
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
【服务器端】
1.下载redis ,Redis Desktop Managerredis。
2.修改配置文件(找到redis下的redis.windows.conf 双击打开,找到bind 并修改为0.0.0.0,然后 protected-mode “no”
3.打开cmd命令行 进入redis的安装目录,输入redis-server.exe redis.windows.conf 回车,保持程序一直开着。

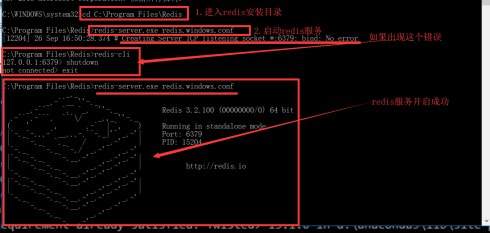
如果不是这个界面,证明redis服务已经开启了,需要
redis-cli shutdown
重新输入一次redis-server.exe redis.windows.conf
4.主机开启redis服务之后,不要断开,切记!!! 进入redis安装目录,输入:redis-cli.exe -h 主机(或者别人的)ip地址(-p 端口号6379(可以不用写)),也可以直接redis-cli -h 主机ip 地址用来测试是否可以远程连接redis(如果回车之后没有出现如图效果,检查自己的bind是否修改以及redis服务是否被自己关闭)出现如下表示可以远程连接redis

如果想要操作数据库连接中指定数据库(默认的是数据库0),比如操作数据库5可以在命令行输入:redis-cli -h 192.168.0.1 -n 5
详情参考:Redis在命令行中操作指定数据库下的key – 简书
5在Redis Desktop Managerredis中创建连接,一定要HOST设置成本机的ip,不要是127.0.0.1,要不然分机程序一运行就会一直停顿。
6,向redis输入链接,lpush bole:start_urls 网址
模板:lpush redis_keys 网址
![分布式爬虫部署[通俗易懂]](https://img-blog.csdnimg.cn/img_convert/1436747b8fb987dfbabb670741997945.png)
【爬虫端部署】
爬虫分两种流派,一种是有规则的,一种是无规则的。运行方式各有不通。
共同点:setting.py
LOG_LEVEL='DEBUG'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'dushu_redis (+http://www.yourdomain.com)'
#配置去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#配置调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
#setting.py
ROBOTSTXT_OBEY=False
DOWNLOAD_DELAY = 1
REDIS_URL = 'redis://root:@192.168.0.105:6379/0'
ITEM_PIPELINES = {
#'dushu_redis.pipelines.DushuRedisPipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400,
}(1)【有规则的爬虫】这里一定要开启爬虫过滤 ,否则在有些版本,无法过滤
def make_requests_from_url(self, url):
return scrapy.Request(url, dont_filter=False)
import scrapy
from scrapy.spiders import Rule
#from scrapy_redis.spiders import RedisSpider
from scrapy.linkextractors import LinkExtractor
from scrapy_redis.spiders import RedisCrawlSpider
class GuoxueSpider(RedisCrawlSpider):
name = 'bole'
# start_urls = ['http://blog.jobbole.com/all-posts/']
# 添加键
redis_key = 'bole:start_urls'
rules = (
# follow all links
Rule(LinkExtractor(), callback='parse_page', follow=True),
)
def __init__(self, *args, **kwargs):
# Dynamically define the allowed domains list.
domain = kwargs.pop('domain', '')
self.allowed_domains = filter(None, domain.split(','))
super(GuoxueSpider, self).__init__(*args, **kwargs)
def make_requests_from_url(self, url):
return scrapy.Request(url, dont_filter=False)
def parse_page(self, response):
aa=response.css('title::text').extract_first()
print(aa)
return {
'name': response.css('title::text').extract_first(),
'url': response.url,
}运行方式 在爬虫的根目录运行scrapy crawl 爬虫名
(2)【无规则的爬虫】
from scrapy_redis.spiders import RedisSpider
class GuoxuespiderSpider(RedisSpider):
"""Spider that reads urls from redis queue (myspider:start_urls)."""
name = 'myspider'
redis_key = 'bole:start_urls'
def __init__(self, *args, **kwargs):
# Dynamically define the allowed domains list.
domain = kwargs.pop('domain', '')
self.allowed_domains = filter(None, domain.split(','))
super(GuoxuespiderSpider, self).__init__(*args, **kwargs)
def make_requests_from_url(self, url):
return scrapy.Request(url, dont_filter=False)
def parse(self, response):
aa=response.css('title::text').extract_first()
print(aa)
return {
'name': response.css('title::text').extract_first(),
'url': response.url,
}
运行方式:
![分布式爬虫部署[通俗易懂]](https://img-blog.csdnimg.cn/img_convert/56890cb5d0d9a4780dace6a6ab88b46f.png)
Redis DeskTop Manager 使用教程 – King-DA – 博客园
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/213742.html原文链接:https://javaforall.net


