
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
机器学习中的k均值聚类属于无监督学习,所谓k指的是簇类的个数,也即均值向量的个数。算法初始状态下,要根据我们设定的k随机生成k个中心向量,随机生成中心向量的方法既可以随机从样本中抽取k个样本作为中心向量,也可以将中心向量固定在样本的维度范围之内,避免中心向量过偏远离大多数样本点。然后每个样本点需要与k个中心向量分别计算欧氏距离,取欧氏距离最小的中心向量作为该样本点的簇类中心,当第一轮迭代完成之后,中心向量需要更新,更新的方法是每个中心向量取前一次迭代所得到各自簇类样本点的均值,故称之为均值向量。迭代终止的条件是,所有样本点的簇类中心都不在发生变化。
在spss中导入的二维数据如下所示:
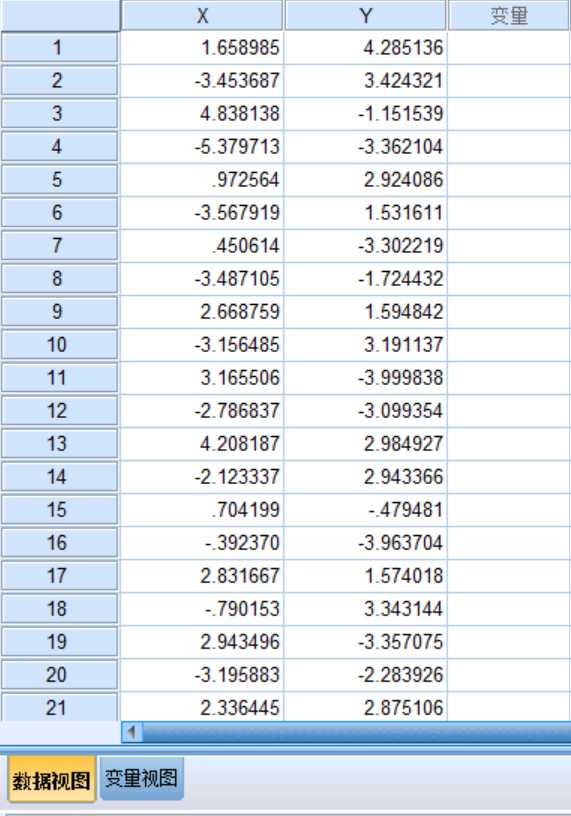

点击菜单栏的“分析”,找到“分类”选中“k-均值聚类”
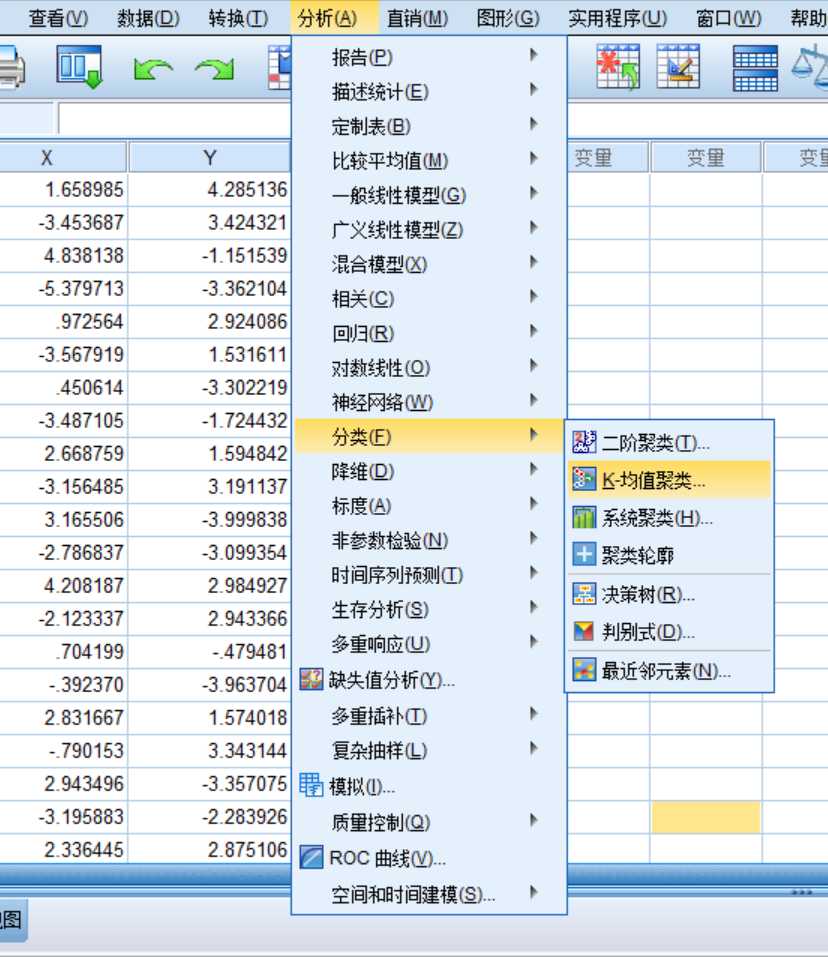
将需要进行聚类的变量选入右侧框中
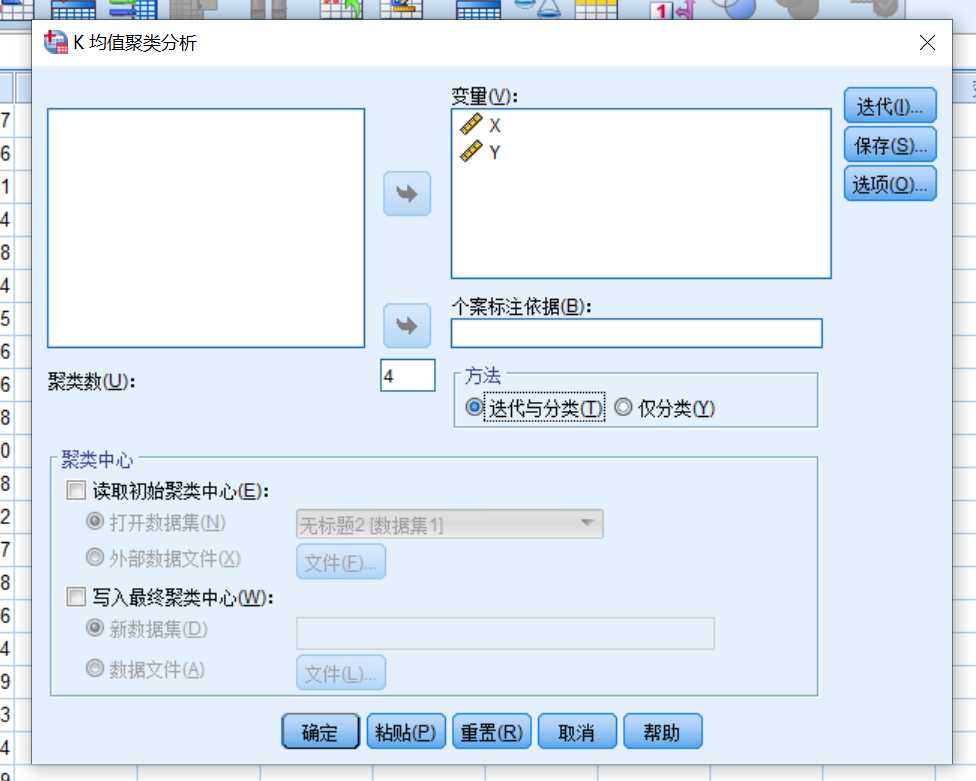
