
参考博客——tensorflow-TFRecord 文件详解
1. 生成tfrecord文件
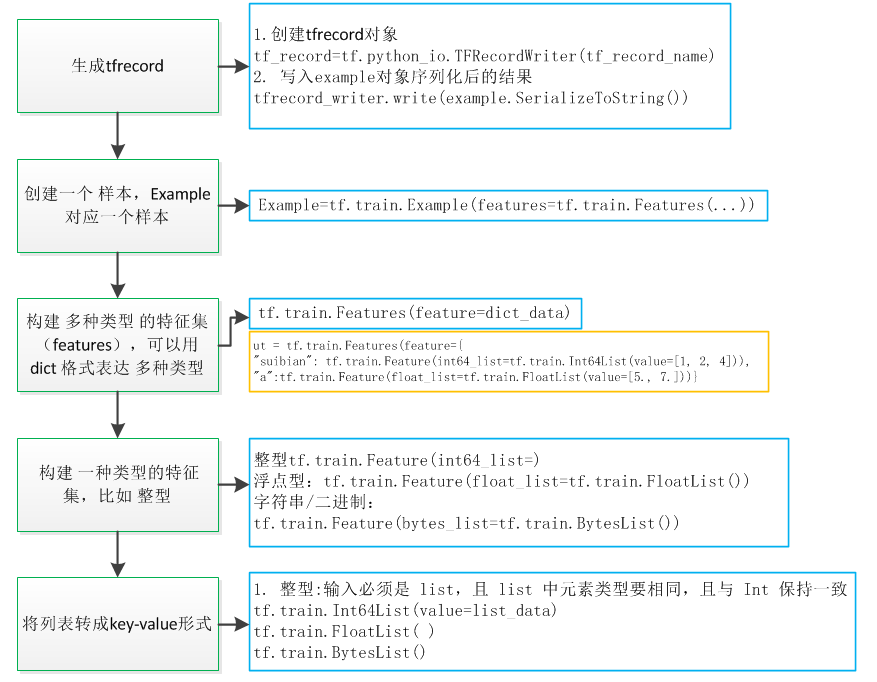

代码
#1.创建tfrecord对象 tf_record=tf.python_io.TFRecordWriter(tf_record_name) tf.train.Int64List(value=list_data) tf.train.FloatList( ) tf.train.BytesList() tf.train.Feature(int64_list=) tf.train.Feature(float_list=tf.train.FloatList()) tf.train.Feature(bytes_list=tf.train.BytesList()) tf.train.Features(feature=dict_data) ut = tf.train.Features(feature={
"suibian": tf.train.Feature(int64_list=tf.train.Int64List(value=[1, 2, 4])),"a":tf.train.Feature(float_list=tf.train.FloatList(value=[5., 7.]))}) example=tf.train.Example(features=tf.train.Features(...)) #2. 写入example对象序列化后的结果 tfrecord_writer.write(example.SerializeToString()) 2. 读取tfrecord文件
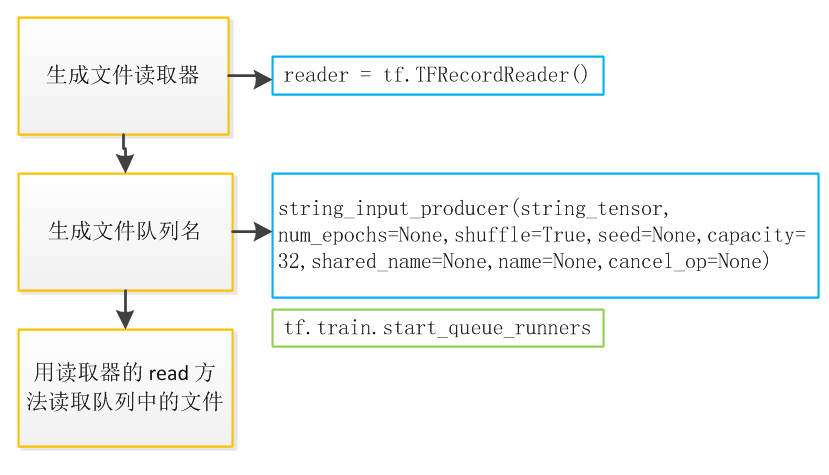
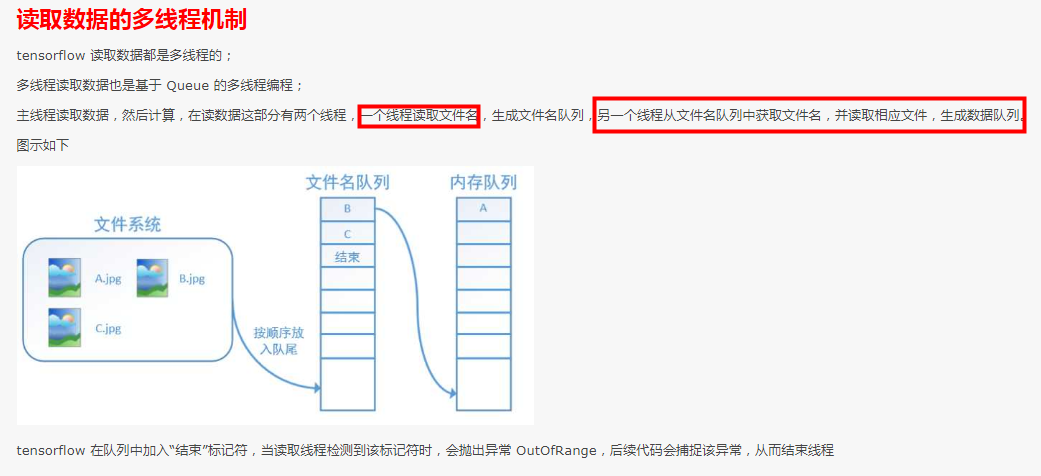
从文件读取有 3 大步骤
- 生成读取器,不同类型的文件有对应的读取器
- 把文件名列表生成队列
- 用读取器的 read 方法读取队列中的文件
3 代码
3.1 dataset_to_tfrecord.py
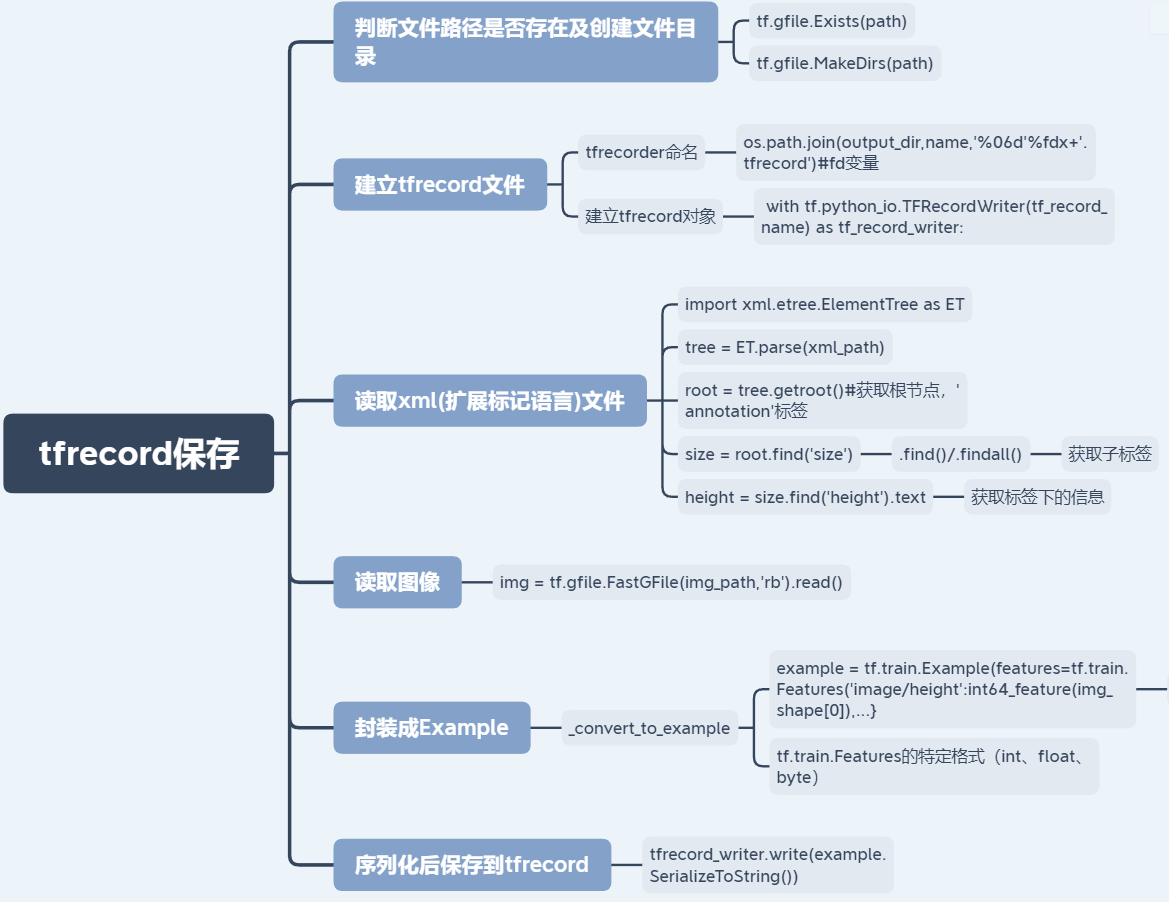
import os import xml.etree.ElementTree as ET import tensorflow as tf from dataset_config import DIRECTORY_ANNOTATIONS,DIRECTORY_IMAGES,NUM_IMAGES_TFRECORD,labels_to_class from utils.data_process_util import int64_feature,float_feature,bytes_feature def _convert_to_example(img,img_shape,labels,trunacted,difficult,bndbox_size): '''将一张图片使用example,转换成protobuffer 格式 :param img: :param img_shape: :param labels: :param trunacted: :param difficult: :param bndbox_size: :return: ''' # 为了转换需求,bbox由单个obj的四个位置值, # 转变成四个位置的单独列表 # 即:[[12,120,330,333],[50,60,100,200]]————>[[12,50],[120,60],[330,100],[333,200]] ymin=[] xmin=[] ymax=[] xmax=[] for b in bndbox_size: ymin.append(b[0]) xmin.append(b[1]) ymax.append(b[2]) xmax.append(b[3]) img_format = b'JPEG' print(type(labels)) for i,label in enumerate(labels): labels[i]=labels_to_class[label] print('trunacted:',trunacted,type(trunacted),len(trunacted)) example = tf.train.Example(features=tf.train.Features(feature={
