
目录
partition
是物理上的概念,每个
partition
对应于一个
log
文件,该 log
文件中存储的就是
producer
生产的数据
1.什么是Topic
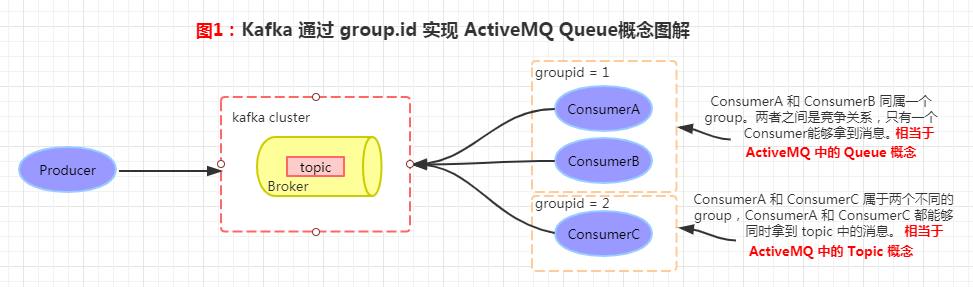
Kafka 和 ActiveMQ 一样,都是非常优秀的消息订阅/发送的中间件。在 ActiveMQ 中,我们知道它有 Queue 和 Topic 的概念,但是在 Kafka 中,只有 Topic 这一个概念(Kafka 消费端通过 group.id 属性可以实现 ActiveMQ 中 Queue 的功能,参见图1)
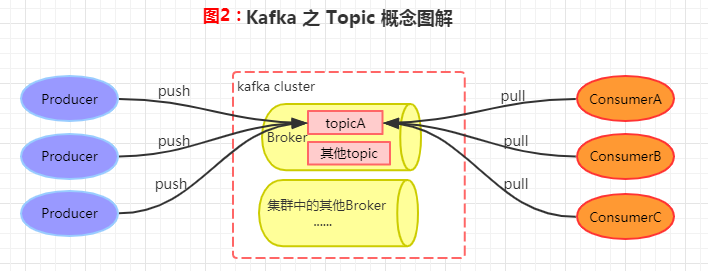
在 Kafka 中,Topic 是一个存储消息的逻辑概念,可以理解为是一个消息的集合。每条发送到 Kafka 集群的消息都会自带一个类别,表明要将消息发送到哪个 Topic 上。在存储方面,不同的 Topic 的消息是分开存储的,每个 Topic 可以有多个生产者向他发送消息,也可以有多个消费者去消费同一个Topic中的消息(参见图2)

补充:
此处Queue涉及到一个消费者组(Consumer Group)的概念。(上图groupid=1处的说明,有点小问题,这个消费者组 groupid 参考本文 3.Consumer Group 消费者组)
2.什么是Partition
Partition,在 Kafka 中是分区的意思。分区,提高了Kafka的并发,也解决了Topic中数据的负载均衡。即:Kafka 中每个 Topic 可以划分多个分区(每个 Topic 至少有一个分区),同一个 Topic 下的不同分区包含的消息是不同的(分区可以间接理解成数据库的分表操作)。
每个消息在被添加到分区的时候,都会被分配一个 offset (偏移量),它是消息在当前分区中的唯一编号。Kafka 通过 offset 可以保证消息在分区中的顺序性,但是跨分区是无序的,即 Kafka 只保证在同一个分区内的消息是有序的。
如下图,我们通过命令(命令如下↓↓↓)创建一个名为 test 的 Topic,并对其进行分区,设置 3 个分区,分别是 test-0、test-1、test-2。每一条消息发送到 broker 的时候,会根据 Partition 的分区规则计算,然后选择将该消息存储到哪一个 Partition。如果 Partition 规则设置合理,那么所有的消息都会均匀的分布在不同的 Partition 中,这样就类似于数据库的分库分表的概念,将数据做了分片处理操作。

问题1:此时你可能会有疑惑,为什么第一个producer会将消息写入 test-0,以此类推,此处涉及到5.producer消息分发策略。请继续往后看。
创建 Topic 命令如下:
bin/kafka-topics.sh –create –zookeeper 192.168.204.201:2181,192.168.204.202:2181,192.168.204.203:2181 ––replication-factor 1 –partitions 3 –topic test
备注:bin/kafka-topics.sh –create —->kafka自带命令 –create表示创建 topic
—zookeeper xxx.xxx.xxx.xxx:2181 —->zookeeper 集群地址
––replication-factor 1 —->备份数(1个备份)
–partitions 3 —->kafka分区数(表示分了3个分区)
–topic test —->要创建的 topic 的名称
3.Consumer Group 消费者组
组成。
消费者组内每个消费者负
责消费不同分区的数据,一个分区只能由一个组内的某一个消费者消费;消费者组之间互不影响。
所有的消费者都属于某个消费者组,即
消费者组是逻辑上的一个订阅者
。
【各自】
消费该topic中某个分区的数据,比如customer0消费partition0,customer1消费partition1。
消费者组的好处,可以提高消费能力!!!