聚类数由用户设定,方法一般选择“迭代与分类”,“读取初始聚类中心”和“写入最终聚类中心”一般不勾选,除非自定义的聚类中心(自定义聚类中心一般意义不大),如果最后想将最终迭代得到的聚类中心写入指定文件,那么可以勾选第二个复选框。
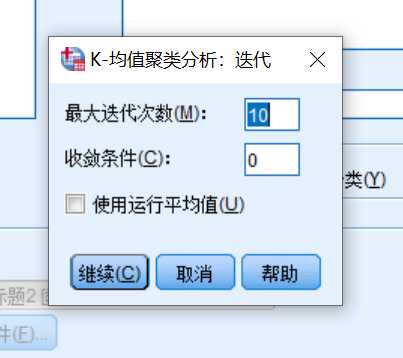
设定迭代次数,收敛条件默认为0,即当前均值向量与前一次迭代得到的均值向量之差。
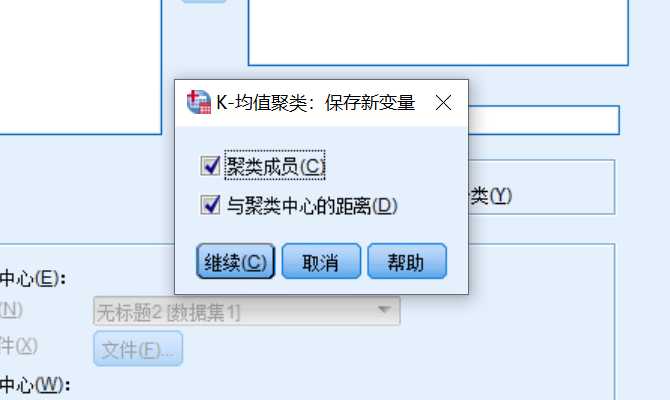
保存按钮,勾选以上复选框,最终得到的结果会包含以上两个信息。
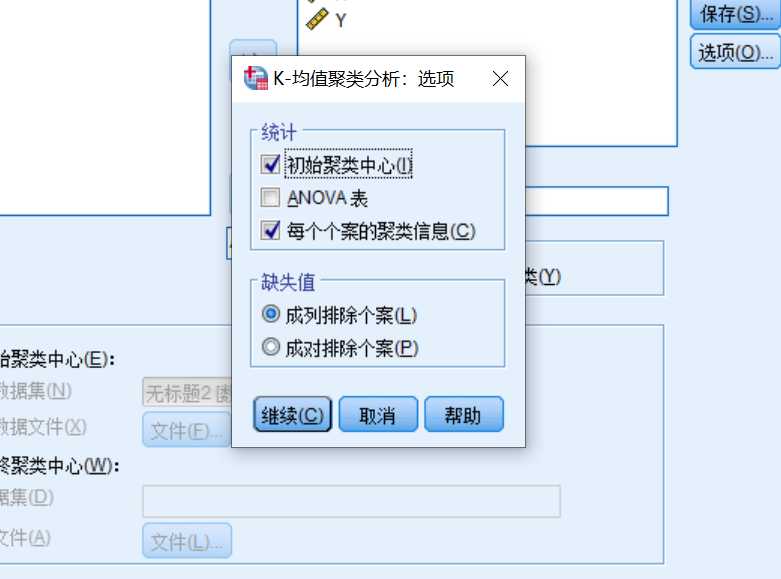
选项按钮中,一般勾选以上复选框,spss会统计出初始聚类的中心向量以及每个样本的聚类信息(包括每个样本所属类别,与各自簇类中心向量的欧氏距离)。之后,点击“确定”按钮,完成均值聚类。
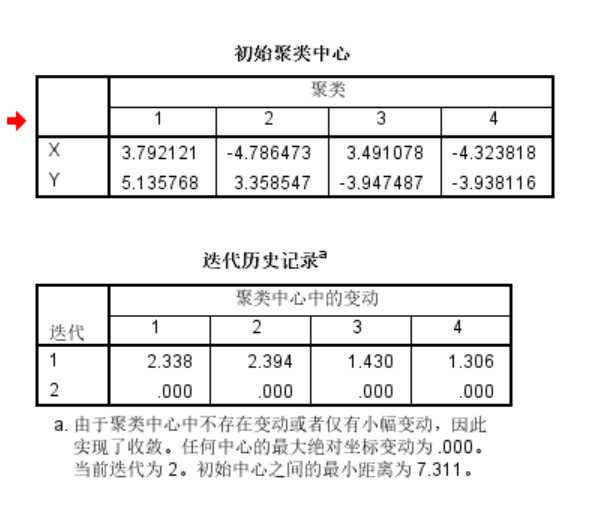
得到初始聚类中心和迭代历史记录,我们发现第二次迭代的时候,聚类中心就已经不变了。
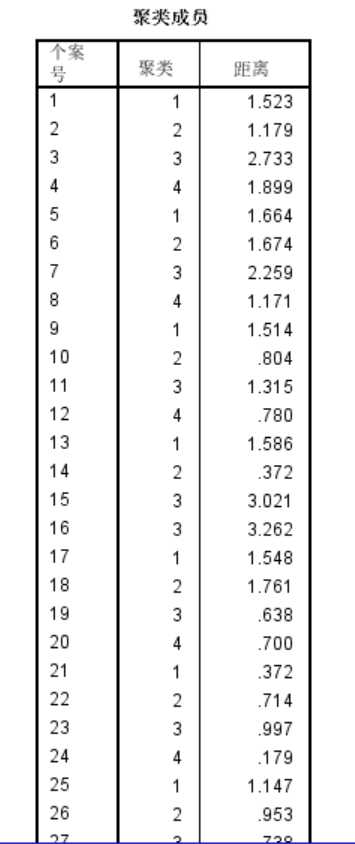
以下是每个样本所属类别以及每个样本与各自簇类中心的欧氏距离。

