
1.合并排序
排序算法是对一组数进行顺序排序或者逆序排序,而合并排序就是排序算法的一种。合并排序用到了分治策略实现对元素进行排序。
合并排序的基本思想:把待排序的n个元素分解成n组,也就是每组一个元素;之后对分好的组进行两两合并(无配对的则不操作),以此类推。
以序列{8, 3, 2, 6, 7, 1, 5, 4}为例,排序过程如下:
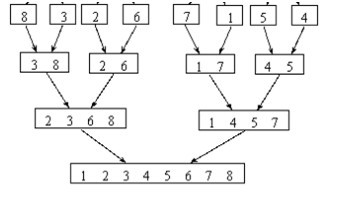

图片来源
合并排序又叫做2-路归并排序,是因为它每次都是两两归并。
/ * 合并src[left:mid] src[mid+1:right] 到dest[left:right] * @param src: 源数组 * @param dest: 目的数组 * @param left: 数组起始索引 * @param mid: 源数组的中间索引 * @param right: 目的数组的结束索引 */ template
void merge(Type src[], Type dest[], int left, int mid, int right) { //指针 int i = left, j = mid + 1, k = left; //归并 while ((i <= mid) && (j <= right)) { if (src[i] <= src[j]) dest[k++] = src[i++]; else dest[k++] = src[j++]; } //把剩下的数组元素拷贝到目的数组 if (i > mid) for (int q = j; q <= right; q++) dest[k++] = src[q]; else for (int q = i; q <= mid; q++) dest[k++] = src[q]; }
merge函数用于把src[left:mid] 和src[mid + 1: right]归并到dest的对应位置。其思路如下
- 设置两个索引变量i和j保存当前指向的src[left:mid] 和src[mid + 1: right]的索引;
- 每次从i 和j 所指向的src[i] src[j]中取一个小值依次放到dest的对应位置,然后这个索引加一;
- 重复2步骤直至遍历完短数组;
- 把剩余的值拼接到dest数组中。
/ * src[left:right]复制到dest[left:right] * @param src: 源数组 * @param dest: 目的数组 * @param left: 起始索引 * @param right: 结束索引 */ template
void copy(Type src[], Type dest[], int left, int right) { while (left < right) { dest[left] = src[left]; left++; } }
copy的作用就是数组复制。
/ * 用于合并排序好的相邻数组段 */ template
void mergePass(Type x[], Type y[], int step, int n) { int i = 0; while (i <= n - 2 * step) { merge(x, y, i, i + step - 1, i + 2 * step - 1); i = i + 2 * step; } if (i + step < n) merge(x, y, i, i + step - 1, n - 1); else for (int j = i; j < n ; j++) y[j] = x[j]; }
mergePass函数主要用于合并排序好的相邻数组,
当step为1,时,此时数组被分成了n份,mergePass的while就是把上面的单个元素两两合并;
当step为2,时,则对最多为2个元素的子数组进行两两合并。
以此类推
在之后还有一个判断:i + step < n,这里举例子来说明:
比如此时进行到了第二次归并,即step = 2, 元素如下: x = {1,2} {2, 3}, {1, 1} {4} i = 0时,合并的是x[0: 1]和x[2:3],之后i = 0 + 2 * 2 = 4; i = 4,时,得到i <= 7 - 2 * 2 = 3 不成立,所以不再循环。 虽然循环不成立,但是可以看到,{1, 1} {4}还是满足i + step < n的,所以这里又加了最后一个归并。 而当x = {1, 2} {2, 3} {4},step=2的情况下则会直接进行复制。从上面的举例可以看出,赋予step递增的值,则可以实现归并排序。
template
void mergeSort(Type a[], int n) { Type* temp = new Type[n]; int step = 1; while (step < n) { //合并到数组temp mergePass(a, temp, step, n); step += step; //合并到数组a mergePass(temp, a, step, n); step += step; } delete[] temp; }
