
码字不易,转载请注明出处喔:https://blog.csdn.net/newchenxf/article/details/
这又是一道面试题。所以这里先给一些结论,然后分析代码。
1. 总结
LinkedHashMap继承HashMap,所以拥有绝大部分HashMap的特性(更多细节见:https://blog.csdn.net/newchenxf/article/details/)。
这包括,存储用数组,数组大小动态扩大。线程不安全,key可以为null等等。
1.1 关键区别
HashMap因为index是随机生成的,所以每次put,存放的位置是无序的。(虽然节点类有next,但这个单链表仅是在同一个index的坑位,是串联的^^)
LinkedHashMap通过额外维护一个双向链表,来保证迭代顺序。所以它是有序的。即,它是有办法知道谁先入,谁后入的。当然,为此也增加了时间/空间的开销。
2. 细化分析
2.1 额外增加的双向链表定义
/ * LinkedEntry adds nxt/prv double-links to plain HashMapEntry. */ static class LinkedEntry<K, V> extends HashMapEntry<K, V> {
LinkedEntry<K, V> nxt; LinkedEntry<K, V> prv; / Create the header entry */ LinkedEntry() {
super(null, null, 0, null); nxt = prv = this; } / Create a normal entry */ LinkedEntry(K key, V value, int hash, HashMapEntry<K, V> next, LinkedEntry<K, V> nxt, LinkedEntry<K, V> prv) {
super(key, value, hash, next); this.nxt = nxt; this.prv = prv; } } 就是继承HashMap的内部类HashMapEntry,然后新增了2个指针nxt & prv,指向前后节点,所以,它变成了一个双向链表的节点类。
2.2 额外增加的成员变量
相比HashMap,额外加了2个成员变量。分别是 双向链表 头节点header (在LinkedHashMap构造函数初始化)和 标志位accessOrder (值为true时,表示按照访问顺序迭代;值为false时,表示按照插入顺序迭代)。
定义如下:
// 双向链表的表头元素 transient LinkedEntry<K, V> header; //true表示按照访问顺序迭代,false时表示按照插入顺序, 默认false private final boolean accessOrder; 2.3 数据插入
LinkedHashMap倒是重写了addNewEntry。我们来看一下这个函数的实现。
@Override void addNewEntry(K key, V value, int hash, int index) {
LinkedEntry<K, V> header = this.header; //....省略部分不重要代码 // Create new entry, link it on to list, and put it into table LinkedEntry<K, V> oldTail = header.prv; LinkedEntry<K, V> newTail = new LinkedEntry<K,V>( key, value, hash, table[index], header, oldTail); table[index] = oldTail.nxt = header.prv = newTail; } 很简单,就是一些指针的方向转换。我画个图就明白了。