4.Topic 和 Partition 的存储
本实例,是以192.168.204.201、192.168.204.202、192.168.204.203三台服务器搭建成的Kafka集群,来做介绍的
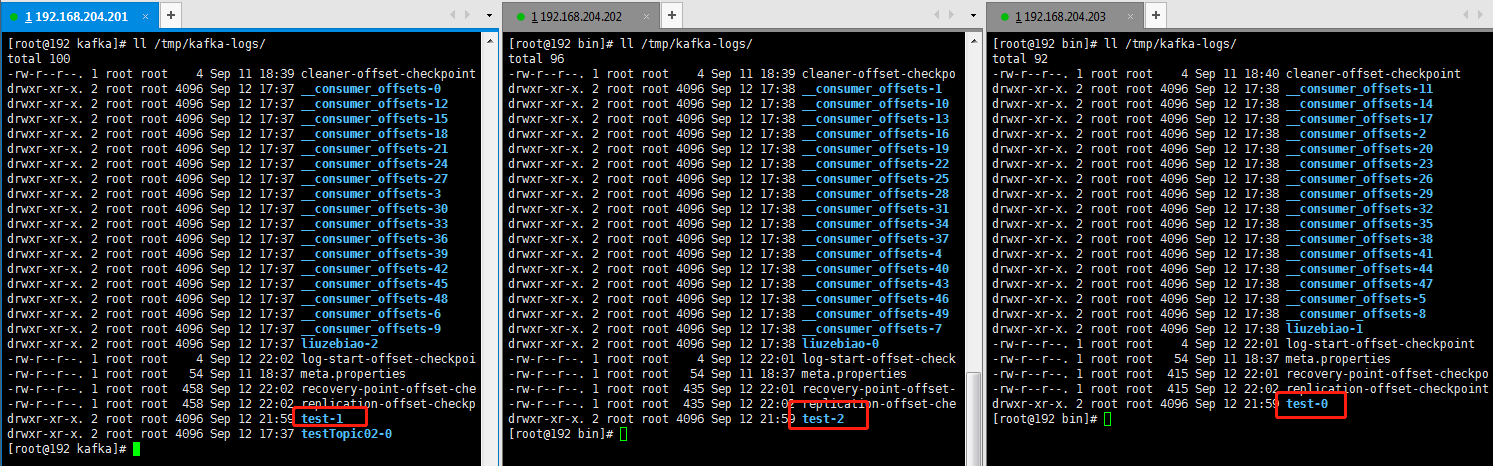
如下图,表示名称为 test 的 topic已经创建完成。那么 Partition 是如何存储的呢??

Partition 是以文件的形式存储在文件系统中,如上创建了一个名为 test 的topic,我们定义其有 3 个 partition,既然 partition 是以文件的形式存储,那么这 3 个 partition 在哪里存储着呢?
