
一、Scrapy 基础知识
1、Scrapy 基本模块
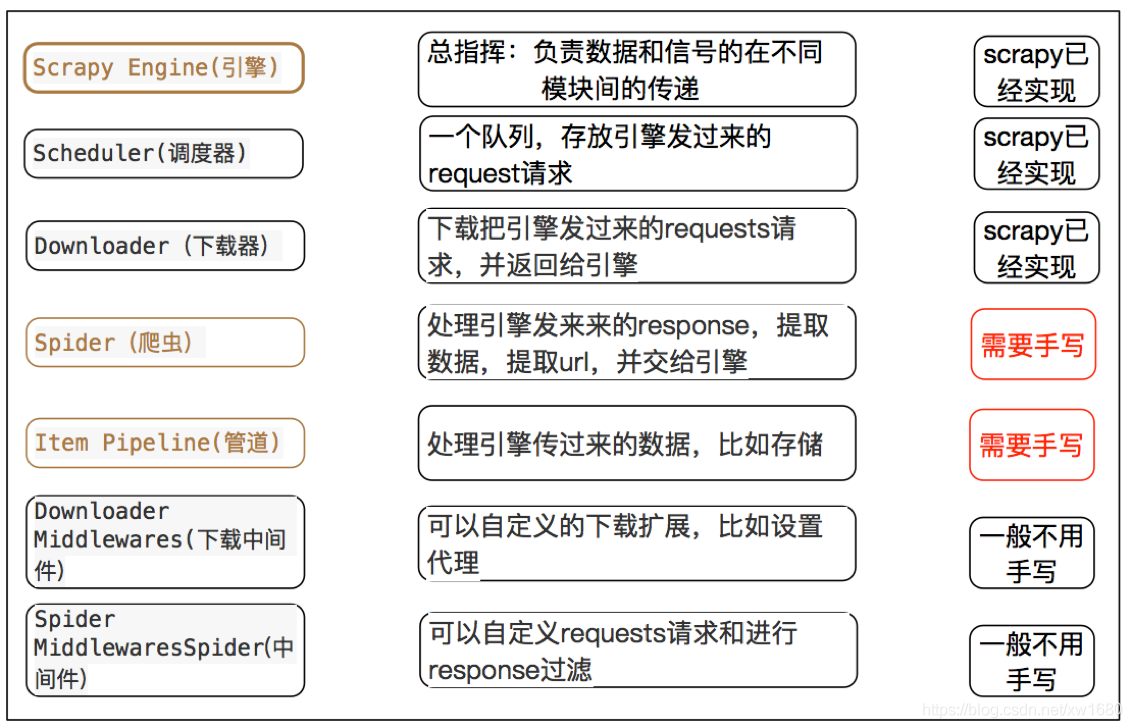
(1) 调度器(Scheduler)
调度器,说白了把它假设成为一个
URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是什么,同时去除重复的网址(不做无用功)。用户可以自己的需求定制调度器。(2) 下载器(Downloader)
下载器,是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy 的下载器代码不会太复杂,但
效率高,主要的原因是 Scrapy 下载器是建立在 twisted 这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)。(3) 爬虫(Spider)
爬虫,是用户最关心的部份。
用户定制自己的爬虫(通过定制正则表达式等语法),用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。例如使用 Xpath 提取感兴趣的信息。
用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。(4) 实体管道(Item Pipeline)
实体管道,用于接收网络爬虫传过来的数据,以便做进一步处理。例如
验证实体的有效性、清除不需要的信息、存入数据库(持久化实体)、存入文本文件等。(5) Scrapy引擎(Scrapy Engine)
Scrapy 引擎是整个框架的核心,用来处理整个系统的数据流,触发各种事件。它用来
控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。(6) 中间件
整个 Scrapy 框架有很多中间件,如下载器中间件、网络爬虫中间件等,这些中间件相当于过滤器,夹在不同部分之间截获数据流,并进行特殊的加工处理。
2、Scrapy 工作流程


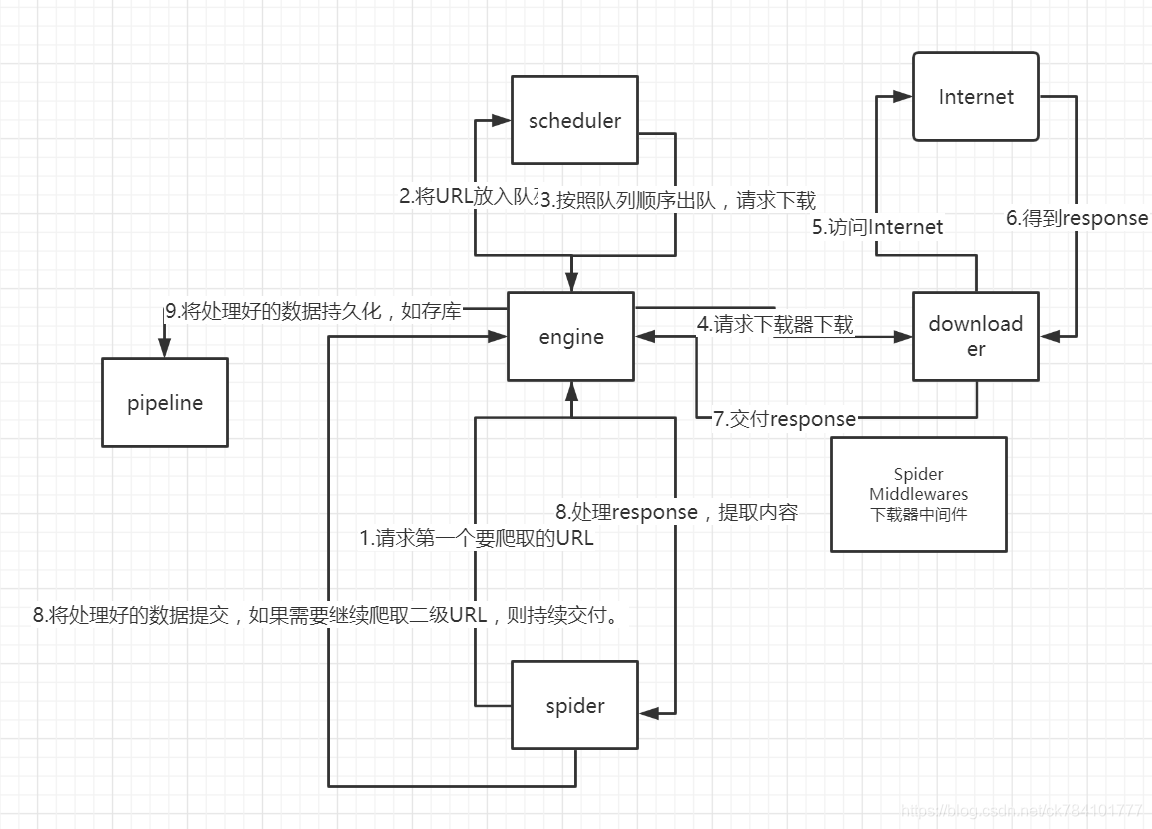
流程如下:
每个模块的具体作用:
3、Scrapy 依赖的 python 包
Scrapy 是用纯python编写的,它依赖于几个关键的python包(以及其他包):
4、XPath
写爬虫最重要的是解析网页的内容,这个部分就介绍下通过 XPath 来解析网页,提取内容。
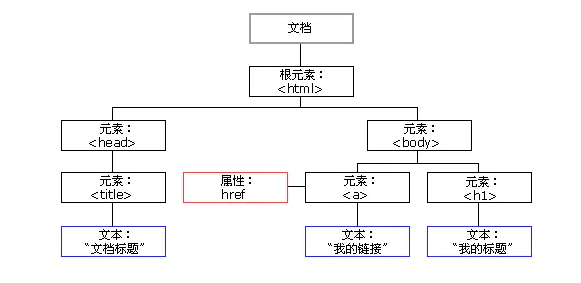
(1)HTML 节点和属性
