
原文地址:http://foio.github.io/sizzle-research/
什么是sizzle?下面时官方的一段解释。
A pure-javascript CSS selector engine × Standalone(no dependencies) × Competitive performance × Only 4kB with gzipped × Easy to use × Css3 support × Bla bla …… 其实说白了,sizzle就是一个很给力的选择器解析引擎。
我们为什么需要sizzle呢?其实对现代浏览器来说,document.querySelectorAll就可以解决一切。比如zeptoJs就是用querySelectorAll进行选择器解析的,因为移动端所有浏览器都支撑querySelectorAll。但是对于低版本的IE(<=8)浏览器,不仅不支持querySelectorAll,连getElementById都有bug,因此自己用浏览器原生API解析选择器简直难上加难。好在sizzle引擎帮我们处理了一切。知其然,更要知其所以然。下面让我们看看sizzle引擎内部时如何实现的。
sizzle解析器的主要有以下几个工作步骤。
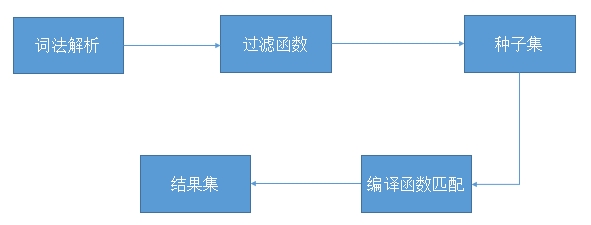

接下来我们就依次解析。为了简单,我们在接下来的文章中都使用选择器div input[name=ttt]作为例子。
1.词法分析
词法分析是指我们将文本代码解析为一个个记号(token),以便后续语法分析使用。
(1) sizzle的token种类
css选择器的词法分析相对较为简单,不用通过lex等专业工具,简单的正则表达式就搞定了。下面依次是用于切分分组,层级关系,以及单个元素的正则表达式。
分组(,):/^[\x20\t\r\n\f]*,[\x20\t\r\n\f]*/
层级关系( >+~):/^[\x20\t\r\n\f]*([>+~]|[\x20\t\r\n\f])[\x20\t\r\n\f]*/
单个元素处理:
var characterEncoding = "(?:\\\\.|[\\w-]|[^\\x00-\\xa0])+"
var ID = new RegExp("^#(" + characterEncoding + ")")
var TAG = new RegExp( "^(" + characterEncoding.replace( "w", "w*" ) + ")" )
var Class = new RegExp( "^\\.(" + characterEncoding + ")" )
(2)从左到右扫描生产token集合
用正则表达式切分出token的过程,如下代码所示。基本原理就是从左到右扫描,用正则切分。
//分组
var rcomma = /^[\x20\t\r\n\f]*,[\x20\t\r\n\f]*/;
//层级
var rcombinators =
/^[\x20\t\r\n\f]*([>+~]|[\x20\t\r\n\f])[\x20\t\r\n\f]*/
//选择器
var TAG = /^((?:\\.|[\w*-]|[^\x00-\xa0])+)/;
var matchExpr = {
CLASS: /^\.((?:\\.|[\w-]|[^\x00-\xa0])+)/,
TAG: /^((?:\\.|[\w*-]|[^\x00-\xa0])+)/
};
//扫描
while (selector) {
//分组
if (match = rcomma.exec(selector)) {
selector = selector.slice(match[0].length)
groups.push((tokens = []));
}
//层级关系
if ((match = rcombinators.exec(selector))) {
matched = match.shift();
