
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
校验和思路
首先,IP、ICMP、UDP和TCP报文头都有检验和字段,大小都是16bit,算法基本上也是一样的。
在发送数据时,为了计算数据包的检验和。应该按如下步骤:
1、把校验和字段设置为0;
2、把需要校验的数据看成以16位为单位的数字组成,依次进行二进制反码求和;
3、把得到的结果存入校验和字段中
在接收数据时,计算数据包的检验和相对简单,按如下步骤:
1、把首部看成以16位为单位的数字组成,依次进行二进制反码求和,包括校验和字段;
2、检查计算出的校验和的结果是否为0;
3、如果等于0,说明被整除,校验和正确。否则,校验和就是错误的,协议栈要抛弃这个数据包。
虽然说上面四种报文的校验和算法一样,但是在作用范围存在不同:IP校验和只校验20字节的IP报头;而ICMP校验和覆盖整个报文(ICMP报头+ICMP数据);UDP和TCP校验和不仅覆盖整个报文,而且还有12个字节的IP伪首部,包括源IP地址(4字节)、目的IP地址(4字节)、协议(2字节)、TCP/UDP包长(2字节)。另外UDP、TCP数据报的长度可以为奇数字节,所以在计算校验和时需要在最后增加填充字节0(填充字节只是为了计算校验和,可以不被传送)。
校验和计算方法:
对一个无符号的数,先求其反码,然后从低位到高位,按位相加,有益处则向高位进1(和一般的二进制法则一样),若最高位有进位,则向最低位进1.
特点:关于二进制反码循环移位求和运算需要说明的一点是,先取反后相加与先相加后取反,得到的结果是一样的。
可结合性和可交换性
用A,B,C,D,E,F分别表示一个8位的二进制数(一个字节),用[A, B]这样的形式表示A*256+B,那么16位校验和可以用个如下形式给出
sum = [A,B]+’[C,D]+’[E,F];
其中, +’被表示二进制循环移位加法
可结合性:[A,B]+’[C,D]+’[E,F] = [A,B]+’([C,D]+’[E,F])
可交换性:[A,B]+’[C,D]+’[E,F] = [C,D]+’[A,B]+’[E,F]
字节自主性
[A,B]+’[C,D]+’[E,F] = [B,A]+’([D,C]+’[F,E])
由于若最高位有进位,则向最低位进1 这样的特性,第15位到0位进位,第7位向第8位进位,所以,整个求和结果是一样的。
并行计算
有些机器的字处理长度是16的倍数,这样可以提高他的计算速度,由于可结合行,那么32位机器可以[A,B,C,D]+’…进行32校验和。
为什么使用二进制反码循环移位加法呢?
我们知道,计算机中有原码,反码,补码,为什么要使用二进制反码来计算校验和呢,而不是直接使用原码或者是补码呢?
二进制反码循环移位加法求和优点
-
不依赖系统是大端小端。即无论你是发送方计算机或者接收方检查校验和时,都不要调用htons或者ntohs,直接通过上面的算法就可以得到正确的结果。这个问题你可以自己举个例子,用反码求和时,交换16位数的字节顺序,得到的结果相同,只是字节顺序相应地也交换了;而如果使用原码或者补码求和,得到的结果可能就不同。
-
计算和验证校验和比较简单、快递。
举例:
对于一串16进制数据:0001f203f4f5f6f7

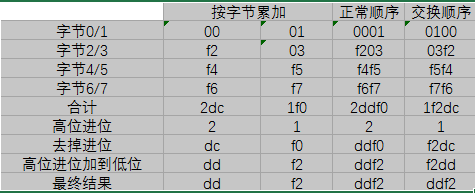
正常顺序是将高8位*256之后,即将高位向左移动8位,加上低8位,交换顺序反之
可以明显得到,二进制反码循环移位加法与字节序无关。
代码:
#include<iostream>
#include<cstdio>
#include<cstdlib>
#include<cstring>
using namespace std;
void main(int argc, char *argv[])
{
FILE *fp;
char ch;
unsigned char LowChar, HighChar;
unsigned int count = 0, checksum = 0, byte = 0;
unsigned long int sum = 0;
//打开文件文本
if ((fp = fopen("I:\\1.txt", "r")) == NULL)
{
printf("File cannot be opened!");
system("pause");
return;
}
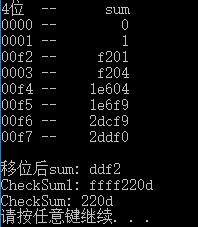
printf("4位 -- sum\n");
//从文本中读取字符
while(1)
{
if ((ch = fgetc(fp))!=EOF)
{
count++; //从1开始计数
if (ch != ' ')
{
//将一个16进制字符转化为整形
if (ch >= '0' && ch <= '9')
{
ch -= '0';
}
else if (ch >= 'a' && ch <= 'f')
{
ch = ch-'a'+10;
}
else if(ch >= 'A' && ch <= 'F')
{
ch = ch-'A'+ 10;
}
//计算8字节的累加值
if (count%2 == 1)
{
HighChar = ch << 4; //作为一个字节的高四位
}
else
{
LowChar = ch & 0x0f; //作为一个字节的低四位
byte = HighChar|LowChar;//构成一个字节
//16位并行计算
if (count % 4 == 2) //高8位与sum相加
{
sum += byte << 8;
}
else if(count % 4 == 0) //低8位与sum相加
{
sum += byte;
}
printf("%04x -- %8lx \n", byte, sum);
}
}
else
{
count--;
}
}
else
{
break;
}
}
//如果16位sum产生进位,将进位移加到低位
if ( sum >> 16)
{
checksum = ~(long(sum>>16)+long(sum&0x0000ffff));
}
printf("\n移位后sum: %x", (long(sum>>16)+long(sum&0x0000ffff)));
printf("\nCheckSum1: %x", checksum);
//避免再次进位
checksum = checksum&0x0000ffff;
//输出校验和
printf("\nCheckSum: %x\n", checksum);
system("pause");
}运行结果
参考博客:传送门
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/214282.html原文链接:https://javaforall.net