'image/height':int64_feature(img_shape[0]), 'image/width':int64_feature(img_shape[1]), 'image/channels':int64_feature(img_shape[2]), 'image/shape':int64_feature(img_shape), 'image/object/bbox/xmin':float_feature(xmin), 'image/object/bbox/ymin':float_feature(ymin), 'image/object/bbox/xmax':float_feature(xmax), 'image/object/bbox/ymax':float_feature(ymax), 'image/object/bbox/label_text':int64_feature(labels), # 'image/object/bbox/trunacted':bytes_feature(trunacted), # 'image/object/bbox/difficult':bytes_feature(difficult), 'image/object/bbox/format':bytes_feature(img_format), 'image/object/bbox/data':bytes_feature(img)# 读取的图像值 })) print(img_format) return example def _process_image(dataset_dir,img_name): ''' 读取图像和xml文件 :param dataset_dir: :param img_name: :return: ''' #1.读取图像 #图像路径 img_path = os.path.join(dataset_dir,DIRECTORY_IMAGES,img_name+'.jpg') img = tf.gfile.FastGFile(img_path,'rb').read()#tensorflow读取图像 #2.读取xml #xml路径 xml_path =os.path.join(dataset_dir,DIRECTORY_ANNOTATIONS,img_name+'.xml') tree = ET.parse(xml_path) root = tree.getroot()#获取根节点,'annotation'标签 # 2.1获取图像尺寸信息 size = root.find('size') img_shape=[ int(size.find('height').text), int(size.find('width').text), int(size.find('depth').text) ] #2.2 获取bounding box 相关信息 # bounding box可能有多个,用多个列表存储相关信息。 labels = [] trunacted=[] difficult = [] bndbox_sizes=[] bboxes = root.findall('object') for obj in bboxes: label = obj.find('name').text if obj.find('trunacted'): trunacted.append(obj.find('trunacted').text) else: trunacted.append('0') if obj.find(''): difficult.append(obj.find('difficult').text) else: difficult.append(0) bndbox = obj.find('bndbox') bndbox_size=( float(bndbox.find('ymin').text)/img_shape[0], float(bndbox.find('xmin').text)/img_shape[1], float(bndbox.find('ymax').text)/img_shape[0], float(bndbox.find('xmax').text)/img_shape[1] ) labels.append(label) trunacted.append(trunacted) difficult.append(difficult) bndbox_sizes.append(bndbox_size) return img,img_shape,labels,trunacted,difficult,bndbox_sizes def _add_to_tfrecord(dataset_dir,img_name,tfrecord_writer): ''' 读取图片和xml文件,保存成一个Example :param dataset_dir:根目录 :param img_name:图像名称 :param tfrecord_writer: :return: ''' #1.读取图片内容及相应的xml文件 img, img_shape, labels, trunacted, difficult, bndbox_size=_process_image(dataset_dir,img_name) # return img,img_shape,labels,trunacted,difficult,bndbox_size #2.读取的内容封装成Example, example = _convert_to_example(img, img_shape, labels, trunacted, difficult, bndbox_size) #3.Example序列化结果写入指定tfrecord文件 tfrecord_writer.write(example.SerializeToString()) def _get_output_tfrecord_name(output_dir,name,fdx): """ :param output_dir: :param name: :param fdx:第几个tfrecord文件 :return: """ return os.path.join(output_dir,name,'%06d'%fdx+'.tfrecord') def read_tfrecord(): slim = tf.contrib.slim dataset = slim.dataset #第一个参数,文件路径 file_pattern = os.path.join('tf_records\data','*.record') #第二个参数 reader = tf.TFRecordReader # file_pattern = '%s-* ' # 前面保存的tfrecord文件的文件名类似于“train-00001-of-00004.tfrecord” # file_pattern = os.path.join(dataset_dir, file_pattern % split_name) # dataset_dir即前面保存的tfrecord文件的路径 # 使用slim中的函数tf.FixedLenFeature将tfrecord的example反序列化成存储之前的格式, # 字符串格式的用''表示,整型格式的用0表示,其他确定的信息还原为原来的形式,如'jpeg','png' keys_to_features = {
'image/object/bbox/data': tf.FixedLenFeature((), tf.string, default_value=''), 'image/object/bbox/format': tf.FixedLenFeature((), tf.string, default_value='jpeg'), 'image/height': tf.FixedLenFeature((), tf.int64, default_value=0), 'image/width': tf.FixedLenFeature((), tf.int64, default_value=0), 'image/object/bbox/label_text': tf.FixedLenFeature((), tf.int64, default_value=0)} # 将反序列化的数据重组为更适合网络读入的格式 items_to_handlers = {