(2)XPath 常用规则
二、Scrapy 框架安装
1、Scrapy 安装
(1)Anaconda Python
conda install scrapy (2)windows 标准 Python 开发环境
pip install scrapy (3)ubuntu 标准 Python 开发环境
pip install scrapy # 或 pip3 install scrapy 验证安装成功:
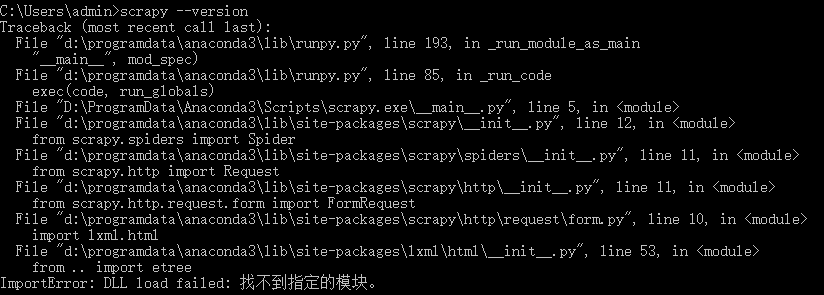
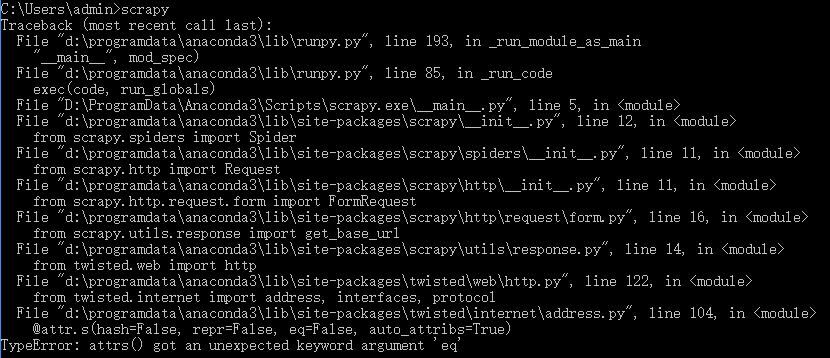
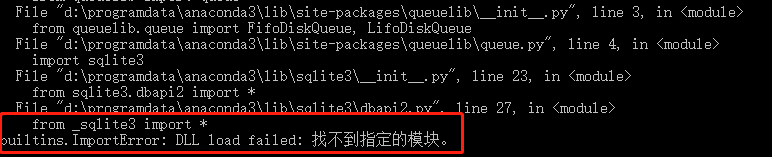
(1)ImportError: DLL load failed: 找不到指定的模块。
解决方法:lxml 版本与 Scrapy 版本不匹配,更新 lxml 版本pip install lxml --upgrade(2)TypeError: attrs() got an unexpected keyword argument ‘eq’
解决方法:attrs 的版本不够,更新 attrs 版本pip install attrs --upgrade
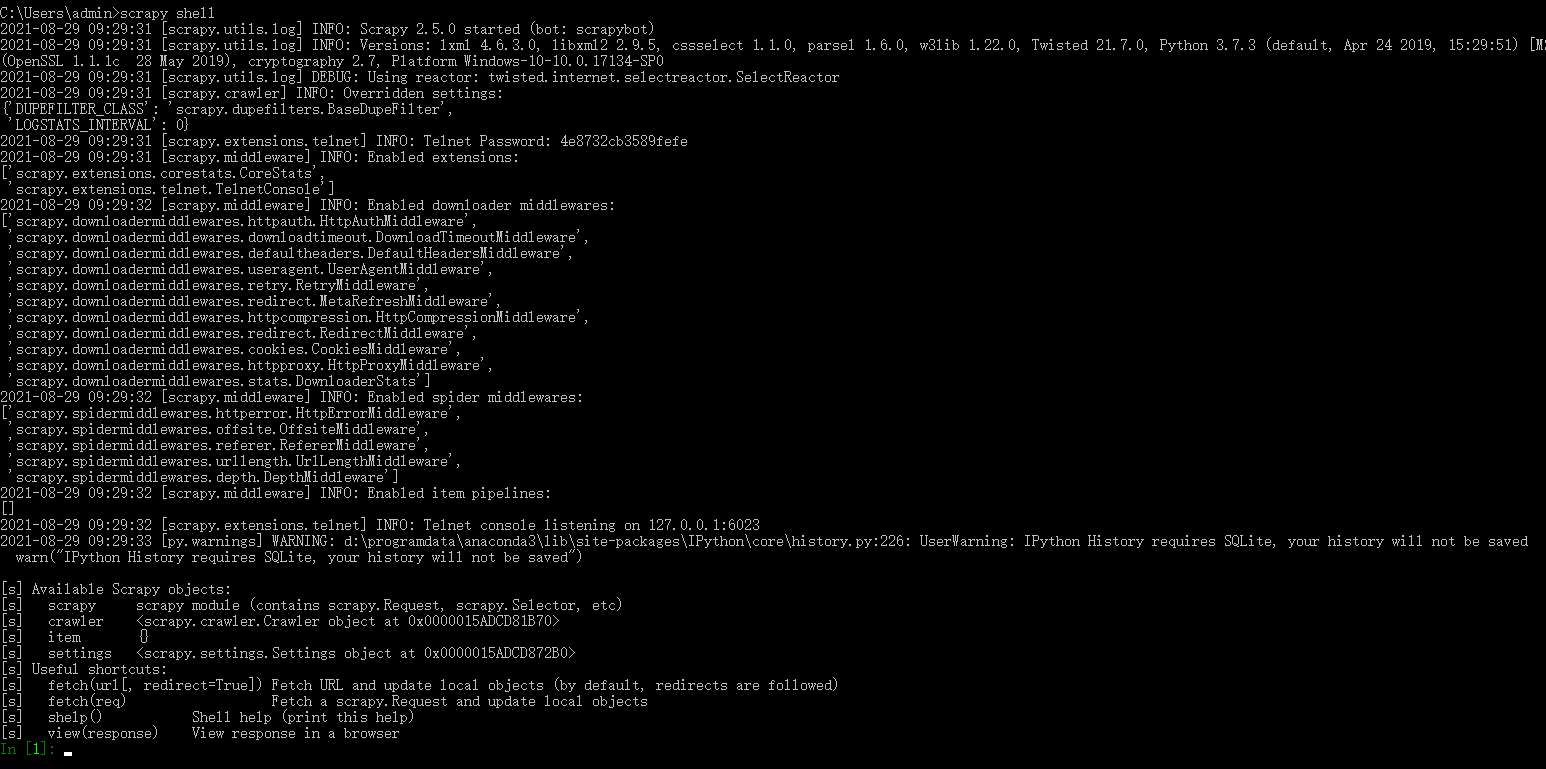
2、Scrapy Shell
Scrapy 提供了一个 Shell 相当于 Python 的 REPL 环境,可以用这个 Scrapy Shell 测试 Scrapy 代码。在 Windows 中打开黑窗口,执行 scrapy shell 命令,就会进入 Scrapy Shell。
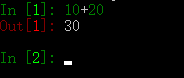
Scrapy Shell 和 Python 的 REPL 环境差不多,也可以执行任何的 Python 代码,只是又多了对 Scrapy 的支持,例如,在 Scrapy Shell 中输入 10 + 20,然后回车,会输出 30,如下图所示:
(1)使用 Scrapy Shell 抓取网页
/html/body/div[3]/div/ul[1]/li[2]/a在 Scrapy Shell 中启动淘宝首页。
scrapy shell https://www.taobao.com
response.xpath('/html/body/div[3]/div/ul[1]/li[2]/a/text()').extract()response.xpath('/html/body/div[3]/div/ul[1]/li[2]/a/text()').extract()[0]

