
目录
注:本文为总结性文章,应该算是非原创,是在阅读了其他博主的文章的基础上总结的,感觉就是一个多标签分类学习的系统性整理,以便后续再学习查阅使用,有一些细节的实现也需要再找相应的代码或者资料学习。所有参考的文章都在最后的参考部分。
分类一般分为三种情况:二分类、多分类和多标签分类。多标签分类比较直观的理解是,一个样本可以同时拥有几个类别标签,比如一首歌的标签可以是流行、轻快,一部电影的标签可以是动作、喜剧、搞笑,一本书的标签可以是经典、文学等,这都是多标签分类的情况。多标签分类的一个重要特点是样本的所有标签是不具有排他性的。
在阅读了一篇类似综述总结的博客后,做了以下总结,主要是实现多标签分类的几种思想,以及在深度网络的背景下实现多标签分类的几种方法。
实现多标签分类主要有两种思想,一种是转换,一种是直接设计多标签分类的计算,其实基于深度网络的多标签分类也包含在这两种思想里面。
一、两种思想总结
1、问题转换
顾名思义,就是将多标签问题转换成其它问题进行求解,这里其实都是直接转换成分类问题,只不是根据转换思路的不同,又分成了三种不同的问题转换方式,而且这三种转换方式都在scikit-multilearn里面有实现。
(1)二元关联
其实这个算法非常好理解,针对每一个标签都训练一个分类器,然后用所有的分类器对样本进行预测,样本的预测标签就是所有分类器预测的标签的集合,这样,针对每一个标签训练一个二分类器就可以了。用sklearn的包的实现示例如下所示:
# 问题转换-二元关联的方法,把每一个标签当做一个二元分类来计算 from skmultilearn.problem_transform import BinaryRelevance from sklearn.naive_bayes import GaussianNB from sklearn.metrics import accuracy_score classifier_br = BinaryRelevance(GaussianNB()) classifier_br.fit(x_train, y_train) predictions_br = classifier_br.predict(x_test) acc_br = accuracy_score(y_test, predictions_br)(2)分类器链
这个方式也是比较好理解的,它在二元关联的基础上加上了标签的排序,在每次预测当前标签时,不仅要考虑特征数据,也要考虑这个标签的前一个标签,具体是怎么对标签进行排序,以及如何考虑前一个标签的,还需要看源码了解细节。下面是使用示例:
# 问题转换-分类器链的方式,每一次都是一个二分类问题,每一次的分类的输入都是特征数据加上前一个标签。 # 所以就是在二元关联方法的基础上加上了分类器的顺序 from skmultilearn.problem_transform import ClassifierChain classifier_cc = ClassifierChain(GaussianNB()) classifier_cc.fit(x_train, y_train) predictions_cc = classifier_cc.predict(x_test) acc_cc = accuracy_score(y_test, predictions_cc)(3)标签集
英文叫法是Label Powerset,这个做法也是很直观,就是把一个样本的标签集作为一个整体,即当做一个类别标签,如果两个样本的标签集完全一样,那么这两个样本就有被认为有一样的类别标签,就被认为是一类,这就把原来的多标签问题转换成了一个多分类问题。不过这个方法有个问题就是,两两标签之间可以组合成一个新类,这样当标签很多时,要分的类别会非常多,应该会存在类别不均衡的情况。示例如下:
# 问题转换—标签组分类。将标签一样的样本归为一类,这样就转换成了一个多分类的问题。 from skmultilearn.problem_transform import LabelPowerset classifier_lp = LabelPowerset(GaussianNB()) classifier_lp.fit(x_train, y_train) predictions_lp = classifier_lp.predict(x_test) acc_lp = accuracy_score(y_test, predictions_lp) print(acc_br, acc_cc, acc_lp)2、算法改编
这种方法其实也很直观,就是把标签分类当做一个全新的任务,设计属于这个任务的实现方式,而不是将问题转换成多个相同的问题子集,这个也叫自适应算法。在sklearn中,对分类算法做了改编之后,也可以用于多标签分类,目前支持多标签分类的算法有:决策树, 随机森林,最近的邻居。在深度神经网络中,修改最后一层的输出,也是属于这种思想。下面是sklearn中的多标签算法使用示例,注意,这里有两种使用方式:
from sklearn.datasets import make_multilabel_classification from sklearn import model_selection from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score # 生成数据集 x, y = make_multilabel_classification(n_samples=1000, n_features=5, n_classes=3, n_labels=2) x_train, x_test, y_train, y_test = model_selection.train_test_split(x, y, test_size=0.25, random_state=7) # 方法一,直接使用sklearn支持多分类的分类器,不需要做其它的改变 cls = DecisionTreeClassifier() cls.fit(x_train, y_train) y_pred = cls.predict(x_test) acc = accuracy_score(y_test, y_pred) # 方法二,使用scikit-multilearn这个库里面的分类器 from skmultilearn.adapt import MLkNN cls_mk = MLkNN(k=20) cls_mk.fit(x_train, y_train) y_pred_mk = cls_mk.predict(x_test) acc_mk = accuracy_score(y_test, y_pred_mk) print(acc, acc_mk)二、深度网络多标签分类
