
FCM算法
全名为Fuzzy C-Means,是一种聚类算法。
- J. C. Dunn (1973): “A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact Well-Separated Clusters”, Journal of Cybernetics 3: 32-57
- J. C. Bezdek (1981): “Pattern Recognition with Fuzzy Objective Function Algoritms”, Plenum Press, New York
基于最小化下面的目标函数:
J m = ∑ i = 1 N ∑ j = 1 C u i j m ∣ ∣ x i − c j ∣ ∣ 2 J_m = \sum^{N}_{i=1}{\sum^{C}_{j=1}{u_{ij}^m||x_i-c_j||^2}} Jm=i=1∑Nj=1∑Cuijm∣∣xi−cj∣∣2
- m是任何大于1的实数
- u i j u_{ij} uij是 x i x_i xi在类j上隶属度
- 其中 x i x_i xi是第i个d维测量向量
- c j c_j cj是一个d维的类中心
FCM主要通过迭代更新u和c来得到最终的解。
迭代终点一般选取两个:
- 当u变化的无穷范数小于某个值时
- 当迭代次数达到某个极限时候
这个过程可能会收敛到局部最小值或者是鞍点上
算法流程
- 初始化矩阵U (描述每个点在不同的类中的概率)
- 通过U算类中心
C j = ∑ i = 1 N u i j m ∗ x i ∑ i = 1 N u i j m C_j=\frac{\sum^{N}_{i=1}{u_{ij}^m * x_i}}{\sum^{N}_{i=1}{u_{ij}^m}} Cj=∑i=1Nuijm∑i=1Nuijm∗xi - 更新U,通过之前算出来的类中心
u i j = 1 ∑ k = 1 C ( ∣ ∣ x i − c j ∣ ∣ ∣ ∣ x i − c k ∣ ∣ ) 2 m − 1 u_{ij} = \frac{1}{\sum^{C}_{k=1}{(\frac{||x_i-c_j||}{||x_i-c_k||})^{\frac{2}{m-1}}}} uij=∑k=1C(∣∣xi−ck∣∣∣∣xi−cj∣∣)m−121 - 如果u变化的无穷范小于某个值的时候,就停下来,否者就转到第2步
Python 实现
import numpy as np def FCM(X, c_clusters=3, m=2, eps=10): membership_mat = np.random.random((len(X), c_clusters)) membership_mat = np.divide(membership_mat, np.sum(membership_mat, axis=1)[:, np.newaxis]) while True: working_membership_mat = membership_mat m Centroids = np.divide(np.dot(working_membership_mat.T, X), np.sum(working_membership_mat.T, axis=1)[:, np.newaxis]) n_c_distance_mat = np.zeros((len(X), c_clusters)) for i, x in enumerate(X): for j, c in enumerate(Centroids): n_c_distance_mat[i][j] = np.linalg.norm(x-c, 2) new_membership_mat = np.zeros((len(X), c_clusters)) for i, x in enumerate(X): for j, c in enumerate(Centroids): new_membership_mat[i][j] = 1. / np.sum((n_c_distance_mat[i][j] / n_c_distance_mat[i]) (2 / (m - 1))) if np.sum(abs(new_membership_mat - membership_mat)) < eps: break membership_mat = new_membership_mat return np.argmax(new_membership_mat, axis=1) - 终止条件那个可以再优化下,但基本框架就是这样。
使用:
- 导入数据:
from sklearn import datasets iris = datasets.load_iris() - 评估
def evaluate(y, t): a, b, c, d = [0 for i in range(4)] for i in range(len(y)): for j in range(i+1, len(y)): if y[i] == y[j] and t[i] == t[j]: a += 1 elif y[i] == y[j] and t[i] != t[j]: b += 1 elif y[i] != y[j] and t[i] == t[j]: c += 1 elif y[i] != y[j] and t[i] != t[j]: d += 1 return a, b, c, d def external_index(a, b, c, d, m): JC = a / (a + b + c) FMI = np.sqrt(a2 / ((a + b) * (a + c))) RI = 2 * ( a + d ) / ( m * (m + 1) ) return JC, FMI, RI def evaluate_it(y, t): a, b, c, d = evaluate(y, t) return external_index(a, b, c, d, len(y)) - 测试
test_y = FCM(iris.data) - 得到评估
evaluate_it(iris.target, test_y) 对于这三个指数来说,效果高了很多。
(0.98429, 0.2245, 0.48345)
- 画图
from sklearn.decomposition import PCA import numpy as np import matplotlib.pyplot as plt X_reduced = PCA(n_components=2).fit_transform(iris.data) plt.scatter(X_reduced[:, 0], X_reduced[:, 1], c=test_y, cmap=plt.cm.Set1) 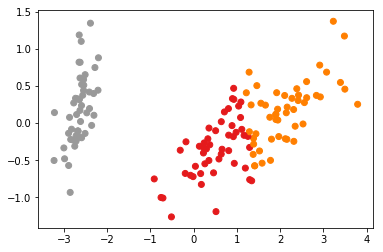

- 原图:
plt.scatter(X_reduced[:, 0], X_reduced[:, 1], c=iris.target, cmap=plt.cm.Set1) 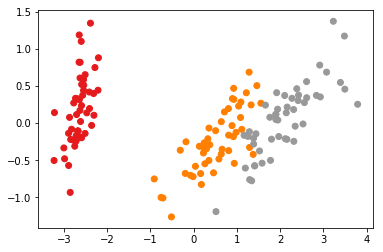
图片上也能看到效果比其他的都要好,而且,经过测试发现,FCM算法会比KMeans更加稳定(很多,很多倍)。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/212522.html原文链接:https://javaforall.net