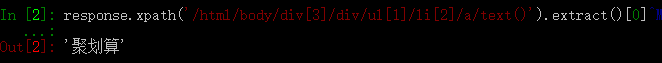
(2)运行 scrapy demo 时报错:[twisted] CRITICAL: Unhandled error in Deferred
报错页面:
原因:是 sqlite 的问题,没有这个包。
cmd 下进入python命令,导入这个包试试:
导入 sqlite3.def 和 sqlite3.dll 两个文件到本地的 python 环境下的 DLLs包,比如 C:\Anaconda2\DLLs 文件夹 。
sqlite下载:sqlite下载官方网址
下载解压后放在 python 环境下的 DDLs 包。




三、用 Scrapy 编写网络爬虫
1、创建 Scrapy 工程
(1)Scrapy 框架提供了一个 scrapy 命令用来建立 Scrapy 工程,命令如下:
scrapy startproject 工程名 (2)Scrapy 框架提供了一个 scrapy 命令用来建立爬虫文件,爬虫文件为主要的代码作业文件,通常一个网站的爬取动作都会在爬虫文件中进行编写。命令如下:
该命令会在当前文件下建立 Scrapy 工程,因此建议在自定的目录下打开 CMD 命令并创建工程。
cd 工程名 scrapy genspider 爬虫文件名 待爬取的网站域名 创建后目录大致如下:
在 spiders 目录中建立了一个 first_spider.py 脚本文件,这是一个 Spider 程序,在该程序中会指定要抓取的 Web 资源的 URL。

示例:
2、各目录文件详解
(1)爬虫文件
Request 对象的用法:
yield Request(url[, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback, flags])
(2)middlewares.py
Spider 中间件是介入到 Scrapy 的 spider 处理机制的钩子框架,您可以添加代码来
处理发送给 Spiders 的 response 及 spider 产生的 item 和 request。
