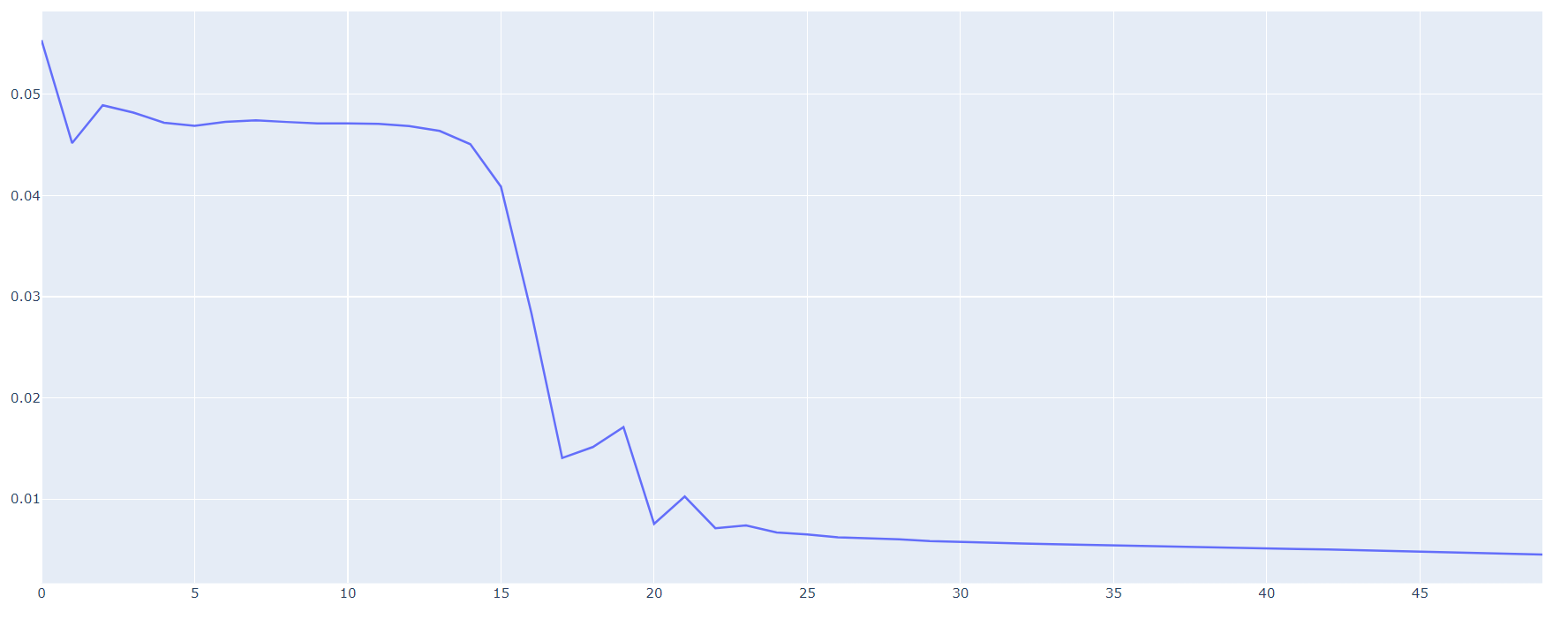
#%% # 预测验证预览 y_true = Y.cpu().numpy().squeeze() y_pred = model.predict(dl).detach().cpu().numpy().squeeze() fig = go.Figure() fig.add_trace(go.Scatter(y=y_true, name='y_true')) fig.add_trace(go.Scatter(y=y_pred, name='y_pred')) fig.show() 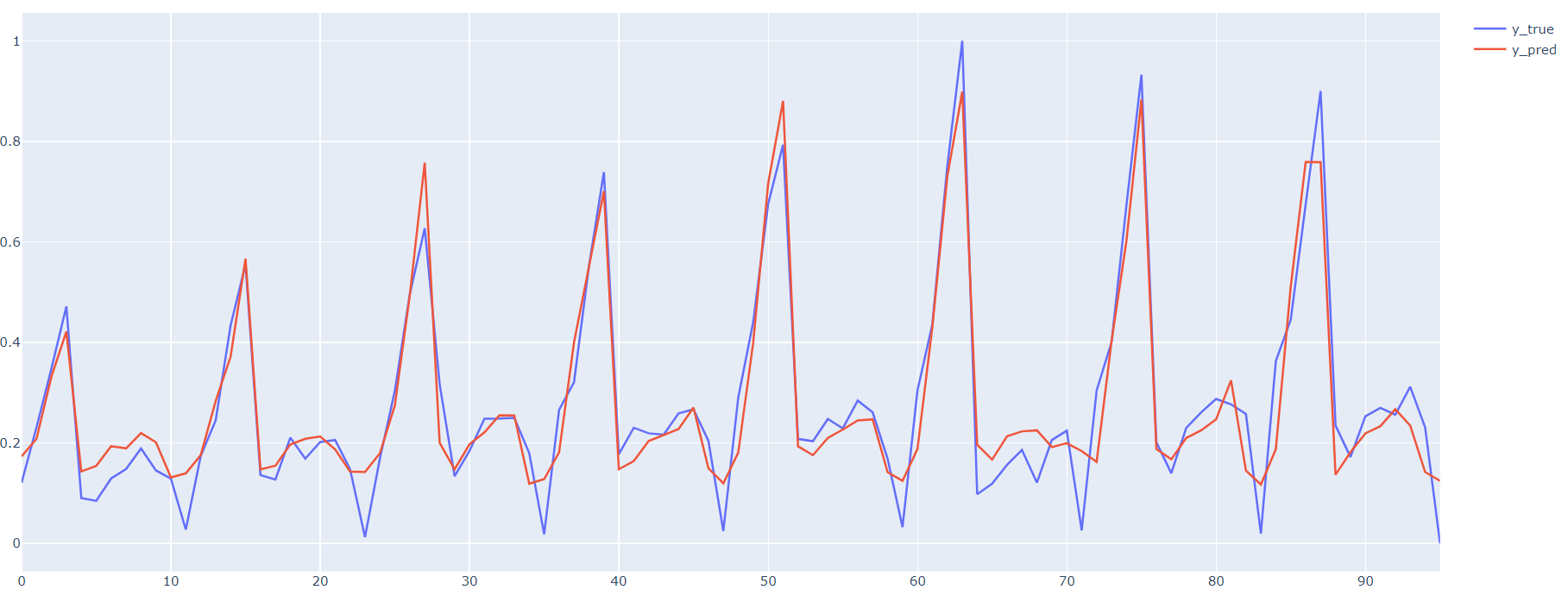
#%% # 自定义训练方式 model = Net().to(device) loss_function = nn.MSELoss() optimizer = torch.optim.Adam(model.parameters(), lr=1e-2) def train_step(model,features, labels): # 正向传播求损失 predictions = model.forward(features) loss = loss_function(predictions, labels) # 反向传播求梯度 loss.backward() # 参数更新 optimizer.step() optimizer.zero_grad() return loss.item() # 测试一个batch features, labels = next(iter(dl_train)) loss = train_step(model, features, labels) loss 