'image': slim.tfexample_decoder.Image( image_key='image/object/bbox/data', format_key='image/object/bbox/format', channels=3), # 'image_name': tfexample_decoder.Tensor('image/filename'), 'height': slim.tfexample_decoder.Tensor('image/height'), 'width': slim.tfexample_decoder.Tensor('image/width'), # 'labels_class': tfexample_decoder.Image( # image_key='image/segmentation/class/encoded', # format_key='image/segmentation/class/format', # channels=1) } # 解码器进行解码,定义一个解码器对象,保存到dataset中 # 第三个参数decoder decoder = slim.tfexample_decoder.TFExampleDecoder(keys_to_features, items_to_handlers) # 返回由tfrecord信息所得到的数据集dataset,dataset对象定义了数据集的文件位置,解码方式等元信息 dataset = dataset.Dataset( data_sources=file_pattern, # tfrecord路径 reader=tf.TFRecordReader, # 读取tfrecord文件的方式 decoder=decoder, # 解码tfrecord文件的方式 num_samples=1464, # PASCAL-VOC2012数据集训练样本数 items_to_descriptions={
# 样本集图像和标签描述 'image': 'A color image of varying height and width.', 'labels_class': ('A semantic segmentation label whose size matches image.' 'Its values range from 0 (background) to num_classes.')}, num_classes = 3, # 数据集包含类别数(20个前景类别和1个背景类别) multi_label = True) # 多标签(具体我也不太清楚) dataset_data_provider = slim.dataset_data_provider prefetch_queue = slim.prefetch_queue # 创建一个DatasetDataProvider类的对象data_provider,根据dataset和其他的一些已知信息读取数据。 data_provider = dataset_data_provider.DatasetDataProvider( dataset, num_readers=1, num_epochs=None, shuffle=True) # 通过调用data_provider对象的get实例函数能够根据data_provider中给出的信息解读tfrecord文件,生成图像和标签和图像文件名 image, height, width = data_provider.get(['image', 'height', 'width']) # image_name, = data_provider.get(['image_name']) # label = data_provider.get(['label']) # 图像预处理过程,这里具体的处理过程与本文主题无关,因此省略具体的处理过程 return image, height, width def run(dataset_dir,output_dir,name='data'): """ 运行转换代码逻辑。 