
#使用lambda >>> print map(lambda x: x % 2, range(7)) [0, 1, 0, 1, 0, 1, 0]- 1
- 2
- 3


#使用列表解析 >>> print [x % 2 for x in range(7)] [0, 1, 0, 1, 0, 1, 0]- 1
- 2
- 3
一个seq时,可以使用filter()函数代替,那什么情况不能代替呢?

>>> print map(lambda x , y : x y, [2,4,6],[3,2,1]) [8, 16, 6]- 1
- 2
如果上面我们不使用map函数,就只能使用for循环,依次对每个位置的元素调用该函数去执行。还可以使返回值是一个元组。如:
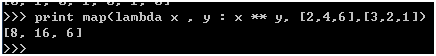
>>> print map(lambda x , y : (x y, x + y), [2,4,6],[3,2,1]) [(8, 5), (16, 6), (6, 7)]- 1
- 2
当func函数时None时,这就同zip()函数了,并且zip()开始取代这个了,目的是将多个列表相同位置的元素归并到一个元组。如:

>>> print map(None, [2,4,6],[3,2,1]) [(2, 3), (4, 2), (6, 1)]- 1
- 2
3、使用map()函数可以实现将其他类型的数转换成list,但是这种转换也是有类型限制的,具体什么类型限制,在以后的学习中慢慢摸索吧。这里给出几个能转换的例子:
*将元组转换成list* >>> map(int, (1,2,3)) [1, 2, 3] *将字符串转换成list* >>> map(int, '1234') [1, 2, 3, 4] *提取字典的key,并将结果存放在一个list中* >>> map(int, {
1:2,2:3,3:4}) [1, 2, 3] *字符串转换成元组,并将结果以列表的形式返回* >>> map(tuple, 'agdf') [('a',), ('g',), ('d',), ('f',)] #将小写转成大写 def u_to_l (s): return s.upper() print map(u_to_l,'asdfd')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
1、对可迭代函数‘iterable’中的每一个元素应用‘function’方法,将结果作为list返回。
来个例子:
>>> def add100(x):
… return x+100
…
>>> hh = [11,22,33]
>>> map(add100,hh)
[111, 122, 133]
就像文档中说的:对hh中的元素做了add100,返回了结果的list。
2、如果给出了额外的可迭代参数,则对每个可迭代参数中的元素‘并行’的应用‘function’。(翻译的不好,这里的关键是‘并行’)
>>> def abc(a, b, c):
… return a*10000 + b*100 + c
…
>>> list1 = [11,22,33]
>>> list2 = [44,55,66]
>>> list3 = [77,88,99]
>>> map(abc,list1,list2,list3)
[, , ]
看到并行的效果了吧!在每个list中,取出了下标相同的元素,执行了abc()。
3、如果’function’给出的是‘None’,自动假定一个‘identity’函数(这个‘identity’不知道怎么解释,看例子吧)
>>> list1 = [11,22,33]
>>> map(None,list1)
[11, 22, 33]
>>> list1 = [11,22,33]
>>> list2 = [44,55,66]
>>> list3 = [77,88,99]
>>> map(None,list1,list2,list3)
[(11, 44, 77), (22, 55, 88), (33, 66, 99)]
转自http://blog.csdn.net/seetheworld518/article/details/
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/209300.html原文链接:https://javaforall.net


