
1.概述
Kafka的使用场景非常广泛,一些实时流数据业务场景,均依赖Kafka来做数据分流。而在分布式应用场景中,数据迁移是一个比较常见的问题。关于Kafka集群数据如何迁移,今天叶秋学长将为大家详细介绍。
2.内容
本篇博客为大家介绍两种迁移场景,分别是同集群数据迁移、跨集群数据迁移。如下图所示:
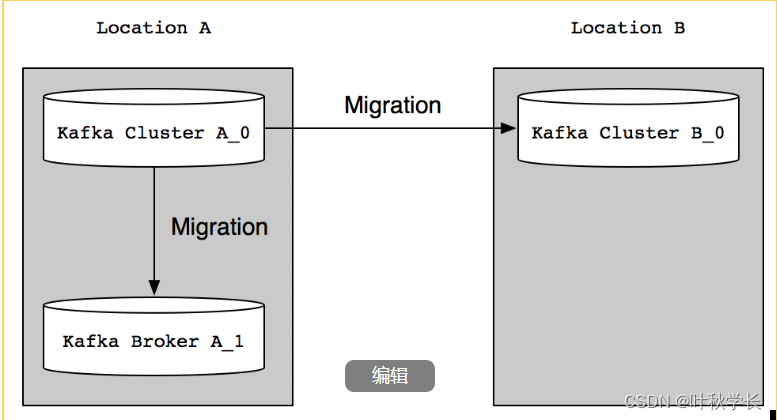

2.1 同集群迁移
同集群之间数据迁移,比如在已有的集群中新增了一个Broker节点,此时需要将原来集群中已有的Topic的数据迁移部分到新的集群中,缓解集群压力。
将新的节点添加到Kafka集群很简单,只需为它们分配一个唯一的Broker ID,并在新服务器上启动Kafka。但是,这些新服务器节点不会自动分配任何数据分区,因此除非将分区移动到新增的节点,否则在创建新Topic之前新节点不会执行任何操作。因此,通常在将新服务器节点添加到Kafka集群时,需要将一些现有数据迁移到这些新的节点。
迁移数据的过程是手动启动的,执行过程是完全自动化的。在Kafka后台服务中,Kafka将添加新服务器作为其正在迁移的分区的Follower,并允许新增节点完全复制该分区中的现有数据。当新服务器节点完全复制此分区的内容并加入同步副本(ISR)时,其中一个现有副本将删除其分区的数据。
Kafka系统提供了一个分区重新分配工具(kafka-reassign-partitions.sh),该工具可用于在Broker之间迁移分区。理想情况下&#x
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/207594.html原文链接:https://javaforall.net