在mergeSort函数中,调用mergePass来实现归并操作。
接着测试一下:
int main() { int a[] = {1, 4, 2, 6, 7, 5, 3}; int len = sizeof(a) / sizeof(a[0]); //合并排序 mergeSort(a, len); for (int i = 0; i < len; i++) cout << a[i] << " "; cout << endl; return 0; }2.自然合并排序
自然合并排序是上述所说的合并排序算法的一个变形。之前说过,合并排序是从一个元素开始两两归并的,而当一个组内只有一个元素时,能够保证它是排序好的。基于上面的原理,给定一个数组,一般都会存在多个长度大于1的已自然排好序的子数组段。比如对于一个数组{1, 4, 2, 6, 7, 5, 3, 2}。自然排序的子数组段为{1, 4} {2, 6, 7} {5} {3} {2};第一次排序可以得到{1, 2, 4, 6, 7} { 3, 5} {2};第二次排序得到{1, 2, 3, 4, 5, 6, 7} {2} ;第三次排序则可以得到递增序列。
上面需要解决的问题就是如何保存每次的子数组段的开始和结束,因为子数组段的大小不是固定的,所以还需要一个数组去维护子数组的边界。
template
void mergeSort(Type a[], int len) { if (len == 0) return; //保存子数组段的索引 vector
indices(len + 1); indices[0] = -1; //indices中的真实个数 int number = get_order(a, len, indices); Type* temp = new Type[len]; number = indices.size(); //自然归并排序 while (number != 2) { int index = 0; for (int i = 0; i + 2 < number; i += 2) { merge(a, temp, indices[i] + 1, indices[i + 1], indices[i + 2]); } //回写到数组a for (int i = 0; i < len; i++) a[i] = temp[i]; number = get_order(a, len, indices); } delete[] temp; }
新的mergeSort函数用到了子数组段,其中维护了indices数组来存储边界,
首先可以看到indices的大小为len + 1,这是最坏情况下的indices的最大值,当数组完全逆序的时候,比如要把{5, 4, 3, 2, 1}排序成{1, 2, 3, 4, 5}时,我们可以一眼看出只需要完全翻转就可以了,不过程序则不知道,按照之前的步骤来说,以上分成了{5} {4} {3} {2} {1}共5个,再加上一开始的-1,所以最大数组长度设为了len + 1。
第一个元素为-1,主要是为了应对之后的排序。以{1, 4, 2, 6, 7, 5, 3, 2}为例子。自然排序的子数组段为{1, 4} {2, 6, 7} {5} {3} {2};那么indices的值为{-1, 1, 4, 5, 6, 7}。那么需要a[-1 + 1: 1]和a[1 + 1, 4]进行归并,a[4 +1: 5]和a[5 + 1:6]归并...
每一次的循环都会重新获取排序好的子数组段(其实可以从之前得到的)。
/ * 获取数组a的自然排好序的子数组段,返回结束索引 * @param a: 数组 * @param len: 数组a的长度 * @param indices: 排序好的结束索引数组 需要确保长度足够 * @return: 返回indices真正的长度 */ template
int get_order(Type a[], int len, vector
& indices) { int index = 1; int i = 1; while (index < len) { //记录起点 if (a[index] < a[index - 1]) { indices[i++] = index - 1; } index++; } indices[i++] = len - 1; return i; }
根据mergeSort和get_order而得到的indices数组来说,必定存在的就是-1和最后一个元素的索引,所以当indices的实际个数为2的时候,表示排序结束。
3.测试
本测试在leetcode上执行,题目为:排序数组
普通归并排序执行:
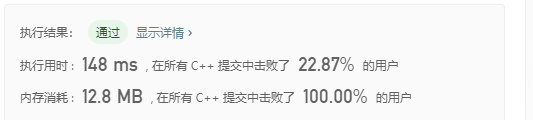
自然归并排序执行:

可以看到,自然归并排序的执行用时要小于普通归并排序,不过内存消耗略微增加。
4.参考
- 书籍《计算机算法设计与分析 王晓东》
- 归并排序三种实现方法(递归、非递归和自然合并排序)
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/209509.html原文链接:https://javaforall.net