以上是最终得到的聚类中心的横纵坐标,以及聚类中心与中心之间的欧氏距离、每个类别中的样本数量。
以下是通过python编程实现k-均值聚类算法所得结果:
最终得到的聚类中心:
[[ 2.6265299 3.10868015]
[-2.46154315 2.78737555]
[-3.53973889 -2.89384326]
[ 2.65077367 -2.79019029]]
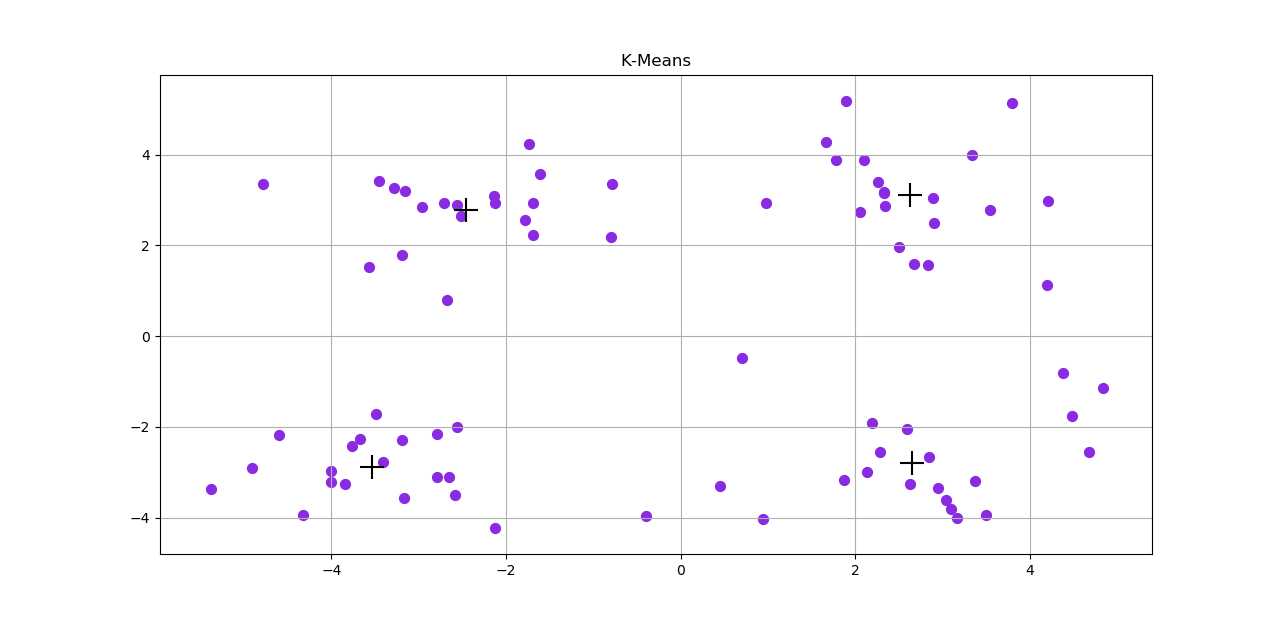
显然,与spss得到的聚类结果是一样的。
关于均值聚类的簇类数(即k值),目前并没有方法能确切地确定k的值是多少,但是通常可以通过枚举法和肘方法来大致确定k。
所谓枚举法,即通过取不同的k值来观察最终的聚类结果,选取最优结果所对应的k作为该均值聚类的最终k值。
肘方法是通过绘制不同的k所对应的样本数据点与各自聚类中心的距离平均值来确定k。
import numpy as np
from sklearn.cluster import KMeans
from scipy.spatial.distance import cdist
import matplotlib.pyplot as plt