当数据量较小的时候,可以使用上面sklearn中比较传统的多标签分类模型,当数据量较多的时候,为了准确性,可以尝试直接使用深度神经网络来做多标签分类,特别是文本分类这种任务。根据看过的一篇文章的总结,目前用深度网络实现多标签分类的方式有三种,分别如下:
(1)比较直接的在最后加上一层全连接,在计算概率的时候用sigmod计算,即将每一个标签当做一个二分类问题,loss函数则为cross_entropy。
(2)在网络的最后一层,针对每一个标签,使用一个全连接层,然后在每个标签上就是一个二分类问题,这个其实跟第一种方式很像,只是第一种方法中,每个标签公用了最后一层全连接层。
(3)第三种方式就是,将任务当做是一个标签生成的过程,那这样就可以使用一个seq2seq的框架来完成了。前面使用一个encoder结构来对输入的特征数据编码, 然后在经过decoder进行解码最终生成多个标签,这个就跟机器翻译是一个思路,所以在最终生成标签的时候,会有标签的依赖关系。
总结下来,多标签分类网络对于分类网络,修改的大概就是下面三点:
a、转换成二分类的就是用sigmod的计算概率值
b、根据计算的概率值和任务,使用相应的cross_entropy_loss计算
c、网络结构的变化,比如方式(2)。
关于这一部分的具体示例和代码,可以参考下面这篇总结文章,总结得非常全面:多标签文本分类介绍,以及对比训练
三、多标签分类评价指标
参考之前写的分类评价指标:分类问题中的各种评价指标


四、多标签分类的损失函数
对于分类问题,一般都用交叉熵来计算样本的损失,而loss的计算又依赖于最后一层的概率输出,所以总结下来如下:
1、二分类和多分类
(1)如果只是输出一个概率,来表示样本属于某类的概率是多少,那么这个时候,最后的概率输出则用sigmod(wx+b),这个使用的是sigmod_cross_entropy_loss,计算公式如下:
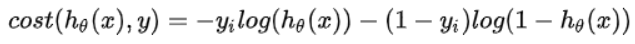
例如:判断一个样本是不是猫,输入的是一个正样本,也就是是猫的样本,那么,输入样本可以表示为{x = feature,y = 1},模型的输出就是一个[在0到1之间的一个概率值p,这个概率就是通过sigmod计算出来,然后再根据样本的真实标签是0或者1(也就是上面公式中的y_i),和这个概率值p(对应公式中的h_theat(x)),根据上面的公式,计算该样本的loss。
(2)如果对于一个二分类问题,想要输出一个二维的向量,一维表示是这个类别的概率是多少,一个表示不是的概率是多少,那么这个时候最后一层输出的概率就要用softmax来计算,公式如下:
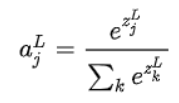
针对这种情况,就要用softmax_cross_entropy来计算loss,计算公式就是常规的交叉熵的计算公式,公式如下:
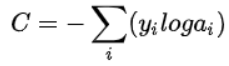
例如: 判断一个样本是不是猫,输入的是一个正样本,也就是是猫的样本,那么,输入样本也可以表示为{x = feature,y = [1, 0]},如果是负样本,则相应的y=[0, 1],模型的输出则为[p, 1-p],这个时候,样本的loss就根据上面的公式计算了。感觉这个例子比较无聊,比较没有意义,下面可以换个例子。
加入判断一个样本是猫还是狗,y=[1, 0]表示样本是猫,y=[0, 1]表示样本时是狗,模型的输出根据公式计算也会是[p, 1-p],后面的loss计算也是上面的公式
(3)对于一个多分类问题,比如判断是猫、狗或者人,是一个三分类问题,每个类别分类对应的y就是[1, 0, 0]、[0, 1, 0]、[0, 0, 1],最终样本的概率输出,以及loss计算也就是(2)中的两个公式。
2、多标签分类
对于多标签分类,概率输出和loss计算也是遵循上面的计算原则。对于多标签分类的时候,因为标签之间不互斥,所以只需要确定每个标签存不存在即可,所以最终每个标签可以当做一个二分类问题来看,那么在相应的标签上的概率和loss计算则可以沿用二分类的计算方法。
例如,需要预测的标签有5个,对于给定的样本{x, y=[y1, y2, y3, y4, y5]},模型的输出为y=[p1, p2, p3, p4, p5],那么这个里面的p值就是直接使用sigmod计算得来的,每个标签的loss也用sigmod_cross_entropy计算,公式如下:
这里有5个标签,每一个标签要分别将对应的yi和预测的pi带入到上面的式子计算一个loss,然后5个标签的loss平均,即为给定样本的loss。具体计算可以参考这里:多标签分类要用什么损失函数? – tik boa
五、参考文章
1、多标签(multi-label)数据的学习问题,常用的分类器或者分类策略有哪些? – 景略集智
2、多标签分类(multi-label classification)综述
3、sklearn 多分类多标签算法
4、多标签文本分类介绍,以及对比训练 – HelloNLP的文章
5、多标签分类要用什么损失函数? – tik boa
6、一个提供多标签分类的数据集:Mulan: A Java Library for Multi-Label Learning
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/209291.html原文链接:https://javaforall.net


