
一、数据来源
沪深300指数,是由沪深证券交易所于 2005 年 4 月 8 日联合发布的反映沪深 300 指数编制目标和运行状况的金融指标,并能够作为投资业绩的评价标准,为指数化投资和指数衍生产品创新提供基础条件。因此,本次数据来源于网易财经,研究的数据集对象是沪深 300 指数(股票代码为000300),此次分析选取了沪深 300 指数2000 年1月到2019年12月的工作日收盘价格数据。
二、数据分析
(一)时序图
为了分析数据的波动情况,对其进行对数化和差分得到对数收益率,下图为沪深 300 指数的收盘价时序图和对数收益率时序图。
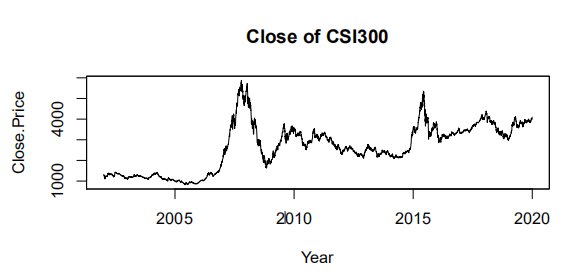

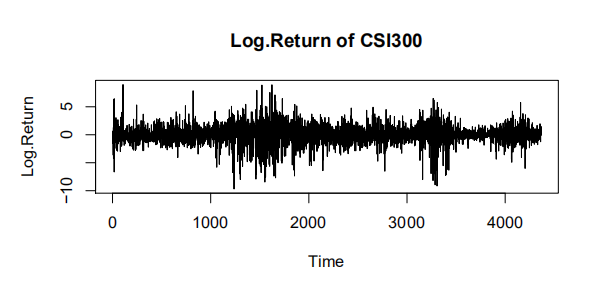
(二)平稳性检验
Augmented Dickey-Fuller Test (ADF) 是 DF 检验的拓展形式,可以对存在高阶滞后的序列进行单位根检验,原假设存在单位根,即序列不平稳。本文使用adf.test()进行单位根检验,检验结果如下所示,p 值远小于 0.01 说明拒绝原假设,即序列是平稳的。
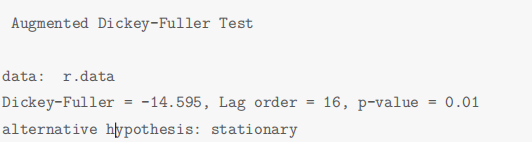
三、模型建立
(一)均值模型
1. 均值模型的识别
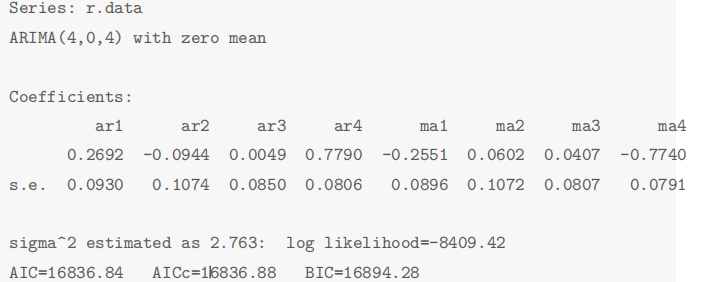
序列平稳后,使用auto.arima()对序列自动识别均值模型。
- 识别出来的模型为
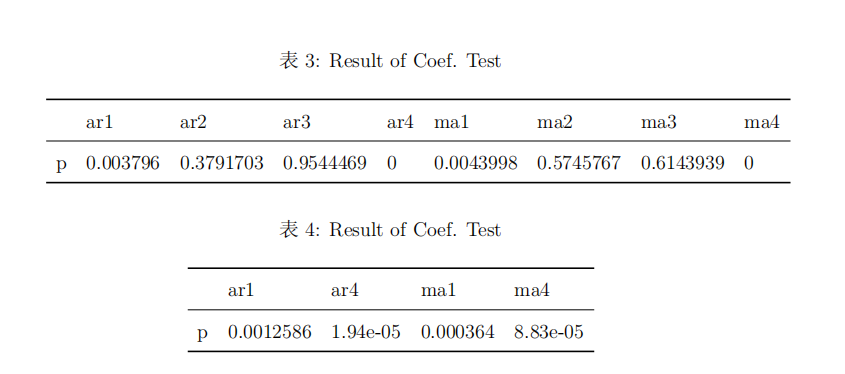
ARMA(4, 4)。经过模型识别后,对模型 A R M A ( 4 , 4 ) ARMA(4,4) ARMA(4,4)进行参数显著性检验。检验结果发现部分参数不显著,采用建立疏系数的均值模型,将不显著的参数强制为0。
- 采用疏系数的 A R M A ARMA ARMA模型后的参数显著性检验结果来看,非零参数结果都显著。(注:这一步存有疑问,后续依旧是采用 A R M A ( 4 , 4 ) ARMA(4,4) ARMA(4,4)的非疏系数模型进行拟合)
(二)方差模型建立
1. ARCH效应检验
上述建立模型后,对残差进行ARCH效应检验。Ljung-Box统计量 Q ( m ) Q(m) Q(m)对残差序列进行自相关检验。原假设是序列不存在自相关,在残差的平方序列中可以检验条件异方差。
- 使用
MTS包中的archTest()进行检验
检验结果显示,滞后10阶和滞后20阶的残差序列存在自相关,因此拒绝原假设,残差序列存在ARCH效应。[1] "m = 10" Q(m) of squared series(LM test): Test statistic: 1043.197 p-value: 0 Rank-based Test: Test statistic: 849.5804 p-value: 0 [2] "m = 20" Q(m) of squared series(LM test): Test statistic: 1705.592 p-value: 0 Rank-based Test: Test statistic: 1565.588 p-value: 0
2. 标准GARCH模型建立
上述ARCH效应表明,条件方差是依赖于过去值。因此可以考虑GARCH模型对方差方程进行参数估计。
- 使用
tseries包中的garch()函数进行拟合标准GARCH模型。
从结果上看,拟合出来的参数都显著,Box-Ljung test结果中的P值大于显著性,因此可以认为模型的残差无序列相关,说明该模型拟合效果较好。但实际上,其中Jarque Bera Test用于对回归残差的正态性进行检验,Shapiro – Wilk Normality Test也可以用于正态性检验,原假设都是是残差序列服从正态分布,检验结果表明,残差序列是不服从正态分布,因此可以对模型进行优化,考虑其他GARCH模型。Call: garch(x = r.data, order = c(1, 1)) Model: GARCH(1,1) Residuals: Min 1Q Median 3Q Max -4.91948 -0.53035 0.04107 0.57992 5.60582 Coefficient(s): Estimate Std. Error t value Pr(>|t|) a0 0.011014 0.002491 4.422 9.78e-06 * a1 0.063407 0.004076 15.556 < 2e-16 * b1 0. 0.003839 243.530 < 2e-16 * --- Signif. codes: 0 '*' 0.001 '' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Diagnostic Tests: Jarque Bera Test data: Residuals X-squared = 659.37, df = 2, p-value < 2.2e-16 Box-Ljung test data: Squared.Residuals X-squared = 1.5224, df = 1, p-value = 0.2173
四、模型优化
(一)模型拟合