要启用 Spider 中间件(Spider Middlewares),就必须在 setting.py 中进行 SPIDER_MIDDLEWARES 设置中。 该设置是一个字典,键为中间件的路径,值为中间件的顺序(order)。SPIDER_MIDDLEWARES = { 'myproject.middlewares.CustomSpiderMiddleware': 543, }SPIDER_MIDDLEWARES = { 'myproject.middlewares.CustomSpiderMiddleware': 543, 'scrapy.contrib.spidermiddleware.offsite.OffsiteMiddleware': None, }Spider 中间件方法:
process_spider_input(response, spider) # response (Response 对象) – 被处理的response # spider (Spider 对象) – 该response对应的spider当 response 通过 spider 中间件时,该方法被调用,处理该response。process_spider_input() 应该返回 None 或者抛出一个异常(exception)。 如果其返回 None ,Scrapy将会继续处理该response,调用所有其他的中间件直到spider处理该response。如果其抛出一个异常(exception),Scrapy将不会调用任何其他中间件的 process_spider_input() 方法,并调用request的errback。 errback的输出将会以另一个方向被重新输入到中间件链中,使用 process_spider_output() 方法来处理,当其抛出异常时则带调用process_spider_exception() 。
process_spider_output(response, result, spider) # response (Response 对象) – 生成该输出的response # result (包含 Request 或 Item 对象的可迭代对象(iterable)) – spider返回的result # spider (Spider 对象) – 其结果被处理的spider当 Spider 处理 response 返回 result 时,该方法被调用。process_spider_output() 必须返回包含 Request 或 Item 对象的可迭代对象(iterable)。
