
目录
回归分析的主要算法包括:
- 线性回归(Linear Regression)
- 逻辑回归(Logistic regressions)
- 多项式回归(Polynomial Regression)
- 逐步回归(Step Regression)
- 岭回归(Ridge Regression)
- 套索回归(Lasso Regression)
- 弹性网回归(ElasticNet)
线性与非线性
- 线性:两个变量之间的关系是一次函数关系的——图象是直线,叫做线性。
注意:线性是指广义的线性,也就是数据与数据之间的关系。
- 非线性:两个变量之间的关系不是一次函数关系的——图象不是直线,叫做非线性。
那到底什么时候可以使用线性回归呢?统计学家安斯库姆给出了四个数据集,被称为安斯库姆四重奏。
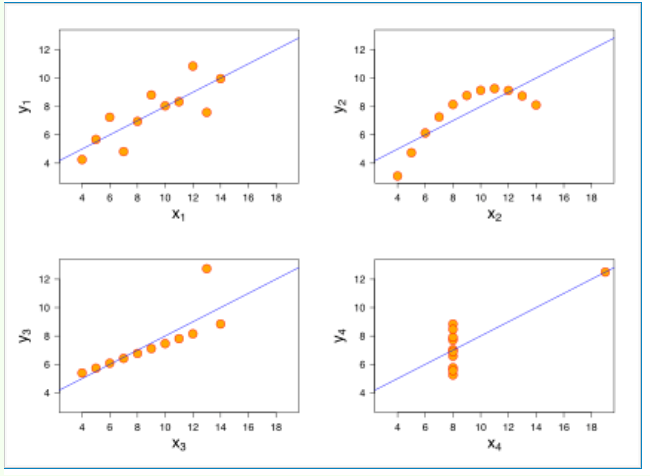

从这四个数据集的分布可以看出,并不是所有的数据集都可以用一元线性回归来建模。现实世界中的问题往往更复杂,变量几乎不可能非常理想化地符合线性模型的要求。因此使用线性回归,需要遵守下面几个假设:
- 线性回归是一个回归问题。
- 要预测的变量 y 与自变量
x的关系是线性的(图2 是一个非线性)。 - 各项误差服从正太分布,均值为0,与
x同方差(图4 误差不是正太分布)。 - 变量
x的分布要有变异性。 - 多元线性回归中不同特征之间应该相互独立,避免线性相关。
参考:

回归问题与分类问题
与回归相对的是分类问题(classification),分类问题要预测的变量y输出集合是有限的,预测值只能是有限集合内的一个。当要预测的变量y输出集合是无限且连续,我们称之为回归。比如,天气预报预测明天是否下雨,是一个二分类问题;预测明天的降雨量多少,就是一个回归问题。
变量之间是线性关系
线性通常是指变量之间保持等比例的关系,从图形上来看,变量之间的形状为直线,斜率是常数。这是一个非常强的假设,数据点的分布呈现复杂的曲线,则不能使用线性回归来建模。可以看出,四重奏右上角的数据就不太适合用线性回归的方式进行建模。
误差服从均值为零的正太分布
前面最小二乘法求解过程已经提到了误差的概念,误差可以表示为误差 = 实际值 - 预测值。
可以这样理解这个假设:线性回归允许预测值与真实值之间存在误差,随着数据量的增多,这些数据的误差平均值为0;从图形上来看,各个真实值可能在直线上方,也可能在直线下方,当数据足够多时,各个数据上上下下相互抵消。如果误差不服从均值为零的正太分布,那么很有可能是出现了一些异常值,数据的分布很可能是安斯库姆四重奏右下角的情况。
这也是一个非常强的假设,如果要使用线性回归模型,那么必须假设数据的误差均值为零的正太分布。
变量 x 的分布要有变异性
线性回归对变量 x也有要求,要有一定变化,不能像安斯库姆四重奏右下角的数据那样,绝大多数数据都分布在一条竖线上。
多元线性回归不同特征之间相互独立
如果不同特征不是相互独立,那么可能导致特征间产生共线性,进而导致模型不准确。举一个比较极端的例子,预测房价时使用多个特征:房间数量,房间数量*2,-房间数量等,特征之间是线性相关的,如果模型只有这些特征,缺少其他有效特征,虽然可以训练出一个模型,但是模型不准确,预测性差。
线性回归