上述的模型考虑的是 A R I M A ( 0 , 0 , 0 ) ARIMA(0,0,0) ARIMA(0,0,0)的标准 G A R C H ( 1 , 1 ) GARCH(1,1) GARCH(1,1)模型,即均值模型的参数均设置为0。而从均值模型的分析来看,可以拟合 A R I M A ( 4 , 0 , 4 ) ARIMA(4,0,4) ARIMA(4,0,4)的均值模型与 G A R C H ( 1 , 1 ) GARCH(1,1) GARCH(1,1)的方差模型。而上述的正态性检验结果表明,残差的分布不适用标准正态分布,应该考虑其他类型的分布。
- 使用 r u g a r c h rugarch rugarch包对多个模型进行拟合。
- 对于均值模型,考虑不带截距项的 A R I M A ( 4 , 0 , 4 ) ARIMA(4,0,4) ARIMA(4,0,4)。
- 对于方差模型,阶数设定1阶ARCH和1阶GARCH,考虑标准GARCH( s G A R C H sGARCH sGARCH)、指数GARCH( e G A R C H eGARCH eGARCH)、 G J R − G A R C H GJR-GARCH GJR−GARCH、渐近幂ARCH( A P A R C H APARCH APARCH)、门限GARCH( T G A R C H TGARCH TGARCH)、非线性非对称GARCH( N A G A R C H NAGARCH NAGARCH)六类模型。
- 对于残差分布类型,考虑标准正态分布( n o r m norm norm)、标准t分布( s t d std std)、偏t分布( s s t d sstd sstd)、广义误差分布( g e d ged ged)和Johnson’SU分布( j s u jsu jsu)五类分布。

(二)模型比较
从拟合的模型结果来看,非对称类型的指数GARCH模型在最大似然估计值达到最大,同时AIC和BIC都能达到最小,说明指数GARCH模型比较好。从拟合的模型残差分布来看,非正态分布的AIC和BIC都明显低于正态分布,说明残差是服从重尾类型的分布。
- 选取指数GARCH模型,对比不同分布的参数显著性、检验结果以及模型效果,这里分布考虑正态分布、t分布、广义误差分布与三种分布对应的偏态分布以及Johnson’SU分布,结果如下所示。




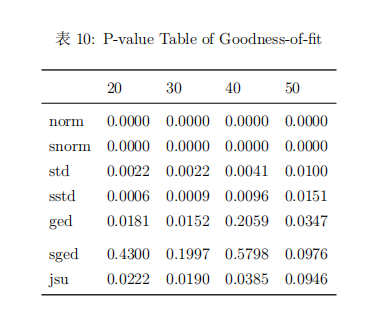

从模型拟合的系数显著性表可以看出,拟合的系数基本都显著,仅有少数参数不显著。从系数稳定性的个别检验和联合检验可以看出,在5%显著性水平下正态分布、偏正态分布、广义误差分布和偏广义误差分布都接收参数是稳定的原假设。从符号偏误检验的结果来看,指数GARCH模型正负残差的受到冲击的差异不明显,说明该非对称模型有效消除了杠杆效应。从调整皮尔逊拟合优度检验的结果来看,原假设是残差分布与理论分布没有差异,结果表明广义误差分布和偏广义误差分布是没有拒绝原假设,说明这两种分布与模型适配较好。
(三)模型选择
从模型拟合的信息准则表来看,偏广义误差分布的LLH达到最大,而BIC和HQ都达到最小,说明 A R M A ( 4 , 4 ) − e G A R C H ( 1 , 1 ) − S G E D ARMA(4,4)-eGARCH(1,1)-SGED ARMA(4,4)−eGARCH(1,1)−SGED模型最优。拟合 A R M A ( 4 , 4 ) − E G A R C H ( 1 , 1 ) − S G E D ARMA(4,4)-EGARCH(1,1)-SGED ARMA(4,4)−EGARCH(1,1)−SGED模型,理论模型和模型参数估计及显著性如下所示。
X t = ∑ i = 1 p φ i X t − i − ∑ j = 1 q ϑ j ε t − j + ε t z t = ε t σ t = X t σ t l n σ t 2 = ω + α z t − 1 + β l n σ t − 1 2 + γ ( ∣ ε t − 1 ∣ σ t − 1 − E ∣ z t − 1 ∣ ) 其 中 , ε t ∼ S G E D ( 0 , 1 , s h a p e , s k e w ) \begin{aligned} X_t &= \sum \limits _{i=1}^{p}\varphi_i X_{t-i} - \sum \limits _{j=1}^{q} \vartheta_j \varepsilon_{t-j} + \varepsilon_t \\ z_t &= \frac{\varepsilon_t}{\sigma_t} = \frac{X_t}{\sigma_t} \\ ln\sigma_t^2 &= \omega +\alpha z_{t-1} + \beta ln\sigma ^2_{t-1} + \gamma (\frac{|\varepsilon_{t-1}|}{\sigma _{t-1}} - E|z_{t-1}|) \\ 其中,& \varepsilon_t \sim SGED(0,1,shape, skew) \end{aligned} Xtztlnσt2其中,=i=1∑pφiXt−i−j=1∑qϑjεt−j+εt=σtεt=σtXt=ω+αzt−1+βlnσt−12+γ(σt−1∣εt−1∣−E∣zt−1∣)εt∼SGED(0,1,shape,skew)