process_spider_exception(response, exception, spider) # response (Response 对象) – 异常被抛出时被处理的response # exception (Exception 对象) – 被跑出的异常 # spider (Spider 对象) – 抛出该异常的spider当 spider (或其他spider中间件的) process_spider_input() 抛出异常时, 该方法被调用。process_spider_exception() 必须要么返回 None , 要么返回一个包含 Response 或 Item 对象的可迭代对象(iterable)。 如果其返回 None ,Scrapy 将继续处理该异常,调用中间件链中的其他中间件的 process_spider_exception() 方法,直到所有中间件都被调用,该异常到达引擎(异常将被记录并被忽略)。如果其返回一个可迭代对象,则中间件链的 process_spider_output() 方法被调用, 其他的 process_spider_exception() 将不会被调用。
2)Download Middlewares
下载器中间件是引擎和下载器之间通信的中间件:当引擎传递请求给下载器的过程中,下载中间件可以对请求进行处理 (例如增加http header信息,增加proxy信息等);在下载器完成http请求,传递响应给引擎的过程中, 下载中间件可以对响应进行处理(例如进行gzip的解压等)。
在这个中间件中我们可以设置代理、更换请求头信息等来达到反反爬虫的目的。要写下载器中间,可以在下载器中实现两个方法。一个是process_request(self, request, spider),这个方法是在请求发送之前会执行,还有一个是process_response(self, request, response, spider),这个方法是数据下载到引擎之前执行。
要激活下载器中间件组件,就必须在 setting.py 中进行 DOWNLOADER_MIDDLEWARES 设置。 该设置是一个字典(dict),键为中间件类的路径,值为其中间件的顺序(order)。DOWNLOADER_MIDDLEWARES = { 'mySpider.middlewares.MyDownloaderMiddleware': 543, }方法:
process_request(self, request, spider) # request : 发送请求的request对象。 # spider : 发送请求的spider对象。process_response(self, request, response, spider) # request:request对象。 # response:被处理的response对象。 # spider:spider对象.
