
初识linux操作系统,fork作为系统调用理解起来却并不是很容易。
代码能说明问题
#include
接下来问题就来了
fork的时候发生什么?
①执行到这一句的时候,一个进程被创建了,这个进程与父进程一样,拥有一套与父进程相同的变量,相同的一套代码,这里可以粗浅的理解为子进程又复制了一份main函数。这里返回一个子进程的进程号,大于0。(第一次fork)
②子进程怎么执行:
子进程从fork()的位置开始执行,也就是说前面的代码不走,但是拥有之前的变量以及变量的值,与父进程的值一样,这次fork(),返回值是0,所以在子进程里面直接执行了pid==0这一个分支,父进程里面并不执行这个分支的语句。这就为我们在写mian函数的时候怎么写子进程的程序提供了一个方法来隔离代码。
明白了这个原理之后我们再来看一段代码
#include
#include
int main() { pid_t pid[3]; int count = 0; pid[0] = fork(); pid[1] = fork(); pid[2] = fork(); printf("this is process\n"); return 0; }
运行结果

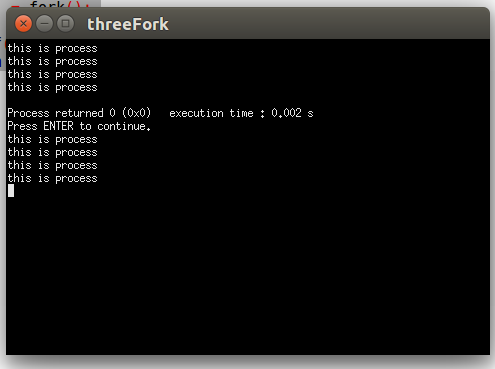
这里每一次输出表示一个进程的创建,可以看到一共有8个进程被创建,有兴趣的话可以验证一下连续四次fork可以出16个进程,但是不建议再多了,电脑会卡死,不要问我怎么知道的!
猜想是出2的n次方个进程。如果上面的第一段代码理解了的话,我们按照子进程从父进程fork的位置开始执行就会理解为什么会有八个进程。
这里附上思维导图助于理解
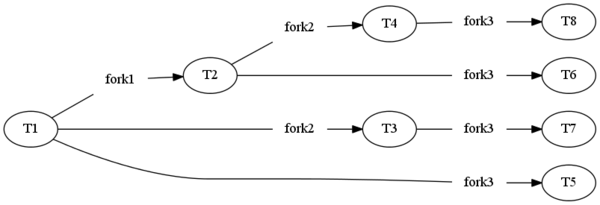
那么我们想创建不是2的n次方个进程应该怎么做呢?这里还是以三个为例
#include
#include
#include
int main(int argc, char *argv[]) { int i,j,status; int pid[3]; for(i=0; i<3;i++){ if((pid[i]=fork()) >0){ printf("This is child process pid=%d\n",pid[i]); } else{ printf("This is father process pid=%d\n",pid[i]); exit( EXIT_SUCCESS); } } return EXIT_SUCCESS; }
这里给出一个参考,不是最准确的,可以与三次fork进行对比。
以上是原文
(因为要找工作了,被迫重新复习了一下fork )
参考游双的《linux高性能服务器编程》
fork的时候
子进程的代码与父进程完全相同,同时它还会复制父进程的数据(堆数据、栈数据和静态数据)。数据的复制采用的是所谓的写时复制( copy on writte ),即只有在任一进程(父进程或子进程)对数据执行了写操作时,复制才会发生(先是缺页中断,然后操作系统给子进程分配内存并复制父进程的数据)。即便如此,如果我们在程序中分配了大量内存,那么使用fork时也应当十分谨慎,尽量避免没必要的内存分配和数据复制。
此外,创建子进程后,父进程中打开的文件描述符默认在子进程中也是打开的,且文件描述符的引用计数加1。不仅如此,父进程的用户根目录、当前工作目录等变量的引用计数均会加1。
所以子进程复制了父进程的代码段,并且程序拷贝了程序计数器,所以我们看到的子进程和父进程执行了相同的代码,有没有一种办法,可以让子进程执行自己的代码呢,是可以的,可以使用exec函数,将想执行的进程替换进来,然后exec函数会调用你载入进程的main函数。
感谢阅读!
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/214427.html原文链接:https://javaforall.net