第一次添加元素:
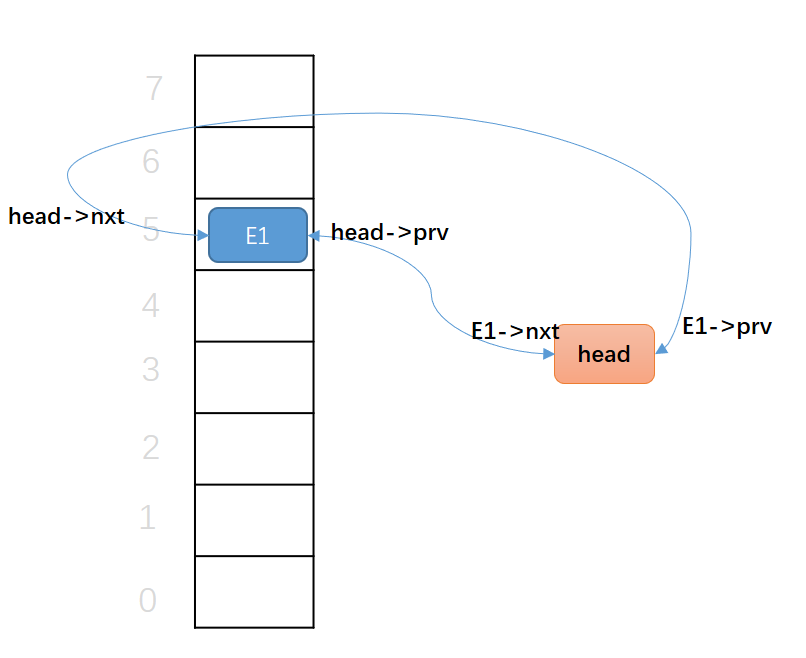

这时候,唯一的元素E1和head互相连着。你能找到我,我也能找到你,如胶似漆。
第二次添加元素:
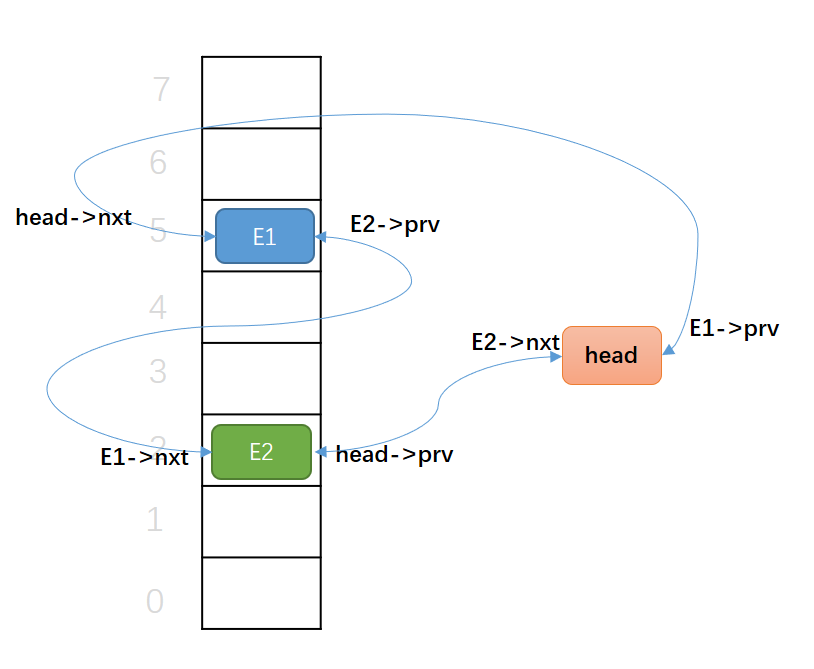
这时候,形成了三角恋,E1连着新同学E2, E2连着head,但E1也同时连着head。剪不断,理还乱。
第三次添加元素:
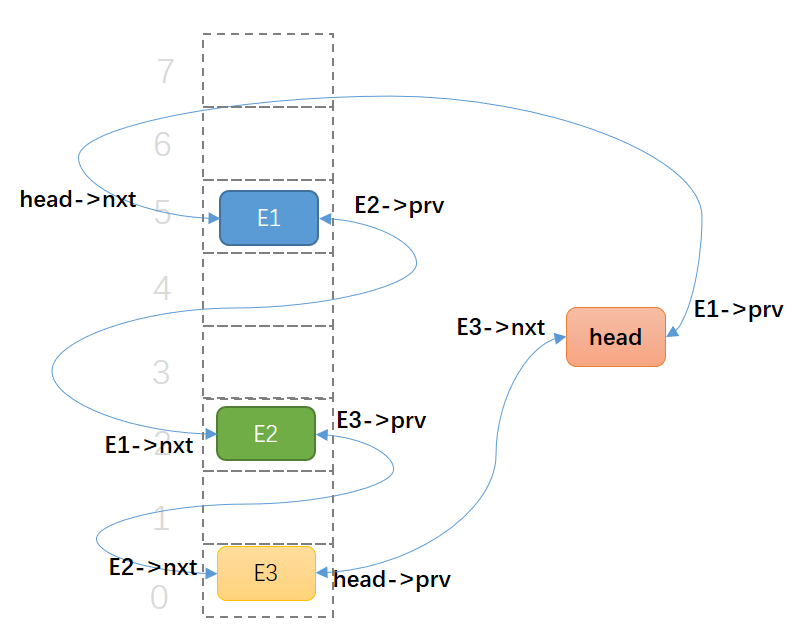
这时候,是四角恋了,关系更复杂。
最初的那个男人head,和最新来的同学E3,以及最早来的同学E1,都保持着联系。都不知道要说他专情,还是喜新厌旧哩^^
2.4 读取元素
@Override public V get(Object key) {
//省略部分代码 int hash = Collections.secondaryHash(key); HashMapEntry<K, V>[] tab = table; //和HashMap一样,根据hash值生成Index,即(hash & (tab.length - 1)),然后读取节点。 for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)]; e != null; e = e.next) {
K eKey = e.key; if (eKey == key || (e.hash == hash && key.equals(eKey))) {
//如果accessOrder为true,则被读取的节点,要变成链表的尾巴 if (accessOrder) makeTail((LinkedEntry<K, V>) e); return e.value; } } return null; } 从代码可知,读取的方式,和HashMap是一样的。无非是中间加个额外的事情,是,如果accessOrder为true,则被读取的节点,要变成链表的尾巴(makeTail)。
makeTail是如何实现呢?
private void makeTail(LinkedEntry<K, V> e) {
// Unlink e e.prv.nxt = e.nxt; e.nxt.prv = e.prv; // Relink e as tail LinkedEntry<K, V> header = this.header; LinkedEntry<K, V> oldTail = header.prv; e.nxt = header; e.prv = oldTail; oldTail.nxt = header.prv = e; modCount++; } 简单的很,就是把header.prv改成当前节点。
通常认为,header的nxt是第一个节点,header的prv是最后一个节点。
2.5 链表的作用
看完插入数据和读取数据,发现双线链表,仅仅是生成,并么有什么用途?那可以用到哪里呢?
它用途确实不明显!倒是有一个需求,是要判断哪个entry是最早的来的。比如上面画图的E1。
public Entry<K, V> eldest() {
LinkedEntry<K, V> eldest = header.nxt; return eldest != header ? eldest : null; } 2.6 再次小结
所以说,一般HashMap已经足够了,除非你有强需求,需要知道数据顺序,想要了解谁最早插入,才用开销大一些的LinkedHashMap!
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/209360.html原文链接:https://javaforall.net

![51单片机控制步进电机-电路连接[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