(3)settings.py
(3)items.py
items 提供一个字段存储, spider 会将数据存在这里。
爬虫爬取的主要目标是从非结构化数据源中提取结构化数据,通常是web页面。作为Python语言,Scrapy spiders 可以返回提取的数据。虽然方便而又熟悉,但 Python 却缺乏结构,特别是在一个包含许多 spider 的大型项目中在字段名中输入错误或返回不一致的数据。
为了定义常见的输出数据格式,scrapy 提供了 item 类,Item 对象是用来收集提取数据的简单容器。它们提供了一个类似于字典的API,提供了一种方便的语法,用于声明可用字段。
各种各样的 scrapy 组件使用由 item 提供的附加信息,查看已声明的字段,以找出导出的列,可以使用 item 字段元数据定制序列化,trackref跟踪项目实例以帮助发现内存泄漏。
Item 使用简单的类定义语法和字段对象声明,如下所示:import scrapy class Product(scrapy.Item): # 字段类型就是简单的scrapy.Field name = scrapy.Field() price = scrapy.Field() stock = scrapy.Field() last_updated = scrapy.Field(serializer=str)Field 对象用于为每个字段指定元数据,您可以为每个字段指定任何类型的元数据,对 Field 对象的值没有限制。需要注意的是,用于声明该项的字段对象不会被分配为类属性。相反,可以通过Item.fields访问它们。
(4)使用 Item:
1)创建 items
product = Product(name='Desktop PC', price=1000) print product # Product(name='Desktop PC', price=1000)2)获取 Field 值
product['name'] # Desktop PC product.get('name') # Desktop PC product['last_updated'] # Traceback (most recent call last): # ... # KeyError: 'last_updated' product.get('last_updated', 'not set') # not set product['lala'] # getting unknown field # Traceback (most recent call last): # ... # KeyError: 'lala' product.get('lala', 'unknown field') # 'unknown field' 'name' in product # True 'last_updated' in product # False 'last_updated' in product.fields # True 'lala' in product.fields # False3)设置 Field 值
product['last_updated'] = 'today' product['last_updated'] # today product['lala'] = 'test' # setting unknown field # Traceback (most recent call last): # ... # KeyError: 'Product does not support field: lala'4)获取所有内容
product.keys() # ['price', 'name'] product.items() # [('price', 1000), ('name', 'Desktop PC')]5)复制 items
product2 = Product(product) print product2 # Product(name='Desktop PC', price=1000) product3 = product2.copy() print product3 # Product(name='Desktop PC', price=1000)6)从items创建字典
dict(product) # create a dict from all populated values # {'price': 1000, 'name': 'Desktop PC'}7)从字典创建 items
Product({ 'name': 'Laptop PC', 'price': 1500}) # Product(price=1500, name='Laptop PC') Product({ 'name': 'Laptop PC', 'lala': 1500}) # warning: unknown field in dict # Traceback (most recent call last): # ... # KeyError: 'Product does not support field: lala'
(5)pipelines.py
Item pipline 的主要责任是负责处理爬虫从网页中抽取的 Item,他的主要任务是清洗、验证和存储数据。当页面被蜘蛛解析后,将被发送到 Item pipline,并经过几个特定的次序处理数据。
每个 Item pipline 的组件都是有一个简单的方法组成的 Python 类。获取 Item 并执行方法,同时还需要确定是否需要 Item 管道中继续执行下一步或是直接丢弃掉不处理。简而言之,通过 spider 爬取的数据都会通过这个 pipeline 处理,可以在 pipeline 中执行相关对数据的操作。
每个 item piple 组件是一个独立的 pyhton 类,必须实现 process_item(self,item,spider)方法,每个 item pipeline 组件都需要调用该方法,这个方法必须返回一个具有数据的 dict 或者 item 对象,或者抛出 DropItem 异常,被丢弃的 item 将不会被之后的 pipeline 组件所处理。def download_from_url(url): response = requests.get(url, stream=True) if response.status_code == requests.codes.ok: return response.content else: print('%s-%s' % (url, response.status_code)) return None class SexyPipeline(object): def __init__(self): self.save_path = '/tmp' def process_item(self, item, spider): if spider.name == 'sexy': # 取出item里内容 img_url = item['img_url'] # 业务处理 file_name = img_url.split('/')[-1] content = download_from_url(img_url) if content is not None: with open(os.path.join(self.save_path, file_name), 'wb') as fw: fw.write(content) return itemopen_spider(self,spider)open_spider() 方法是在 Spider 开启的时候被自动调用的。在这里我们可以做一些初始化操作,如开启数据库连接等。其中,参数 spider 就是被开启的 Spider 对象。
