
本文作者来自Byzer社区 & Kyligence 机器学习平台工程师 Andie Huang
背景 Background
对于算法业务团队来说,将训练好的模型部署成服务的业务场景是非常常见的。通常会应用于三个场景:
- 部署到流式程序里,比如风控需要通过流式处理来实时监控。
- 部署到批任务中
- 部署成API服务
然而在现实世界中,很多算法工程师都会遇到需要花费很多精力在模型部署工程上的问题,
- 平台割裂。训练和部署是在不同平台完成的。
- 配合问题。部署一个模型,需要研发工程师,运维配合,才能完成这件事。
- 技术问题,一般地,大数据里的批流亦或是Web服务一般用Java/Scala/C++偏多些,而AI算法模型一般都是通过Python来生成的,存在语言障碍。
传统上,想要把算法部署成服务,会用到如下方法:
- 比如基于 Tornado 框架把一个 python 模型部署成 RestfulAPI 的服务。或者如果是 Tensorflow 训练的模型可以用 Tensorflow Serving 的方式结合 Docker 去部署成 RPC/ Restful API 服务。这些能够帮助用户实现模型部署的意图,只是不同的方式都会存在优缺点以及问题;
- 比如用 Python/C++ 开发的模型,要做成 RestfulAPI 或者想做成流批处理可能得跨语言平台,一般想到用 Spark,这个时候就需要动用 JNI,而跨语言进程之间又面临数据传输的效率问题等;
传统的这些方法,无法统一完成批,流,web服务的部署,无法解决平台割裂,无法解决协作问题。
与传统方式不同,MLSQL 通过融合Ray框架,通过UDF 打通了大数据和Python的生态隔离,完成了训练和模型部署的统一,同时也完美解决了Python模型部署的三个问题。
Ray 是 UC Berkeley RISELab 新推出的高性能的面对 AI 的分布式执行框架[1,2],它使用了和传统分布式计算系统不一样的架构和对分布式计算的抽象方式,具有比 Spark 更优异的计算性能。
下面详细介绍几种比较流行的传统模型部署方式的流程,用户所面临的痛点,以及 MLSQL 的部署方案与之对比的优点
传统模型部署方法
基于 Tornado 的模型部署
传统的 Tornado 方式的模型部署,链路较长,首先用户需要在训练节点里,训练好模型,并且写好预测代码,然后将模型以及预测代码持久化成 pickle 文件。由于训练节点和预测节点是分离的,所以需要中间的存储系统作为媒介,以便服务端 server 拉取模型和预测代码。服务端拉取模型后需要将模型反序列化,用 tornado 拉起模型服务。
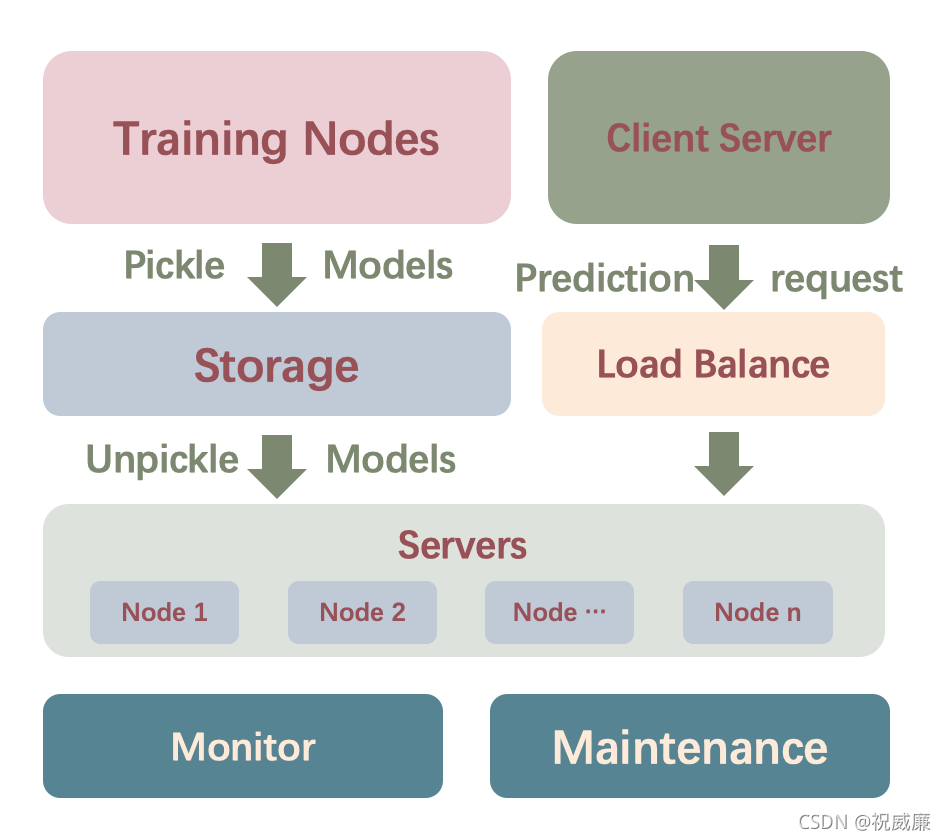

请添加图片描述
基于 Tensorflow Serving 的模型部署
为了服务开发者将训练好的 Tensorflow 模型部署线上生产环境,Google 提供了 TensorFlow Serving,可以将训练好的模型直接上线并提供服务。大概工作流程如下:模型文件存储在存储系统中,source 模块会创建一个 Loader,加载模型信息。Source 会通知 DynamicManager 模块有新的模型需要加载,Manger 模块会根据 VersionPolicy 的算法制定模型更新策略,来确定 Loader 加载是否加载最新的模型。当客户端请求模型时候,可以指定模型版本,也可以用最新的模型。