五、结论
六、实现代码
# Created by: Enguanei # Created on: 2021/5/7 # 导入包 library(knitr) library(pedquant) library(zoo) library(imputeTS) library(tseries) library(forecast) library(MTS) library(rugarch) library(dplyr) # 爬取网易财经的数据 datt <- md_stock(symbol = '000300.ss', from = "2002-01-01", to = "2019-12-31", source = "163") # 查看数据 head(datt$`000300.ss`$close) head(datt$`000300.ss`$date) # 保存数据 write.csv(datt, "D:\\Rproject\\hs300.csv") # 导入数据 raw_data <- read.csv("D:\\Rproject\\hs300.csv", header = TRUE) # 转成时间序列 my_date <- as.Date(raw_data$X000300.ss.date) my_data <- raw_data$X000300.ss.close data.ts <- zoo(my_data, my_date) # 查看是否存在缺失值 sum(is.na(my_data)) # 转成时间序列(不包括日期)和对数差分化处理 r.data <- diff(log(ts(my_data))) * 100 # 画出时序图 par(mfrow = c(2, 1)) plot(data.ts, xlab = 'Year', ylab = 'Close.Price', main = 'Close of CSI300') plot(r.data, ylab = 'Log.Return', main = 'Log.Return of CSI300') # 平稳性检验 show(adf.test(r.data)) # 拟合arma均值模型 md1 <- auto.arima(r.data) md1 # 系数显著性检验 t <- md1$coef / sqrt(diag(md1$var.coef)) p_1 <- 2 * (1 - pnorm(abs(t))) kable(rbind(p = p_1), caption = "Result of Coef. Test") # 拟合疏系数arma mean_md_1 <- Arima(r.data, order = c(4, 0, 4), fixed = c(NA, 0, 0, NA, NA, 0, 0, NA, 0)) # 疏系数模型的系数显著性检验 t <- mean_md_1$coef / sqrt(diag(mean_md_1$var.coef)) p_2 <- 2 * (1 - pnorm(abs(t))) kable(rbind(p = p_2[p_2 != 1]), caption = "Result of Coef. Test") # ARCH效应检验(原假设是没有ARCH效应) print(paste0('m = 10')) archTest(mean_md_1$res, lag = 10) print(paste0('m = 20')) archTest(mean_md_1$res, lag = 20) # 使用tseries拟合sGARCH(只能拟合方差模型,没有考虑均值模型) out <- garch(r.data, order = c(1, 1)) summary(out) # 模型优化 # 模型选择 md_name <- c("sGARCH", "eGARCH", "gjrGARCH", "apARCH", "TGARCH", "NAGARCH") md_dist <- c("norm", "std", "sstd", "ged", "jsu") # 设定函数 model_train <- function(data_, m_name, m_dist) { res <- NULL for (i in m_name) { sub_model <- NULL main_model <- i if (i == "TGARCH" | i == "NAGARCH") { sub_model <- i main_model <- "fGARCH" } for (j in m_dist) { model_name <- paste0('ARMA(4,4)', '-', i, '-', j, sep = "") if (main_model == "fGARCH") { model_name <- paste0('ARMA(4,4)', '-', sub_model, '-', j, sep = "") } print(model_name) # 模型设定 mean.spec <- list(armaOrder = c(4, 4), include.mean = F, archm = F, archpow = 1, arfima = F, external.regressors = NULL) var.spec <- list(model = main_model, garchOrder = c(1, 1), submodel = sub_model, external.regressors = NULL, variance.targeting = F) dist.spec <- j my_spec <- ugarchspec(mean.model = mean.spec, variance.model = var.spec, distribution.model = dist.spec) # 模型拟合 my_fit <- ugarchfit(data = data_, spec = my_spec) res <- rbind(res, c(list(ModelName = model_name), list(LogL = likelihood(my_fit)), list(AIC = infocriteria(my_fit)[1]), list(BIC = infocriteria(my_fit)[2]), list(RMSE = sqrt(mean(residuals(my_fit)^2))), list(md = my_fit))) } } return(res) } # 模型拟合 my_model <- model_train(r.data, md_name, md_dist) # 保存模型结果 write.table(my_model[, 1:5], "D:\\Rproject\\result.txt", sep = " ") # 读取模型结果 res_table <- read.table("D:\\Rproject\\result.txt", header = TRUE, sep = " ") kable(res_table, caption = "Result of GARCH Model", align = 'l') # 选择模型再拟合 md_name <- c("eGARCH") md_dist <- c("norm", "snorm", "std", "sstd", "ged", "sged", "jsu") new_model <- model_train(r.data, md_name, md_dist) # 信息准则表 my_info_cri <- NULL for (i in 1:dim(new_model)[1]) { new_aic <- round(infocriteria(new_model[i, 6]$md)[1], digits = 4) new_bic <- round(infocriteria(new_model[i, 6]$md)[2], digits = 4) new_sib <- round(infocriteria(new_model[i, 6]$md)[3], digits = 4) new_hq <- round(infocriteria(new_model[i, 6]$md)[4], digits = 4) new_llk <- round(likelihood(new_model[i, 6]$md), digits = 4) my_info_cri <- rbind(my_info_cri, c(new_model[i, 1], Akaike = new_aic, Bayes = new_bic, Shibata = new_sib, HQ = new_hq, LLH = new_llk)) } # 模型系数显著性表 my_cof_table <- NULL my_cof_names <- NULL for (i in 1:dim(new_model)[1]) { my_cof_names <- rbind(my_cof_names, new_model[i, 1]$ModelName) my_df <- data.frame(t(round(new_model[i, 6]$md@fit$robust.matcoef[, 4], digits = 4))) if (i == 1) { my_cof_table <- data.frame(my_df) } else { my_cof_table <- full_join(my_cof_table, my_df) } } row.names(my_cof_table) <- my_cof_names[, 1] my_cof_table <- t(my_cof_table) # 参数稳定性个别检验表 my_nyblom_table <- NULL my_nyblom_name <- NULL for (i in 1:dim(new_model)[1]) { my_nyblom_name <- rbind(my_nyblom_name, new_model[i, 1]$ModelName) my_df <- data.frame(t(round(nyblom(new_model[i, 6]$md)$IndividualStat, digits = 4))) if (i == 1) { my_nyblom_table <- data.frame(my_df) } else { my_nyblom_table <- full_join(my_nyblom_table, my_df) } } row.names(my_nyblom_table) <- my_nyblom_name[, 1] my_IC <- NULL for (i in 1:dim(new_model)[1]) { my_IC <- cbind(my_IC, nyblom(new_model[1, 6]$md)$IndividualCritical) } my_nyblom_table <- rbind(t(my_nyblom_table), my_IC) # 参数稳定性联合检验表 my_nyblom_table2 <- NULL my_nyblom_name2 <- NULL for (i in 1:dim(new_model)[1]) { my_nyblom_name2 <- rbind(my_nyblom_name2, new_model[i, 1]$ModelName) df1 <- data.frame(JoinStat = round(nyblom(new_model[i,6]$md)$JointStat, digits = 4)) df2 <- data.frame(mm = round(nyblom(new_model[i, 6]$md)$JointCritical, digits = 4)) temp_table <- cbind(df1, t(df2)) if (i == 1) { my_nyblom_table2 <- temp_table } else { my_nyblom_table2 <- full_join(my_nyblom_table2, temp_table) } } row.names(my_nyblom_table2) <- my_nyblom_name2 # 模型分布拟合度p值检验表 my_gof_table <- NULL my_gof_name <- NULL group_name <- c(20, 30, 40, 50) for (i in 1:dim(new_model)[1]) { my_gof_name <- rbind(my_gof_name, new_model[i, 1]$ModelName) df1 <- round(gof(new_model[i, 6]$md, groups = group_name)[1:4, 3], digits = 4) if (i == 1) { my_gof_table <- df1 } else { my_gof_table <- rbind(my_gof_table, df1) } } row.names(my_gof_table) <- my_gof_name colnames(my_gof_table) <- c(20, 30, 40, 50) # 符号偏误显著性检验表 my_sign_table <- NULL my_sign_name <- NULL row_sign_name <- row.names(signbias(new_model[1, 6]$md)) for (i in 1:dim(new_model)[1]) { my_sign_name <- rbind(my_sign_name, new_model[i, 1]$ModelName) df1 <- round(signbias(new_model[i, 6]$md)$prob, digits = 4) if (i == 1) { my_sign_table <- df1 } else { my_sign_table <- rbind(my_sign_table, df1) } } row.names(my_sign_table) <- my_sign_name colnames(my_sign_table) <- row_sign_name # 展示表格 kable(my_cof_table, caption = "P-value Table of Coefficients") kable(my_nyblom_table, caption = "P-value Table of Nyblom Individual Stability Test") kable(my_nyblom_table2, caption = "P-value Table of Nyblom Joint Stability Test") kable(my_sign_table, caption = "P-value Table of Sign Bias Test") kable(my_gof_table, caption = "P-value Table of Goodness-of-fit") kable(my_info_cri, caption = "Table of Information Criteria") # 最终模型系数表 kable(new_model[6, 6]$md@fit$robust.matcoef, caption = "Table of Final Model Coef.") 七、参考资料
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/211324.html原文链接:https://javaforall.net