close_spider(self,spider)close_spider() 方法是在 Spider 关闭的时候自动调用的。在这里我们可以做一些收尾工作,如关闭数据库连接等。其中,参数 spider 就是被关闭的 Spider 对象。
from_crawler(cls,crawler)from_crawler() 方法是一个类方法,用 @classmethod 标识,是一种依赖注入的方式。它的参数是 crawler,通过 crawler 对象,我们可以拿到 Scrapy 的所有核心组件,如全局配置的每个信息,然后创建一个 Pipeline 实例。参数 cls 就是 Class,最后返回一个 Class 实例。
piplines.py 里的类必须在 settings.py 里的 ITEM_PIPELINES 字段中使用全类名定义,这样才能开启 piplines.py 里的类,否则不能使用。
(6)pipeline 的优先级
在 setting.py 中调整他们的优先级,如果有爬虫数据,优先执行存库操作。
'scrapyP1.pipelines.BaiduPipeline': 300, 'scrapyP1.pipelines.BaiduMysqlPipeline': 200, }
3、使用 Scrapy 抓取数据,并通过 Xpath 指定解析规则
在 parse 方法中通过 response 参数设置 Xpath,然后从 HTML 代码中过滤出感兴趣的信息,最后将这些信息输出到 Pycharm 的控制台中。
import scrapy from urllib.parse import urljoin class BlogSpiderSpider(scrapy.Spider): name = 'blog_spider' # allowed_domains = ['geekori.com'] # start_urls = ['http://geekori.com/'] start_urls = ['https://geekori.com/blogsCenter.php?uid=geekori'] def parse(self, response): # 过滤出指定页面所有的博文 selector_list = response.xpath('//div[@id="all"]/div[1]/section') # 对博文列表进行迭代 for selector in selector_list: blog_dict = {
} # 1.获取博文标题 title = selector.xpath('./div[@class="summary"]/h2/a/text()').extract_first() blog_dict['title'] = title # 2.获取博文的URL blog_dict['href'] = urljoin(response.url, selector.xpath('./div[@class="summary"]/h2/a/@href').extract_first()) # 3.获取博文的摘要 blog_dict['abstract'] = selector.xpath('./div[@class="summary"]/p/text()').extract_first() print(blog_dict) 4、将抓取到的数据保存为多种格式的文件
执行爬虫文件时添加 -o 选项可以指定保存的文件类型,如
scrapy crawl 爬虫名 -o csvname.csv scrapy crawl 爬虫名 -o jsonname.json持久化存储对应的文本文件的类型:

(1)基于终端指令的持久化存储
1)blog_spider.py 文件代码:
import scrapy from urllib.parse import urljoin class BlogSpiderSpider(scrapy.Spider): name = 'blog_spider' # allowed_domains = ['geekori.com'] # start_urls = ['http://geekori.com/'] start_urls = ['https://geekori.com/blogsCenter.php?uid=geekori'] def parse(self, response): # 过滤出指定页面所有的博文 selector_list = response.xpath('//div[@id="all"]/div[1]/section') all_data = [] # 建立空列表,将抓取的数据进行存储 # 对博文列表进行迭代 for selector in selector_list: blog_dict = { } # 1.获取博文标题 title = selector.xpath('./div[@class="summary"]/h2/a/text()').extract_first() blog_dict['title'] = title # 2.获取博文的URL blog_dict['href'] = urljoin(response.url, selector.xpath('./div[@class="summary"]/h2/a/@href').extract_first()) # 3.获取博文的摘要 blog_dict['abstract'] = selector.xpath('./div[@class="summary"]/p/text()').extract_first() all_data.append(blog_dict) return(all_data) # 将存储数据的列表返回2)main.py 文件中调用爬虫文件 Scrapy 提供了执行爬虫文件的命令:
scrapy crawl 爬虫名为了直接能在 Python 工程中运行网络爬虫,需要建立一个 main.py(文件名可以任意起) 文件,然后使用代码调用执行爬虫命令。
from scrapy.cmdline import execute import os import sys sys.path.append(os.path.dirname(os.path.abspath(__file__))) # 如果要运行其他的网络爬虫,只需修改上面代码中字符串里面的命令即可 execute(["scrapy", "crawl", "first_spider"," -o"," info.csv"]) # 或者(cmdline.execute("scrapy crawl first_spider -o info.csv -t csv".split())
(2)基于管道持久化存储
class BlogsspiderPipeline(object): fp = None # 重写父类的一个方法: 该方法只在开始爬虫的时候被调用1次 def open_spider(self, spider): print('开始爬虫......') self.fp = open('blog.txt', 'w', encoding='utf8') # 专门用来处理 item类型的对象,该方法可以接收爬虫脚本提交过来的item对象 # 注意: 该方法每接收到一个 item就会被调用一次 def process_item(self, item, spider): title = item['title'] href = item['href'] abstract = item['abstract'] self.fp.write(title + '----' + href + '----' + abstract.strip() + '\n') return item def close_spider(self, spider): print('结束爬虫......') self.fp.close()3)配置文件 setting.py 中开启管道