0.0 #%% # 训练模型 def train_model(model, epochs): for epoch in range(1, epochs+1): list_loss = [] for features, labels in dl_train: lossi = train_step(model,features, labels) list_loss.append(lossi) loss = np.mean(list_loss) if epoch % 10 == 0: print('epoch={} | loss={} '.format(epoch,loss)) train_model(model, 50) epoch=10 | loss=0.0 epoch=20 | loss=0.028499 epoch=30 | loss=0.0064524 epoch=40 | loss=0.0009202 epoch=50 | loss=0.00 #%% # 预测验证预览 y_pred = model.forward(X).detach().cpu().numpy().squeeze() fig = go.Figure() fig.add_trace(go.Scatter(y=y_true, name='y_true')) fig.add_trace(go.Scatter(y=y_pred, name='y_pred')) fig.show() 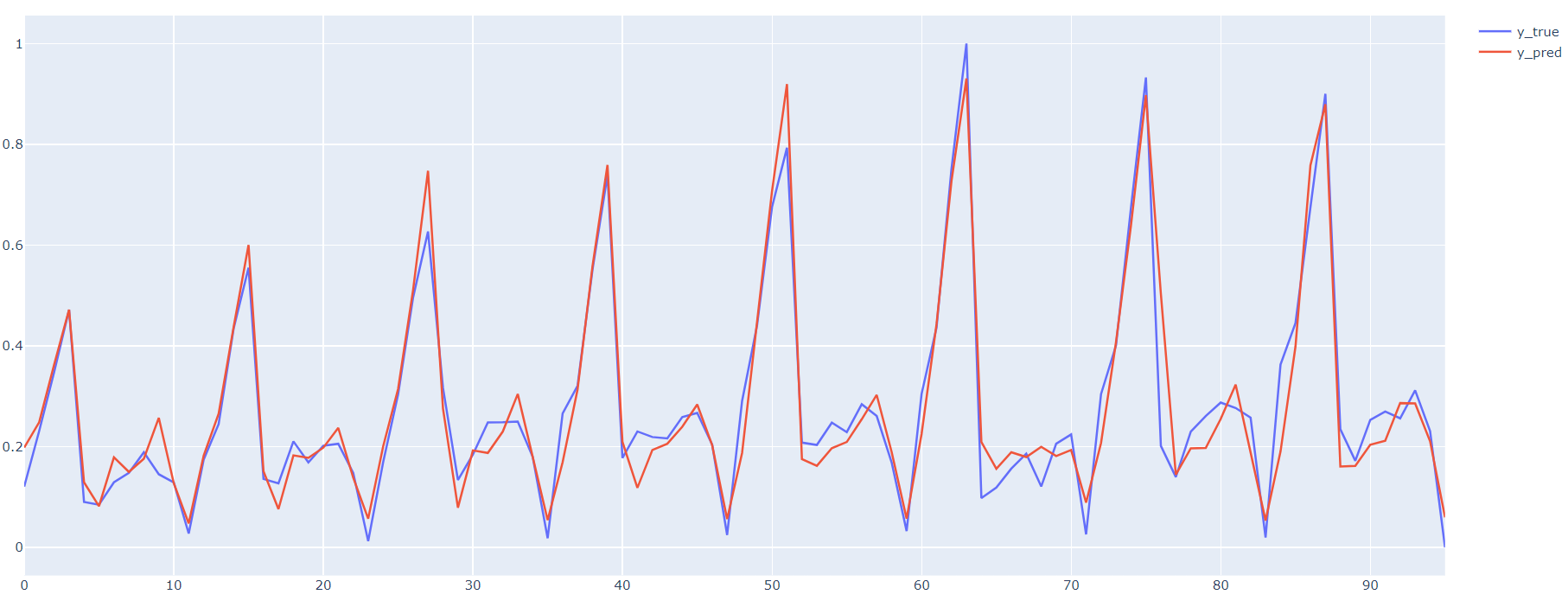
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/207017.html原文链接:https://javaforall.net


