
Retinex图像增强算法
一、单尺度SSR(Single Scale Retinex)理论
Retinex理论始于Land和McCann于20世纪60年代作出的一系列贡献,其基本思想是人感知到某点的颜色和亮度并不仅仅取决于该点进入人眼的绝对光线,还和其周围的颜色和亮度有关。Retinex这个词是由视网膜(Retina)和大脑皮层(Cortex)两个词组合构成的.Land之所以设计这个词,是为了表明他不清楚视觉系统的特性究竟取决于此两个生理结构中的哪一个,抑或是与两者都有关系。
Land的Retinex模型是建立在以下的基础之上的:
- 真实世界是无颜色的,我们所感知的颜色是光与物质的相互作用的结果。我们见到的水是无色的,但是水膜—肥皂膜却是显现五彩缤纷,那是薄膜表面光干涉的结果;
- 每一颜色区域由给定波长的红、绿、蓝三原色构成的;
- 三原色决定了每个单位区域的颜色。
Retinex 理论的基本内容
- 物体的颜色是由物体对长波(红)、中波(绿)和短波(蓝)光线的反射能力决定的,而不是由反射光强度的绝对值决定的;
- 物体的色彩不受光照非均性的影响,具有一致性,
- 即Retinex理论是以色感一致性(颜色恒常性)为基础的。
二、Retinex理论的理解
Retinex理论,与降噪类似,该理论的关键就是合理地假设了图像的构成。如果将观察者看到的图像看成是一幅带有乘性噪声的图像,那么入射光的分量就是一种乘性的,相对均匀,且变换缓慢的噪声。Retinex算法所做的就是合理地估计图像中各个位置的噪声,并除去它。
(2) 归一化去除加性分量 r ′ = r max ( r ) r’ = \frac{r}{\max (r)} r′=max(r)r;
(3) 对步骤3得到的结果求指数,反变换到实数域 R = exp ( r ⋅ log 255 ) R = \exp(r · \log 255) R=exp(r⋅log255)。
- 计算流程如下:
L o g ( R ( x , y ) ) = ( L o g ( I ( x , y ) ) − L o g ( I ( x , y ) ∗ G ( x , y ) ) ) ( ∗ 乘 ) ( 1 − 1 ) \rm Log(R(x,y)) =(Log(I(x,y))-Log(I(x,y)* G(x,y))) (*乘) (1-1) Log(R(x,y))=(Log(I(x,y))−Log(I(x,y)∗G(x,y))) (∗乘) (1−1)
R ( x , y ) = ( V a l u e − M i n ) / ( M a x − M i n ) ∗ ( 255 − 0 ) ( 1 − 2 ) \rm R(x,y) = ( Value – Min ) / (Max – Min) * (255-0) (1-2) R(x,y)=(Value−Min)/(Max−Min)∗(255−0) (1−2)
- 其中:
-
I ( x , y ) I(x,y) I(x,y)代表被观察或照相机接收到的图像信号;
L ( x , y ) L(x,y) L(x,y)代表环境光的照射分量 ;
R ( x , y ) R(x,y) R(x,y)表示携带图像细节信息的目标物体的反射分量 。
L ( x , y ) L(x,y) L(x,y)是不能够求得的,只能近似求出。我们用 I ( x , y ) I(x,y) I(x,y)和一个高斯核的卷积来近似表示 L ( x , y ) L(x,y) L(x,y)。
import numpy as np import cv2 def replaceZeroes(data): min_nonzero = min(data[np.nonzero(data)]) data[data == 0] = min_nonzero return data def SSR(src_img, size): L_blur = cv2.GaussianBlur(src_img, (size, size), 0) img = replaceZeroes(src_img) L_blur = replaceZeroes(L_blur) dst_Img = cv2.log(img/255.0) dst_Lblur = cv2.log(L_blur/255.0) dst_IxL = cv2.multiply(dst_Img,dst_Lblur) log_R = cv2.subtract(dst_Img, dst_IxL) dst_R = cv2.normalize(log_R,None,0,255,cv2.NORM_MINMAX) log_uint8 = cv2.convertScaleAbs(dst_R) return log_uint8 if __name__ == '__main__': img = './gggg/802.png' size = 3 src_img = cv2.imread(img) b_gray, g_gray, r_gray = cv2.split(src_img) b_gray = SSR(b_gray, size) g_gray = SSR(g_gray, size) r_gray = SSR(r_gray, size) result = cv2.merge([b_gray, g_gray, r_gray]) cv2.imshow('img',src_img) cv2.imshow('result',result) cv2.waitKey(0) cv2.destroyAllWindows() 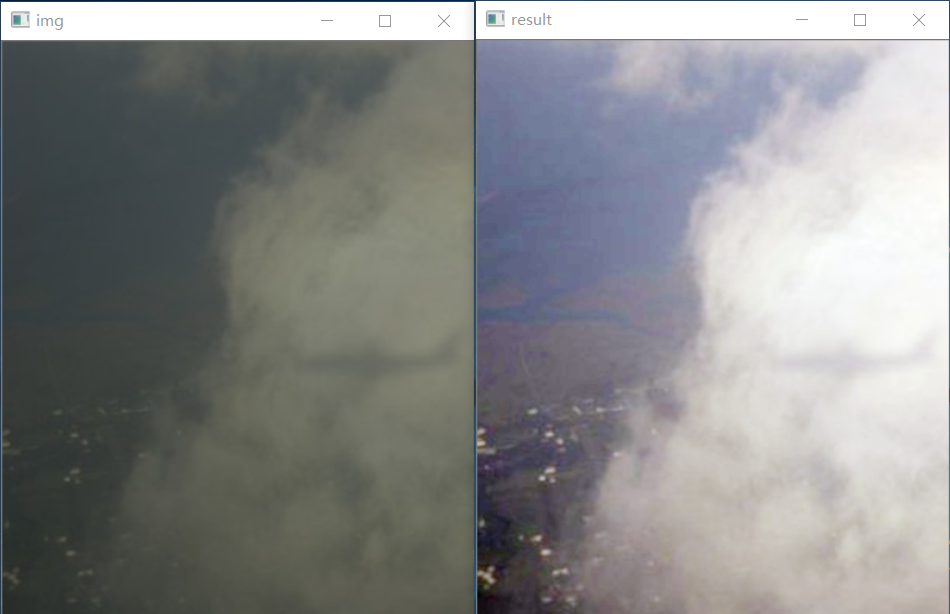

三、多尺度MSR(Multi-Scale Retinex)
MSR是在SSR基础上发展来的,优点是可以同时保持图像高保真度与对图像的动态范围进行压缩的同时,MSR也可实现色彩增强、颜色恒常性、局部动态范围压缩、全局动态范围压缩,也可以用于X光图像增强。最为经典的就是3尺度的,大、中、小,既能实现图像动态范围的压缩,又能保持色感的一致性较好。
-
计算流程
-
(1) 需要对原始图像进行每个尺度的高斯模糊,得到模糊后的图像
L i ( x , y ) L_i(x,y) Li(x,y),其中小标
i i i表示尺度数。
(2) 对每个尺度下进行累加计算
log [ R ( x , y ) ] = log [ R ( x , y ) ] + W e i g h t ( i ) ∗ ( log [ I i ( x , y ) ] − log [ L i ( x , y ) ] ) ; \log[R(x,y)] = \log[R(x,y)] + Weight(i)* ( \log[I_i(x,y)]-\log[L_i(x,y)]); log[R(x,y)]=log[R(x,y)]+Weight(i)∗(log[Ii(x,y)]−log[Li(x,y)]);
其中Weight(i)表示每个尺度对应的权重,要求各尺度权重之和必须为1,经典的取值为等权重。
import numpy as np import cv2 def replaceZeroes(data): min_nonzero = min(data[np.nonzero(data)]) data[data == 0] = min_nonzero return data def MSR(img, scales): weight = 1 / 3.0 scales_size = len(scales) h, w = img.shape[:2] log_R = np.zeros((h, w), dtype=np.float32) for i in range(scales_size): img = replaceZeroes(img) L_blur = cv2.GaussianBlur(img, (scales[i], scales[i]), 0) L_blur = replaceZeroes(L_blur) dst_Img = cv2.log(img/255.0) dst_Lblur = cv2.log(L_blur/255.0) dst_Ixl = cv2.multiply(dst_Img, dst_Lblur) log_R += weight * cv2.subtract(dst_Img, dst_Ixl) dst_R = cv2.normalize(log_R,None, 0, 255, cv2.NORM_MINMAX) log_uint8 = cv2.convertScaleAbs(dst_R) return log_uint8 if __name__ == '__main__': img = './gggg/802.png' scales = [15,101,301] # [3,5,9] #看不出效果有什么差别 src_img = cv2.imread(img) b_gray, g_gray, r_gray = cv2.split(src_img) b_gray = MSR(b_gray, scales) g_gray = MSR(g_gray, scales) r_gray = MSR(r_gray, scales) result = cv2.merge([b_gray, g_gray, r_gray]) cv2.imshow('img',src_img) cv2.imshow('MSR_result',result) cv2.waitKey(0) cv2.destroyAllWindows() 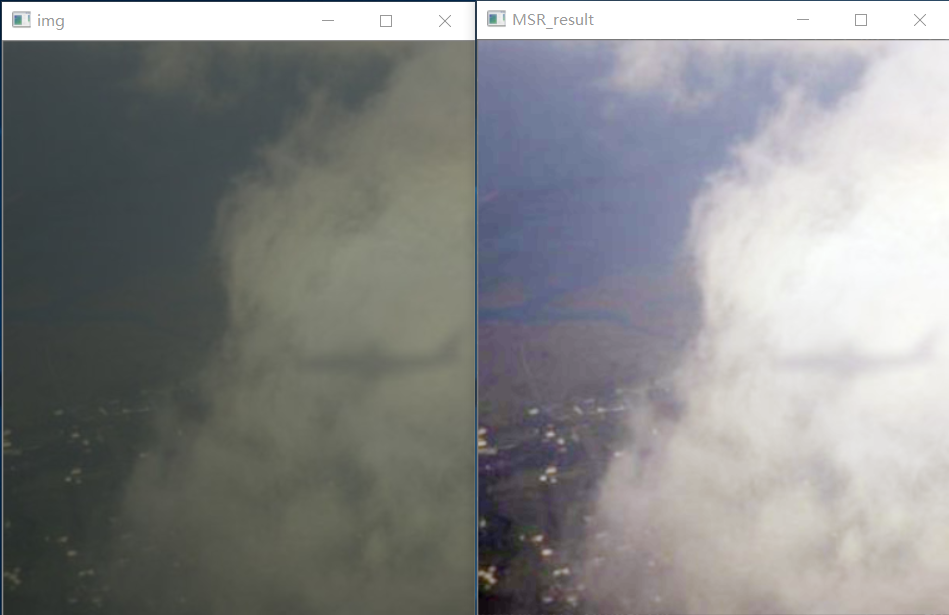