我们可以在 kafka 的数据目录(/tmp/kafka-log)下找到,此目录可自行配置。在 /tmp/kafka-log 目录下,我们会看到有 3 个目录:test-0、test-1、test-2。命名规则是 topic_name–partition_id。所在目录如下图所示:
问题2:此时你可能会有疑惑,为什么 3个分区会随机分配到3台服务器,此时会涉及到多个分区在集群中的分配策略。那么多个分区如何在集群中做到合理的分配?
答:(1)将所有 N 个Broker 和 i 个 Partition 排序(本例中 N = 3,i = 3)
(2)将第 i 个 Partition 分配到 ( i % n)个 Broker 上。(这样 test-1 就分配到第一台了,以此类推)
5.producer消息分发策略
消息是 Kafka 中最基本的数据单元。在 Kafka 中,一条消息由 key 和 value 两部分组成,key 和 value 值都可以为空。
这里的 key 有什么用呢?当我们在发送一条消息时,我们可以指定这个 key ,那么 producer 则会根据 key 和 partition 机制,来判断当前这条消息应该发送并存储到哪个 partition 中。(此时问题1便得到了解决)
如果 Kafka 中的 key 为 null 该怎么办?默认情况下,Kafka 采用的是 hash 取模的分区算法。如果 key 为 null 的话,则会随机的分配一个分区。这个随机是在这个参数 “metadata.max.age.ms”的时间范围内随机选择一个。对于这个时间段内,如果 key 为 null,则只会发送到唯一的分区,这个值默认情况下是 10 分钟更新一次。
此外,Kafka 也为我们提供了自定义消息分发策略的入口,我们可以根据自身业务的情况,来自定义消息分发策略。那么如何来实现我们自己的分区策略呢?我们只需要定义一个类,实现 Partitioner 接口,重写它的 partition 方法即可。然后在配置 kafka 的时候,设置使用我们自定义的消息分发策略即可。如何自定义消息分发策略,请参照 4.1 自定义消息分发策略Demo
5.1 自定义消息分发策略Demo
/ * 1.自定义分区策略 */ public class MyPartition implements Partitioner { Random random = new Random(); public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { //获取分区列表 List
partitionInfos = cluster.partitionsForTopic(topic); int partitionNum = 0; if(key == null){ partitionNum = random.nextInt(partitionInfos.size());//随机分区 } else { partitionNum = Math.abs((key.hashCode())/partitionInfos.size()); } System.out.println("当前Key:" + key + "-----> 当前Value:" + value + "----->" + "当前存储分区:" + partitionNum); return partitionNum; } public void close() { } public void configure(Map
map) { } }
/ * SpringBoot 下,添加如下partitioner.class 属性,指定使用自定义MyPartition类即可 */ spring: kafka: properties: partitioner.class: com.report.kafka.partition.MyPartition / * Spring使用 xml 或 注解形式,配置如下属性即可 */ props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.report.kafka.partition.MyPartition");6.消费者如何消费指定分区消息
此时,名称为 test 的 topic 有 3 个分区,分别为0、1、2,如果我们想消费分区0中的消息,该如何消费呢?使用Java操作kafka 有 spring-kafka.jar 和 kafka-clients.jar 两种方式。如下对这两种方式分别作了介绍,便可以完成对指定分区消息的消费。
/ * 1.使用 spring-kafka.jar包中的 KafkaTemplate 类型 * 使用 @KafkaListener 注解方式 * 如下:说明消费的是名称为test的topic下,分区 1 中的消息 */ @KafkaListener(topicPartitions = {@TopicPartition(topic = "test",partitions = {"1"})}) / * 2.使用kafka-clients.jar包中的 KafkaConsumer 类型 * 如下:说明消费的是名称为test的topic下,分区 1 中的消息 */ TopicPartition topicPartition = new TopicPartition("test" , 1); KafkaConsumer consumer = new KafkaConsumer(props); consumer.assign(Arrays.asList(topicPartition));到此处,Topic 和 Partition 的基本使用就介绍完了
如果本文对你有所帮助,那就给我点个赞呗 ^_^
End
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/220129.html原文链接:https://javaforall.net