存入多个tfrecord文件,每个文件固定N个样本 :param dataset_dir:数据集目录,包含annotations,jpeg文件夹 :param output_dir:tfrecords存储目录 :param name:数据集名字,指定名字以及train or test :return: """ # 1. 判断数据集目录是否存在,创建一个目录 if tf.gfile.Exists(dataset_dir): tf.gfile.MakeDirs(dataset_dir) # 输出路径需要已存在 # if tf.gfile.Exists(output_dir): # tf.gfile.MakeDirs(output_dir) # 2. 读取某个文件夹下的所有文件名字列表 dir_path = os.path.join(dataset_dir,DIRECTORY_ANNOTATIONS) files_path = sorted(os.listdir(dir_path)) print(files_path) # 3. 循环名字列表, # 每200(NUM_IMAGES_TFRECORD)个图片及xml文件存储到一个tfrecord文件中 num = len(files_path) i = 0 fdx = 0 while i < num: tf_record_name = _get_output_tfrecord_name(output_dir,name,fdx) with tf.python_io.TFRecordWriter(tf_record_name) as tf_record_writer: j = 0 while i<num and j < NUM_IMAGES_TFRECORD: xml_path = files_path[i] img_name = xml_path.split('.')[0] #每个图像构建一个Example,保存到tf_record_name中 _add_to_tfrecord(dataset_dir,img_name,tf_record_writer) j += 1 i += 1 fdx += 1 print('fdx',fdx) print('数据集%s转换成功'%(dataset_dir)) 3.2 tfrecord文件读取
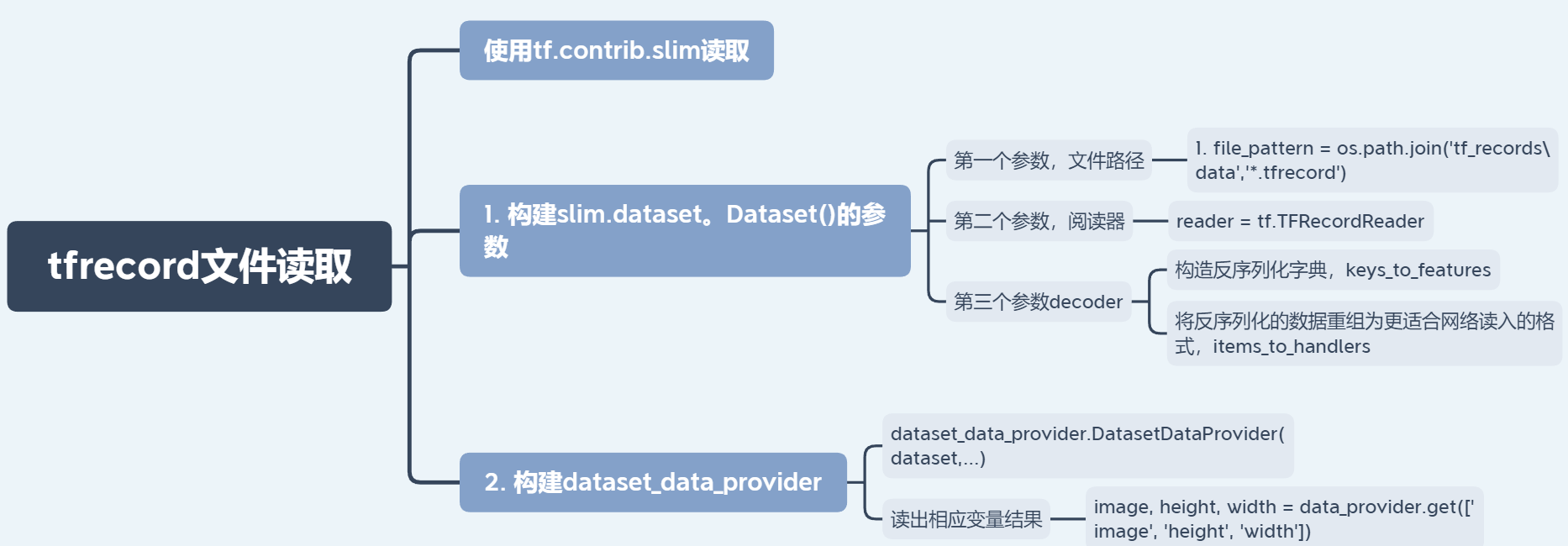
def read_tfrecord(): slim = tf.contrib.slim dataset = slim.dataset #第一个参数,文件路径 file_pattern = os.path.join('tf_records\data','*.tfrecord') #第二个参数 reader = tf.TFRecordReader # file_pattern = '%s-* ' # 前面保存的tfrecord文件的文件名类似于“train-00001-of-00004.tfrecord” # file_pattern = os.path.join(dataset_dir, file_pattern % split_name) # dataset_dir即前面保存的tfrecord文件的路径 # 使用slim中的函数tf.FixedLenFeature将tfrecord的example反序列化成存储之前的格式, # 字符串格式的用''表示,整型格式的用0表示,其他确定的信息还原为原来的形式,如'jpeg','png' keys_to_features = {
'image/object/bbox/data': tf.FixedLenFeature((), tf.string, default_value=''), 'image/object/bbox/format': tf.FixedLenFeature((), tf.string, default_value='jpeg'), 'image/height': tf.FixedLenFeature((), tf.int64, default_value=0), 'image/width': tf.FixedLenFeature((), tf.int64, default_value=0), 'image/object/bbox/label_text': tf.FixedLenFeature((), tf.int64, default_value=0)} # 将反序列化的数据重组为更适合网络读入的格式 items_to_handlers = {