tokens.push({
value: matched,
type: match[0].replace(rtrim, " ")
});
selector = selector.slice(matched.length);
}
//选择器
for (type in matchExpr) {
if ((match = matchExpr[type].exec(selector))) {
matched = match.shift();
tokens.push({
value: matched,
type: type,
matches: match
});
selector = selector.slice(matched.length);
}
}
}
最终生成的token集合如下:
{
matches: ["div"],type: "TAG",value: "div“ }, {matches:[“”], type: " ", value: " "}, {matches: ["input"], type: "TAG", value: "input"}, {matches: ["name"], type: "ATTR", value: "[name=ttt]"}
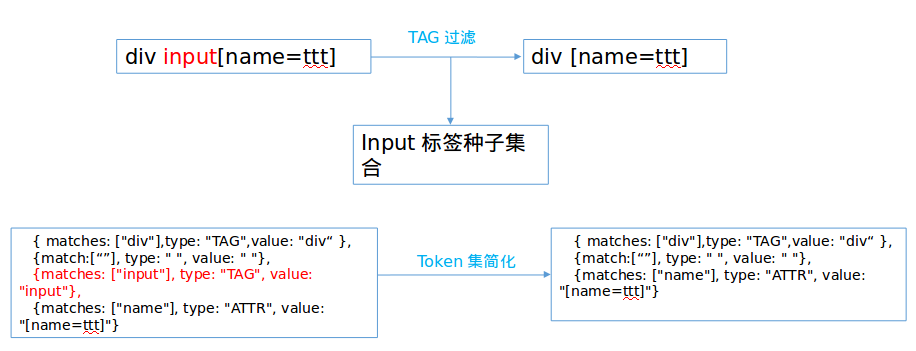
2.过滤函数
过滤函数用于从浏览器dom模型中找到基本符合css选择器的种子集,sizzle针对每一种token都实现一个过滤函数,如下代码所示:
//各种类型的token的过滤器,全部返回闭包函数
Expr.filter = {
ATTR : function (name, operator, check) {
return closure}
CHILD : function (type, what, argument, first, last) {
return closure}
CLASS : function (className) {
return closure}
ID : function (id) {
return closure}
PSEUDO : function (pseudo, argument) {
return closure}
TAG : function (nodeNameSelector) {
return function(elem) {
return elem.nodeName && elem.nodeName.toLowerCase() === nodeNameSelector;
};
}
}
通过部分过滤函数,我们可以初步得到符合条件的种子集合。如下图
3.编译函数
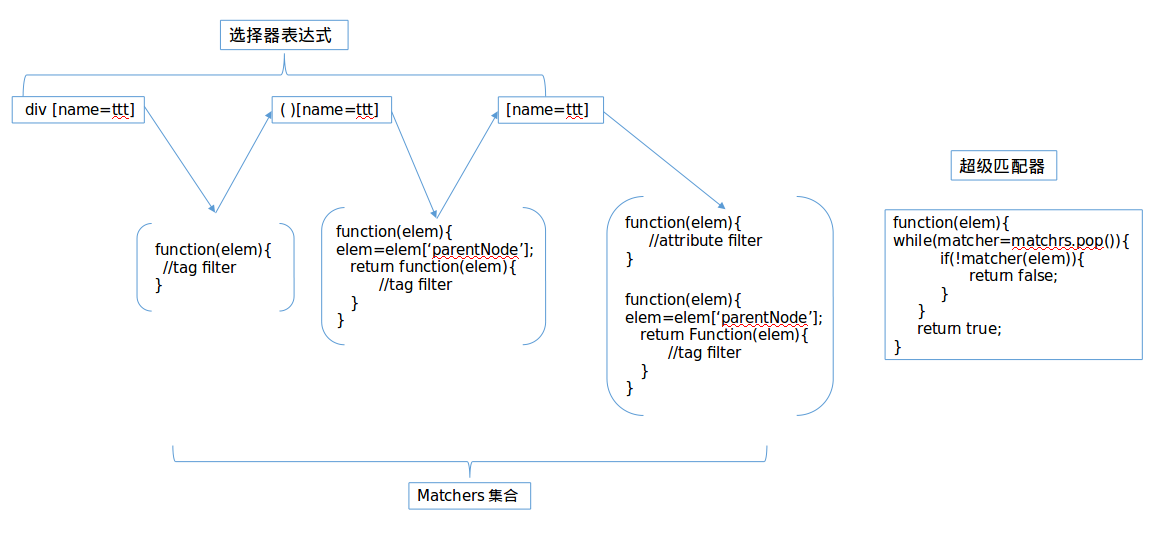
其实sizzle引擎最难的地方就在编译函数。为什么叫做编译呢?抽象的讲,把高级规则转换成底层实现就叫编译;比如高级语言到机器语言的过程就是编译。同样把抽象的css选择语法转变成具体的匹配函数的过程也是编译。

编译的过程还是比较复杂的,其实就是从左到右扫描css选择表达式,并使用与当前token对应的过滤函组合成最终的超级匹配函数。扫描编译的核心步骤是:
(1)遇到关系token(+> ~)则依次出栈并根据层级规则合并栈中函数
(2)其他情况将当前token对应的处理函数压入栈中
(3)选择器表达式结束后依次出栈并合并栈中函数
很难说清楚,高手常常说一图胜千言,我也把扫描编译css选择表达式div [name=ttt]的过程做成图,希望能够讲清楚。
现在假设我们已经通过编译获得了最终的超级匹配函数。那么从种子集中找到结果集就比较简单了。
for item in seed
if(superMatcher(item )){
resultSet.push(item);
}
return resultSet;
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/208453.html原文链接:https://javaforall.net