四、MSRCR & MSRCP
由于R是对数域的输出,要转换为数字图像,必须将他们量化为[0,255]的数字图像范畴,关于这个量化的算法,有这极为重要的意义,他的好坏直接决定了最终输出的图像的品质。
目前,有4种方式进行处理:
- 第一种,直接线性量化,在单尺度SSR中采用的就是这种方法。
这种方式,由于Retinex数据处理后的高动态特性,数据分布很广,会出现严重的两极化现象,一般难以获得满意的结果。
- 第二种,就是在经典的MSRCR(Multi-Scale Retinex with Color Restoration)文章《A Multiscale Retinex for Bridging the Gap Between Color Images and the Human Observation of Scenes》中提出的Canonical Gain/set 算法。计算公式如:
R M S R C R i ( x , y ) = G [ R M S R C R i ( x , y ) − b ] R_{MSRCR_i}(x,y) = G[R_{MSRCR_i}(x,y)-b] RMSRCRi(x,y)=G[RMSRCRi(x,y)−b]
其中G和b为经验参数。 - 第三种,实在上述文章中提到的Simplest Color Balance(我简写为SCR)方式,这种方式的处理类似于Photoshop中的自动色阶,他把数据按照一定的百分比去除最小和最大的部分,然后中间的部分重新线性量化到0和255之间。
- 第四种,就是GIMP的Retinex算法,这个可详见 带色彩恢复的多尺度视网膜增强算法(MSRCR)的原理、实现及应用 一文的描述。
还有一种方式,就是大家知道HDR的过程吧,他也是将高动态的数据量化到图像的可视范围,因此可以直接将这类算法应用与这个问题上。我也做了实验,效果似乎一般。
在用第二种或第三种方式处理时,最好还需要有个Color Restoration的过程,因为如果直接对MSR处理的结果进行量化,得到的图像往往整体偏灰度,这是由于原始的彩色值经过log处理后的数据范围就比较小了,这样各通道之间的差异也很小,而之后的线性量化比log曲线要平滑很多,因此整体就丧失了彩色。
C i ( x , y ) = β log [ α I i ′ ( x , y ) ] C_i(x,y) = \beta \log[\alpha I’_i(x,y)] Ci(x,y)=βlog[αIi′(x,y)]
R M S R C R i ( x , y ) = C i ( x , y ) ∗ R M S R i ( x , y ) R_{MSRCR_i}(x,y) = C_i(x,y) *R_{MSR_i}(x,y) RMSRCRi(x,y)=Ci(x,y)∗RMSRi(x,y)
其中 β = 46 , α = 125 β=46,α=125 β=46,α=125为经验参数,测试取1试验表明效果还不错。
对于一些原始图像HUE较为合理的图,如果用经典的MSRCR算法,会导致处理后的图容易偏色,上述论文提出了对图像的Intensity数据进行Retinex处理,然后再把数据根据原始的RGB的比例映射到每个通道,这样就能在保留原始颜色分布的基础上增强图像,文章中称其为MSRCP。
MSRCR 算法步骤

该代码有误待修改
import numpy as np import cv2 def replaceZeroes(data): min_nonzero = min(data[np.nonzero(data)]) data[data == 0] = min_nonzero return data def simple_color_balance(input_img, s1, s2): h, w = input_img.shape[:2] temp_img = input_img.copy() one_dim_array = temp_img.flatten() sort_array = sorted(one_dim_array) per1 = int((h * w) * s1 / 100) minvalue = sort_array[per1] per2 = int((h * w) * s2 / 100) maxvalue = sort_array[(h * w) - 1 - per2] # 实施简单白平衡算法 if (maxvalue <= minvalue): out_img = np.full(input_img.shape, maxvalue) else: scale = 255.0 / (maxvalue - minvalue) out_img = np.where(temp_img < minvalue, 0) # 防止像素溢出 out_img = np.where(out_img > maxvalue, 255) # 防止像素溢出 out_img = scale * (out_img - minvalue) # 映射中间段的图像像素 out_img = cv2.convertScaleAbs(out_img) return out_img def MSRCR(img, scales, s1, s2): h, w = img.shape[:2] scles_size = len(scales) log_R = np.zeros((h, w), dtype=np.float32) img_sum = np.add(img[:,:,0],img[:,:,1],img[:,:,2]) img_sum = replaceZeroes(img_sum) gray_img = [] for j in range(3): img[:, :, j] = replaceZeroes(img[:, :, j]) for i in range(0, scles_size): L_blur = cv2.GaussianBlur(img[:, :, j], (scales[i], scales[i]), 0) L_blur = replaceZeroes(L_blur) dst_img = cv2.log(img[:, :, j]/255.0) dst_Lblur = cv2.log(L_blur/255.0) dst_ixl = cv2.multiply(dst_img, dst_Lblur) log_R += cv2.subtract(dst_img, dst_ixl) MSR = log_R / 3.0 MSRCR = MSR * (cv2.log(125.0 * img[:, :, j]) - cv2.log(img_sum)) gray = simple_color_balance(MSRCR, s1, s2) gray_img.append(gray) return gray_img if __name__ == '__main__': img = './gggg/802.png' scales = [15,101,301] s1, s2 = 2,3 src_img = cv2.imread(img) MSRCR_Out = MSRCR(src_img, scales, s1, s2) result = cv2.merge(MSRCR_Out[0],MSRCR_Out[1],MSRCR_Out[2]) cv2.imshow('img',src_img) cv2.imshow('MSR_result',result) cv2.waitKey(0) cv2.destroyAllWindows() MSRCR其他实现方法
MSRCR方法如上,且获得了不错的效果。但在博文《MSRCR》中,作者认为论文里的方法不起任何作用,并且论文里为了这个又引入了太多的可调参数,增加了算法的复杂性,不利于自动化实现。 博文作者认为,GIMP的contrast-retinex.c文件里使用的算法很好,效果也很好。他直接从量化的方式上入手,引入了均值和均方差的概念,再加上一个控制图像动态的参数来实现无色偏的调节过程,简要描述如下:
- Min = Mean – Dynamic * Var;
Max = Mean + Dynamic * Var; - 对Log[R(x,y)]的每一个值Value,进行线性映射:
R(x,y) = ( Value – Min ) / (Max – Min) * (255 – 0), 同时要注意增加一个溢出判断,即:
if (R(x, y) > 255) R(x,y) = 255;
else if (R(x,y) < 0) R(x,y) = 0; - 就是经过这么简单的处理,实践证明可以取得非常好的效果,下面贴出一些处理后的效果。
MSRCP算法实现:(代码有问题,改进待续)

