
1、haystack简介
Haystack是django的开源全文搜索框架(全文检索不同于特定字段的模糊查询,使用全文检索的效率更高 ),该框架支持
Solr,Elasticsearch,Whoosh, Xapian,搜索引擎它是一个可插拔的后端(很像Django的数据库层),所以几乎你所有
写的代码都可以在不同搜索引擎之间便捷切换;
– 全文检索不同于特定字段的模糊查询,使用全文检索的效率更高,并且能够对于中文进行分词处理;
– haystack:django的一个包,可以方便地对model里面的内容进行索引、搜索,设计为支持whoosh,solr,
Xapian,Elasticsearc四种全文检索引擎后端,属于一种全文检索的框架;
– whoosh:纯Python编写的全文搜索引擎,虽然性能比不上sphinx、xapian、Elasticsearc等,但是无二进制包,
程序不会莫名其妙的崩溃,对于小型的站点,whoosh已经足够使用;
– jieba:一款免费的中文分词包,如果觉得不好用可以使用一些收费产品;
2、安装
pip3 install django-haystack
pip3 install whoosh
pip3 install jieba #pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple jieba
3、配置
1)添加Haystack到 INSTALLED_APPS:
跟大多数Django的应用一样,你应该在你的设置文件(通常是settings.py)添加Haystack到INSTALLED_APPS. 示例:
INSTALLED_APPS =[‘django.contrib.admin‘,‘django.contrib.auth‘,‘django.contrib.contenttypes‘,‘django.contrib.sessions‘,‘django.contrib.sites‘,#添加
‘haystack‘,# 你的app‘app‘,
]
2)修改settings.py
在你的settings.py中,你需要添加一个设置来指示站点配置文件正在使用的后端,以及其它的后端设置。
HAYSTACK——CONNECTIONS是必需的设置,并且应该至少是以下的一种:Solr示例
HAYSTACK_CONNECTIONS ={‘default‘: {‘ENGINE‘: ‘haystack.backends.solr_backend.SolrEngine‘,‘URL‘: ‘http://127.0.0.1:8983/solr‘
#…or for multicore…
#‘URL‘: ‘http://127.0.0.1:8983/solr/mysite‘,
},
}
Elasticsearch示例
HAYSTACK_CONNECTIONS ={‘default‘: {‘ENGINE‘: ‘haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine‘,‘URL‘: ‘http://127.0.0.1:9200/‘,‘INDEX_NAME‘: ‘haystack‘,
},
}
Whoosh示例
#需要设置PATH到你的Whoosh索引的文件系统位置
importos
HAYSTACK_CONNECTIONS={‘default‘: {‘ENGINE‘: ‘haystack.backends.whoosh_backend.WhooshEngine‘,‘PATH‘: os.path.join(os.path.dirname(__file__), ‘whoosh_index‘),
},
}#自动更新索引
HAYSTACK_SIGNAL_PROCESSOR = ‘haystack.signals.RealtimeSignalProcessor‘
Xapian示例
#首先安装Xapian后端(http://github.com/notanumber/xapian-haystack/tree/master)#需要设置PATH到你的Xapian索引的文件系统位置。
importos
HAYSTACK_CONNECTIONS={‘default‘: {‘ENGINE‘: ‘xapian_backend.XapianEngine‘,‘PATH‘: os.path.join(os.path.dirname(__file__), ‘xapian_index‘),
},
}
4、处理数据
创建索引
models.py
from django.db importmodels#Create your models here.
classArticle(models.Model):
title= models.CharField(max_length=32)
desc= models.CharField(max_length=128)
contend= models.TextField()
如果你想针对某个app例如app做全文检索,则必须在blog的目录下面建立search_indexes.py文件,文件名不能修改;
from haystack importindexesfrom app01.models importArticleclassArticleIndex(indexes.SearchIndex, indexes.Indexable):#类名必须为需要检索的Model_name+Index,这里需要检索Article,所以创建ArticleIndex
text = indexes.CharField(document=True, use_template=True)#创建一个text字段
其它字段
#desc = indexes.CharField(model_attr=‘desc‘)
#content = indexes.CharField(model_attr=‘content‘)
def get_model(self):#重载get_model方法,必须要有!