参考链接:https://zhuanlan.zhihu.com/p/
多重共线性
在多元线性回归模型经典假设中,其重要假定之一是回归模型的解释变量之间不存在线性关系,也就是说,解释变量X1,X2,……,Xk中的任何一个都不能是其他解释变量的线性组合。如果违背这一假定,即线性回归模型中某一个解释变量与其他解释变量间存在线性关系,就称线性回归模型中存在多重共线性。严重的多重共线性可能会产生问题,因为它可以增大回归系数的方差,使它们变得不稳定。以下是不稳定系数导致的一些后果:
- 即使预测变量和响应之间存在显著关系,系数也可能看起来并不显著。
- 高度相关的预测变量的系数在样本之间差异很大。
- 从模型中去除任何高度相关的项都将大幅影响其他高度相关项的估计系数。高度相关项的系数甚至会包含错误的符号。
共线性出现的原因
多重共线性问题就是指一个解释变量的变化引起另一个解释变量地变化。
原本自变量应该是各自独立的,根据回归分析结果,能得知哪些因素对因变量Y有显著影响,哪些没有影响。如果各个自变量x之间有很强的线性关系,就无法固定其他变量,也就找不到x和y之间真实的关系了。除此以外,多重共线性的原因还可能包括:
- 数据不足。在某些情况下,收集更多数据可以解决共线性问题。
- 错误地使用虚拟变量。(比如,同时将男、女两个虚拟变量都放入模型,此时必定出现共线性,称为完全共线性)
共线性的判别指标
有多种方法可以检测多重共线性,较常使用的是回归分析中的VIF值,VIF值越大,多重共线性越严重。一般认为VIF大于10时(严格是5),代表模型存在严重的共线性问题。有时候也会以容差值作为标准,容差值=1/VIF,所以容差值大于0.1则说明没有共线性(严格是大于0.2),VIF和容差值有逻辑对应关系,两个指标任选其一即可。
除此之外,直接对自变量进行相关分析,查看相关系数和显著性也是一种判断方法。如果一个自变量和其他自变量之间的相关系数显著,则代表可能存在多重共线性问题。
如存在严重的多重共线性问题,可以考虑使用以下几种方法处理:
(1)手动移除出共线性的变量
先做下相关分析,如果发现某两个自变量X(解释变量)的相关系数值大于0.7,则移除掉一个自变量(解释变量),然后再做回归分析。此方法是最直接的方法,但有的时候我们不希望把某个自变量从模型中剔除,这样就要考虑使用其他方法。
(2)逐步回归法
让系统自动进行自变量的选择剔除,使用逐步回归将共线性的自变量自动剔除出去。此种解决办法有个问题是,可能算法会剔除掉本不想剔除的自变量,如果有此类情况产生,此时最好是使用岭回归进行分析。
(3)增加样本容量
增加样本容量是解释共线性问题的一种办法,但在实际操作中可能并不太适合,原因是样本量的收集需要成本时间等。
(4)岭回归
上述第1和第2种解决办法在实际研究中使用较多,但问题在于,如果实际研究中并不想剔除掉某些自变量,某些自变量很重要,不能剔除。此时可能只有岭回归最为适合了。岭回归是当前解决共线性问题最有效的解释办法。
常用的回归模型评估指标
- 解释方差( Explained variance score)
- 绝对平均误差(Mean absolute error)
- 均方误差(Mean squared error)
- 决定系数(R² score)
算法优缺点
优点:
(1)思想简单,实现容易。建模迅速,对于小数据量、简单的关系很有效;
(2)是许多强大的非线性模型的基础。
(3)线性回归模型十分容易理解,结果具有很好的可解释性,有利于决策分析。
(4)蕴含机器学习中的很多重要思想。
(5)能解决回归问题。
缺点:
(1)对于非线性数据或者数据特征间具有相关性多项式回归难以建模.
(2)难以很好地表达高度复杂的数据。
算法实现
简单的线性回归算法
import numpy as np import matplotlib.pyplot as plt x=np.array([1,2,3,4,5],dtype=np.float) y=np.array([1,3.0,2,3,5]) plt.scatter(x,y) x_mean=np.mean(x) y_mean=np.mean(y) num=0.0 d=0.0 for x_i,y_i in zip(x,y): num+=(x_i-x_mean)*(y_i-y_mean) d+=(x_i-x_mean)2 a=num/d b=y_mean-a*x_mean y_hat=a*x+b plt.figure(2) plt.scatter(x,y) plt.plot(x,y_hat,c='r') x_predict=4.8 y_predict=a*x_predict+b print(y_predict) plt.scatter(x_predict,y_predict,c='b',marker='+')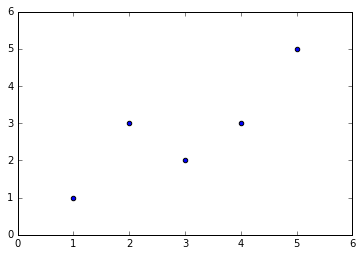
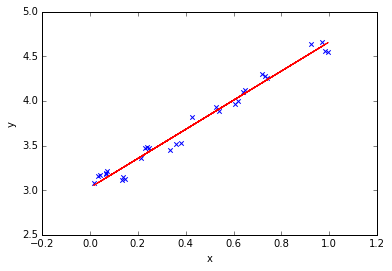
基于sklearn的简单线性回归
import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression # 线性回归 # 样本数据集,第一列为x,第二列为y,在x和y之间建立回归模型 data=[ [0.067732,3.],[0.,3.],[0.,4.],[0.,4.],[0.,4.], [0.,3.],[0.,3.],[0.033859,3.],[0.,3.],[0.,3.], [0.,3.],[0.,4.],[0.,4.],[0.,3.],[0.,4.], [0.,3.],[0.,3.],[0.,3.],[0.,4.094115],[0.,3.], [0.070237,3.],[0.067154,3.],[0.,4.],[0.,4.],[0.015371,3.085028], [0.,3.],[0.040486,3.],[0.,3.],[0.,3.],[0.,3.] ] #生成X和y矩阵 dataMat = np.array(data) X = dataMat[:,0:1] # 变量x y = dataMat[:,1] #变量y # ========线性回归======== model = LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False) model.fit(X, y) # 线性回归建模 print('系数矩阵:\n',model.coef_) print('线性回归模型:\n',model) # 使用模型预测 predicted = model.predict(X) plt.scatter(X, y, marker='x') plt.plot(X, predicted,c='r') plt.xlabel("x") plt.ylabel("y")
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/213063.html原文链接:https://javaforall.net