import numpy as np import cv2 def replaceZeroes(data): min_nonzero = min(data[np.nonzero(data)]) data[data == 0] = min_nonzero return data def simple_color_balance(input_img, s1, s2): h, w = input_img.shape[:2] temp_img = input_img.copy() one_dim_array = temp_img.flatten() sort_array = sorted(one_dim_array) per1 = int((h * w) * s1 / 100) minvalue = sort_array[per1] per2 = int((h * w) * s2 / 100) maxvalue = sort_array[(h * w) - 1 - per2] # 实施简单白平衡算法 if (maxvalue <= minvalue): out_img = np.full(input_img.shape, maxvalue) else: scale = 255.0 / (maxvalue - minvalue) out_img = np.where(temp_img < minvalue, 0,temp_img) # 防止像素溢出 out_img = np.where(out_img > maxvalue, 255,out_img) # 防止像素溢出 out_img = scale * (out_img - minvalue) # 映射中间段的图像像素 out_img = cv2.convertScaleAbs(out_img) return out_img def MSRCP(img, scales, s1, s2): h, w = img.shape[:2] scales_size = len(scales) B_chan = img[:, :, 0] G_chan = img[:, :, 1] R_chan = img[:, :, 2] log_R = np.zeros((h, w), dtype=np.float32) array_255 = np.full((h, w),255.0,dtype=np.float32) I_array = (B_chan + G_chan + R_chan) / 3.0 I_array = replaceZeroes(I_array) for i in range(0, scales_size): L_blur = cv2.GaussianBlur(I_array, (scales[i], scales[i]), 0) L_blur = replaceZeroes(L_blur) dst_I = cv2.log(I_array/255.0) dst_Lblur = cv2.log(L_blur/255.0) dst_ixl = cv2.multiply(dst_I, dst_Lblur) log_R += cv2.subtract(dst_I, dst_ixl) MSR = log_R / 3.0 Int1 = simple_color_balance(MSR, s1, s2) B_array = np.maximum(B_chan,G_chan,R_chan) A = np.minimum(array_255 / B_array, Int1/I_array) R_channel_out = A * R_chan G_channel_out = A * G_chan B_channel_out = A * B_chan MSRCP_Out_img = cv2.merge([B_channel_out, G_channel_out, R_channel_out]) MSRCP_Out = cv2.convertScaleAbs(MSRCP_Out_img) return MSRCP_Out if __name__ == '__main__': img = './gggg/802.png' scales = [15,101,301] s1, s2 = 2,3 src_img = cv2.imread(img) result = MSRCP(src_img, scales, s1, s2) cv2.imshow('img',src_img) cv2.imshow('MSR_result',result) cv2.waitKey(0) cv2.destroyAllWindows() 发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/211139.html原文链接:https://javaforall.net