returnArticledef index_queryset(self, using=None):return self.get_model().objects.all()
为什么要创建索引?索引就像是一本书的目录,可以为读者提供更快速的导航与查找。在这里也是同样的道理,
当数据量非常大的时候,若要从这些数据里找出所有的满足搜索条件的几乎是不太可能的,将会给服务器带来极大的负担。
所以我们需要为指定的数据添加一个索引(目录),在这里是为Note创建一个索引,索引的实现细节是我们不需要关心的,
至于为它的哪些字段创建索引,怎么指定 ,下面开始讲解;
每个索引里面必须有且只能有一个字段为 document=True,这代表haystack 和搜索引擎将使用此字段的内容作为索引进行
检索(primary field)。其他的字段只是附属的属性,方便调用,并不作为检索数据
注意:如果使用一个字段设置了document=True,则一般约定此字段名为text,这是在ArticleIndex类里面一贯的命名,
以防止后台混乱,当然名字你也可以随便改,不过不建议改。
另外,我们在text字段上提供了use_template=True。这允许我们使用一个数据模板(而不是容易出错的级联)来构建文档
搜索引擎索引。你应该在模板目录下建立新的模板search/indexes/blog/article_text.txt,并将下面内容放在里面。
#在目录“templates/search/indexes/应用名称/”下创建“模型类名称_text.txt”文件
{
{ object.title}}
{
{ object.desc }}
{
{ object.content }}
此数据模板的作用是对Article表中的三个字段建立索引,当检索的时候会对这三个字段做全文检索匹配;
5、设置视图
1)先设置路由:
from django.conf.urls importurl, includefrom django.contrib importadminfrom app01 importviews
urlpatterns=[
url(r‘^admin/‘, admin.site.urls),
url(r‘^search/‘, include(‘haystack.urls‘)), #路由
]
2)设置搜索模板:
templates/search/search.html
}
{% if query %}
搜索结果如下:
{% for result in page.object_list %}
{
{ result.object.content|safe }}
{#
{% highlight result.object.content with query %}
#}{% empty %}
啥也没找到
{% endfor %}
{% if page.has_previous or page.has_next %}
{% if page.has_previous %}{% endif %}
|
{% if page.has_next %}{% endif %}下一页 »{% if page.has_next %}{% endif %}
{% endif %}
{% endif %}
需要注意的是page.object_list实际上是SearchResult对象的列表。这些对象返回索引的所有数据。它们可以
通过{
{result.object}}来访问。所以{
{ result.object.title}}实际使用的是数据库中Article对象来访问title字段的。
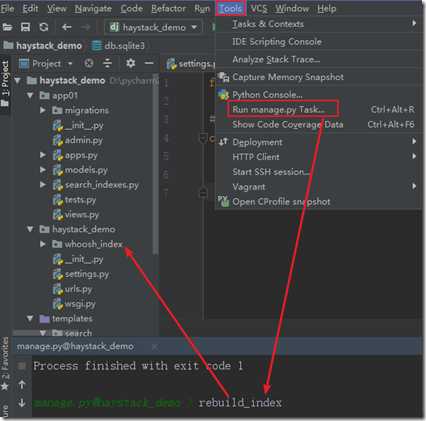
3)重建索引
现在你已经配置好了所有的事情,是时候把数据库中的数据放入索引(放入whoosh)了。Haystack附带的一个命令行管理工具使它变得很容易。
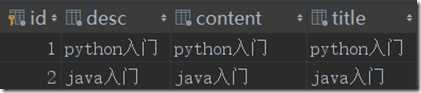
先在article表中插入两条数据,再执行数据库迁移:

然后运行 rebuild_index
6、使用jieba分词
1)建立ChineseAnalyzer.py文件
把新建的ChineseAnalyzer.py文件保存在haystack的安装文件夹下,路径如“D:python3Libsite-packageshaystackackends”
importjiebafrom whoosh.analysis importTokenizer, TokenclassChineseTokenizer(Tokenizer):def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode=‘‘, kwargs):
t= Token(positions, chars, removestops=removestops, mode=mode,kwargs)
seglist= jieba.cut(value, cut_all=True)for w inseglist:
t.original= t.text =w
t.boost= 1.0
ifpositions:
t.pos= start_pos +value.find(w)ifchars:
t.startchar= start_char +value.find(w)
t.endchar= start_char + value.find(w) +len(w)yieldtdefChineseAnalyzer():return ChineseTokenizer()
2)复制同目录下的whoosh_backend.py文件,改名为whoosh_cn_backend.py
注意:文件名不要写错
whoosh_backend.py和whoosh_cn_backend.py两个文件更改内容如下:
#导模块
from .ChineseAnalyzer importChineseAnalyzer#查找
analyzer=StemmingAnalyzer()#改为
analyzer=ChineseAnalyzer()
7、在模板中创建搜索栏
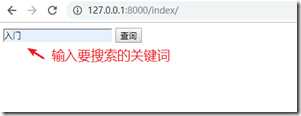
在templates下创建index.html
启动项目,然后在浏览器中输入:http://127.0.0.1:8000/index
8、其他配置
增加更多变量
from haystack.views importSearchViewfrom .models import *
classMySeachView(SearchView):def extra_context(self): #重载extra_context来添加额外的context内容
context =super(MySeachView,self).extra_context()
side_list= Topic.objects.filter(kind=‘major‘).order_by(‘add_date‘)[:8]
context[‘side_list‘] =side_listreturncontext#路由修改
url(r‘^search/‘, search_views.MySeachView(), name=‘haystack_search‘),
高亮显示
{% highlight result.summary with query %}
# 这里可以限制最终{
{ result.summary }}被高亮处理后的长度
{% highlight result.summary with query max_length 40 %}
#html中
}
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/217379.html原文链接:https://javaforall.net