'image': slim.tfexample_decoder.Image( image_key='image/object/bbox/data', format_key='image/object/bbox/format', channels=3), # 'image_name': tfexample_decoder.Tensor('image/filename'), 'height': slim.tfexample_decoder.Tensor('image/height'), 'width': slim.tfexample_decoder.Tensor('image/width'), # 'labels_class': tfexample_decoder.Image( # image_key='image/segmentation/class/encoded', # format_key='image/segmentation/class/format', # channels=1) } # 解码器进行解码,定义一个解码器对象,保存到dataset中 # 第三个参数decoder decoder = slim.tfexample_decoder.TFExampleDecoder(keys_to_features, items_to_handlers) # 返回由tfrecord信息所得到的数据集dataset,dataset对象定义了数据集的文件位置,解码方式等元信息 dataset = dataset.Dataset( data_sources=file_pattern, # tfrecord路径 reader=tf.TFRecordReader, # 读取tfrecord文件的方式 decoder=decoder, # 解码tfrecord文件的方式 num_samples=1464, # PASCAL-VOC2012数据集训练样本数 items_to_descriptions={
# 样本集图像和标签描述 'image': 'A color image of varying height and width.', 'labels_class': ('A semantic segmentation label whose size matches image.' 'Its values range from 0 (background) to num_classes.')}, num_classes = 3, # 数据集包含类别数(20个前景类别和1个背景类别) multi_label = True) # 多标签(具体我也不太清楚) dataset_data_provider = slim.dataset_data_provider prefetch_queue = slim.prefetch_queue # 创建一个DatasetDataProvider类的对象data_provider,根据dataset和其他的一些已知信息读取数据。 data_provider = dataset_data_provider.DatasetDataProvider( dataset, num_readers=1, num_epochs=None, shuffle=True) # 通过调用data_provider对象的get实例函数能够根据data_provider中给出的信息解读tfrecord文件,生成图像和标签和图像文件名 image, height, width = data_provider.get(['image', 'height', 'width']) # image_name, = data_provider.get(['image_name']) # label = data_provider.get(['label']) # 图像预处理过程,这里具体的处理过程与本文主题无关,因此省略具体的处理过程 return image, height, width 版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/219897.html原文链接:https://javaforall.net