cluster1 = np.random.uniform(0.5, 2.0, (2, 15))
cluster2 = np.random.uniform(2.5, 4.0, (2, 15))
X = np.hstack((cluster1, cluster2)).T
fig = plt.figure()
ax1 = fig.add_subplot(121)
plt.scatter(X[:, 0], X[:, 1], marker="^", color='m', edgecolors='k', alpha=0.8, s=50)
plt.title("Raw data")
K = range(1, 10)
meandistortions = []
for k in K:
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
meandistortions.append(sum(np.min(cdist(X, kmeans.cluster_centers_, 'euclidean'), axis=1)) / X.shape[0])
ax2 = fig.add_subplot(122)
plt.plot(K, meandistortions, 'bx-')
plt.xlabel('number of clusters K', fontsize=15)
plt.ylabel('Average distance to centroid', fontsize=15)
plt.title('Elbow for KMeans clustering');
plt.show()
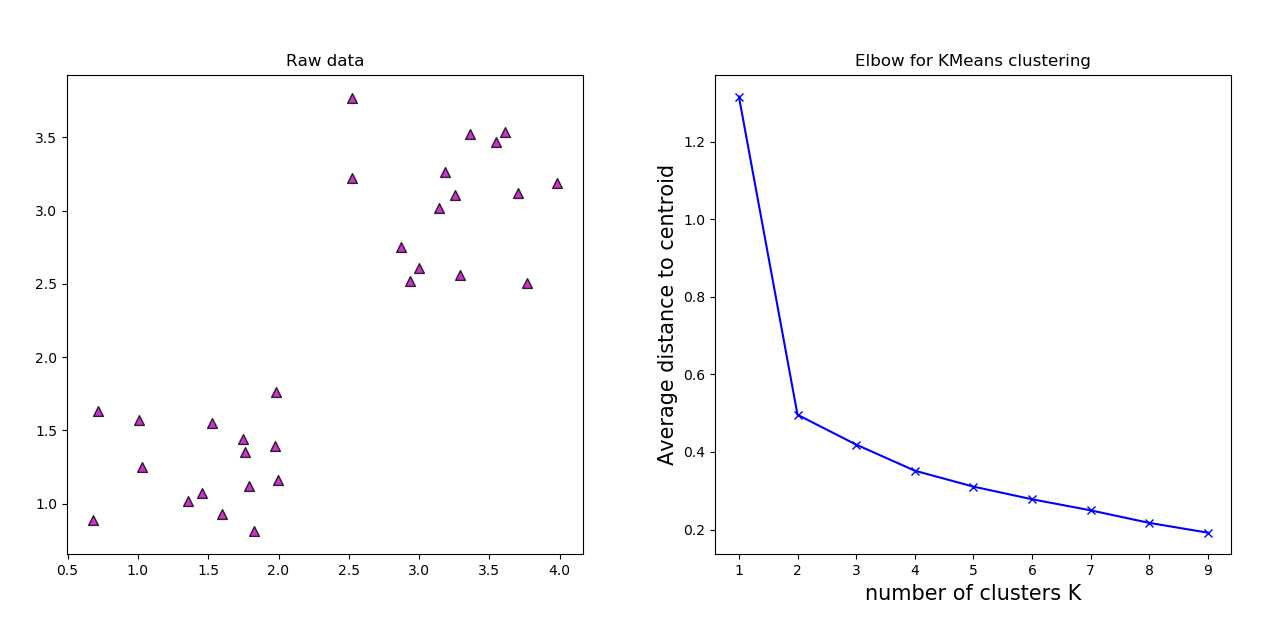
通过左图我们发现该样本数据集明显应该分为两个簇类,即k=2,当然如果在复杂数据集的情况下我们可能无法用右眼直接看出簇类数,此时就要借助右图的肘方法,即选取某一点该点的前一点至该点下降最快,而该点至该点的后一个点缓慢下降的点所对应的横轴作为均值聚类的k值。 右图由于曲线长得像人的手臂,而且寻找的点又恰好在“肘部”,故称为肘方法。但是有些情况下的曲线不一定是上述所说的手臂形状,此时无法寻找到“肘部”,所以肘方法不一定对所有数据集都适用。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/219249.html原文链接:https://javaforall.net


