
从图中某一顶点出发访遍图中其余顶点,且使每一个顶点仅被访问一次,这一过程就叫做图的遍历(Traversing Graph)
访问过的顶点打上标记,避免访问多次而不自知;可以通过设置一个访问数组visited[n],n是图中顶点个数,初值为0,访问之后设置为1
图遍历要避免因回路陷入死循环,通常有两种遍历次序方案:
- 深度优先遍历
- 广度优先遍历
深度优先遍历
深度优先遍历(Depth_First_Search),也有称为深度优先搜索,简称DFS
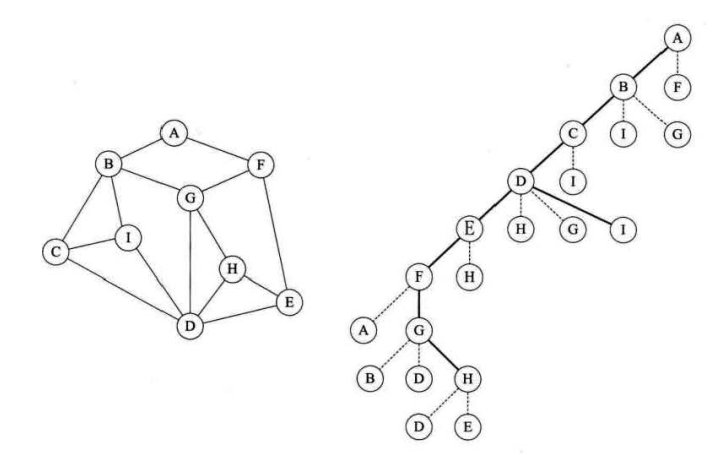

如上图,如何从顶点A开始走遍所有的图顶点并作上标记?
从顶点A开始,始终向右手边走,注意,走到最后,还有一个I顶点没走。
深度优先遍历其实就是一个递归的过程,从图右边路径可以看出类似一棵树的前序遍历,确实如此。
从图中某个顶点v出发,访问此顶点,然后从v的未被访问的邻接点出发深度优先遍历图,直至图中所有和v有路径想通的顶点都被访问到。
非连通图,只需要对它的连通分量分别进行深度优先遍历,即在先前一个顶点进行一次深度优先遍历后,若图中尚有顶点未被访问,则选图中一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
邻接矩阵深度优先遍历
/ * 邻接矩阵的深度优先遍历(注意I点的遍历比较特殊) * @author jiaxinxiao * @date 2019年12月28日 */ public class DFSTest { Boolean[] visited = new Boolean[9]; //邻接矩阵的深度优先递归算法 void DFS(Graph graph,int i){ int j; visited[i] = true; System.out.println(graph.verxs[i]);//打印顶点,也可以进行其他操作 for(j = 0;j
邻接表深度优先遍历
//邻接表深度优先递归算法 void DFS(GraphAdjList gl,int i){ EdgeNode p = null; visited[i] = true; System.out.println(gl.vertexNodes[i].data);//打印顶点 p = gl.vertexNodes[i].firstEdge; while(p != null){ if(!visited[p.next.adjvex]){ DFS(gl, p.next.adjvex); } p = p.next; } } //邻接表的深度遍历操作 void DFSTraverse(GraphAdjList gl){ int i; for(i = 0;i
总结:两个不同存储结构深度优先遍历算法
- 邻接矩阵是二维数组,要查找每个顶点的邻接点需要访问矩阵中的元素,因此需要O(n^2)的时间
- 邻接表做存储结构,需要时间取决于顶点和边的数量,所以是O(n+e)
显然对于点多边少的稀疏图来说,邻接表结构使得算法在时间效率上大大提高。
广度优先遍历
广度优先遍历(Breadth First Search),又称广度优先搜索,简称BFS。
深度优先遍历未必是最佳方案,它意味着要彻底查找完一个地方,然后才查找另一个地方。
DFS类似于树的前序遍历,BFS类似于树的层序遍历。
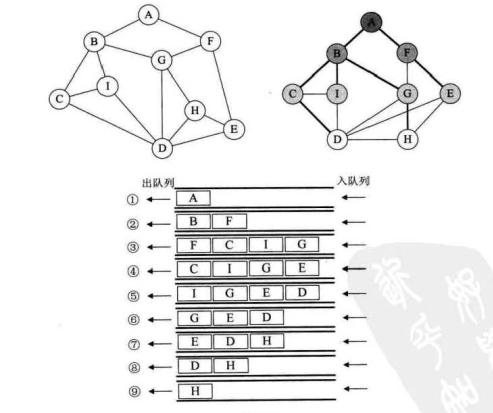
如上图所示,顶点A作为第一层,A的所有边顶点BF作为第二层,BF的所有边顶点CIGE作为第三层,依次类推。
邻接矩阵广度优先遍历
//邻接矩阵广度遍历算法 void BFSTraverse(Graph g){ int i,j; Queue
q; for(i=0;i
(); for(i=0;i
邻接表广度优先遍历
//邻接表广度遍历算法 void BFSTraverse(GraphAdjList g){ int i; EdgeNode p; Queue
q; for(i=0;i
(); for(i=0;i
总结
两种遍历时间复杂度是相同的,不同的是对顶点的访问顺序不同。
两种算法没有优劣之分,视不同的情况选择不同的算法。
- 深度优先更适合目标比较明确,以找到目标为主要目的的情况
- 广度优先更适合在不断扩大遍历范围时找到相对最优解的情况
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/215273.html原文链接:https://javaforall.net