from scrapy.cmdline import execute import os import sys sys.path.append(os.path.dirname(os.path.abspath(__file__))) # 如果要运行其他的网络爬虫,只需修改上面代码中字符串里面的命令即可 execute(["scrapy", "crawl", "first_spider","-o"," blog.csv"]) # 或者(cmdline.execute('scrapy crawl first_spider -o blog.csv'.split())

5、数据存放到数据库
6、抓取多个 URL (基于Spider的全站数据爬取)
即将网站中某板块下的全部页码对应的页面数据进行爬取。
(1)将所有页面的url添加到 start_urls 列表
在爬虫类的 start_urls 变量中添加多个 URL,运行爬虫时就会抓取 start_urls 变量中所有的 URL。如下:
class BlogSpiderSpider(scrapy.Spider): name = 'blog_spider' start_urls = ['https://geekori.com/blogsCenter.php?uid=geekori', 'https://geekori.com/blogsCenter.php?uid=geekori&page=2'] ....
(2)自行手动进行请求发送
根据要爬取的 url 的变化规律,让代码自动进行改变 url。
import scrapy class CampusbelleSpider(scrapy.Spider): name = 'CampusBelle' # allowed_domains = ['www..com'] start_urls = ['http://www..com/meinvxiaohua/'] template_url = 'http://www.521609.com/meinvxiaohua/list12%d.html' # 分析得出url规律 page_num = 2 # 页码 def parse(self, response): items=TxmoviesItem() lists=response.xpath('//div[@class="index_img list_center"]/ul/li"]') for i in lists: items['name']=i.xpath('./a/@title').get() items['description']=i.xpath('./div/div/@title').get() yield items # 把控制权给管道 if self.page_num <= 11: new_url = format(self.template_url % self.page_num) self.page_num += 1 yield scrapy.Request(url=new_url, callback=self.parse)关于 yield:
class TxmoviesPipeline(object): def process_item(self, item, spider): print(item) return item2)第二个 yield:程序利用了一个
回调机制,即 callback,回调的对象是 parse,也就是当前方法,通过不断的回调,程序将陷入循环,直到程序执行完毕。如果不给程序加条件,就会陷入死循环,如本程序我把 if 去掉,那就是死循环了。yield 与 return 的异同:
7、深度爬取
使用场景:如果爬取解析的数据不在同一张页面中。
需求:爬取 起点中文网 小说的标题以及作者(详情页中)。
import scrapy from QiDianSpider.items import QidianspiderItem class QidianSpider(scrapy.Spider): name = 'qidian' # allowed_domains = ['www.xxx.com'] # TODO 1.替换start_urls列表中的起始url start_urls = ['https://www.qidian.com/all'] template_url = 'https://www.qidian.com/all?orderId=&style=1&pageSize=20&siteid=1&pubflag=0&hiddenField=0&page=%d' page_num = 2 def parse(self, response): # TODO 2.数据解析 li_list = response.xpath('//div[@class="all-book-list"]/div/ul/li') for li in li_list: # 实例化 QidianspiderItem 对象 item = QidianspiderItem() # 使用xpath提取小说中的标题及详情页的链接 title = li.xpath('./div[2]/h4/a/text()').extract_first() detail_url = response.urljoin(li.xpath('./div[2]/h4/a/@href').extract_first()) item['title'] = title # 标题直接放入 Item 中 # author 需要深度挖掘,打开新的链接页面获得 yield scrapy.Request(url=detail_url, callback=self.parse_detail, meta={ 'item': item}) if self.page_num <= 5: new_url = format(self.template_url % self.page_num) self.page_num += 1 yield scrapy.Request(url=new_url, callback=self.parse) def parse_detail(self, response): item = response.meta['item'] author = response.xpath('//h1/span/a/text()').extract_first() item['author'] = author yield item # 把控制权给管道在 pipelines.py 文件中处理数据,这里为了简单,直接在控制台输出结果。
class TxmoviesPipeline(object): def process_item(self, item, spider): print(item) return item
四、示例
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/211918.html原文链接:https://javaforall.net