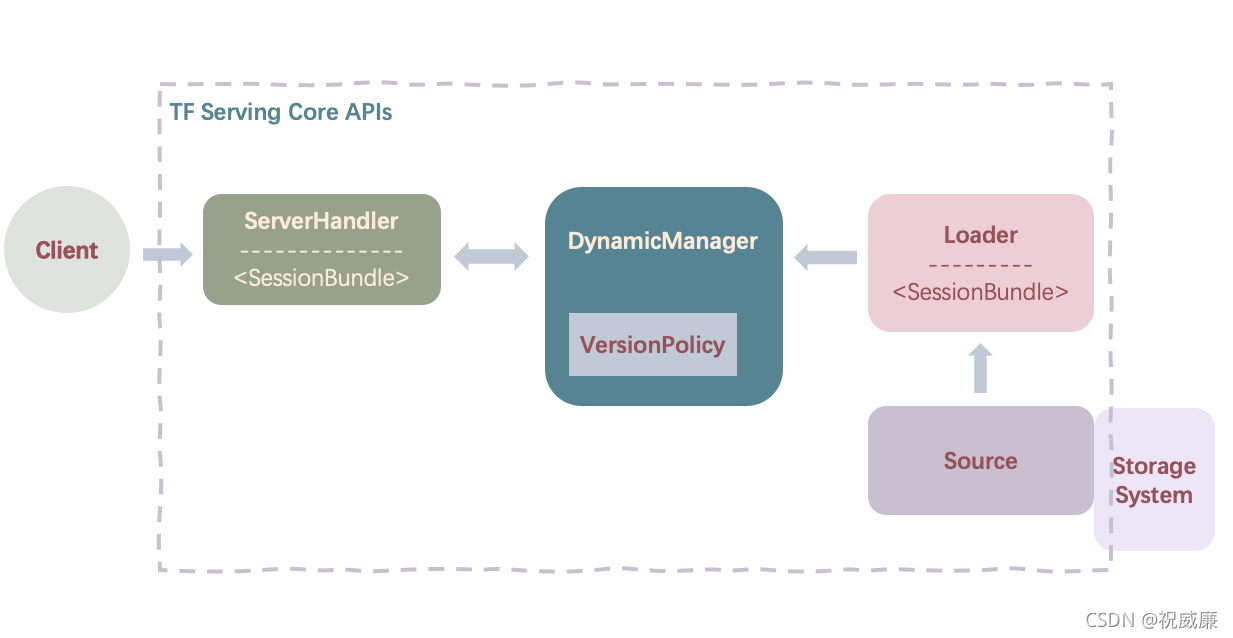
请添加图片描述
【总结】Tensorflow 的 Serving 模块对比 Tornado 部署模型服务而言,轻便了许多,同时其模型版本管理模块很大程度解决了模型版本管理和自更新的问题,相比上一种方式,部署工程师节省了开发模型自更新算法和模型管理模块的时间。但是 Google Tensorflow Serving 的许多用户仍然存在使用上的痛点。比如,最直观的,数据处理和特征工程部分仍然无法直接部署服务端,需要在客户端进行处理。此外,若想引入流批处理生数据,还需要接入流批处理(例如 Spark or Flink)等处理框架。
与 Tensorflow Serving 不同的是,MLSQL 选择 Ray 作为计算框架,天然支持分布式计算,无论是对离线的训练,还是在线部署都能很好的支持分布式计算。对于在线特征工程部分,也充分利用了 Ray 的分布式计算,以及对 pands 和 numpy 天然支持的优势,能够高效地进行在线生数据的分布式处理,再喂给模型得到打分结果。
MLSQL 模型部署 UDF 函数
register ScriptUDF.`` as arrayLast where lang="scala" and code='''def apply(a:Seq[String])={ a.last }''' and udfType="udf"; select arrayLast(split("a.b.c",".")) as c as output; 将内置算法训练好的模型注册成 UDF 的代码是这样的:
register RandomForest.`/tmp/model` as model_predict; select vec_array(model_predict(features)) from mock_data as output; 与此同时,我们可以看到,MLSQL 模型部署操作暴露给用户的仍然是类 SQL 的语法,可以非常方便快速地让工程师上手,降低工程师的工作量提升模型部署效率。
但是我们知道大部分算法可能都是使用 Python 来开发的,而且比如深度学习模型,模型文件都可能非常大,也就是我们其实需要一个带状态的 UDF,这是有挑战的,但得益于
- MLSQL 已经支持 Python 脚本的执行,引入 Ray 后,Python 脚本的分布式执行也不是问题了,计算性能和可扩展性上都有了保证。
- MLSQL 利用 Arrow 做数据传输格式,使的数据在跨语言进程传输的性能得到保证
- MLSQL 内置的增强数据湖支持目录以表的形式存储,这样可以很好的把模型通过表的方式保存在数据湖里,支持版本以及更新覆盖。同时也方便了 Spark / Ray 之间的模型传输。
有了前面这些基础,我们就可以使用和内置算法一样的方式将一个 Python 的模型注册成一个 UDF 函数,这样可以将模型应用于批,流,以及 Web 服务中。
具体地,我们将在下个章节展示 MLSQL 基于 Ray 从模型训练再到模型模型部署的全流程 demo,并展示 MLSQL 部署的背后原理。
如何利用 MLSQL 部署模型训练
训练一个 Tensorflow 模型
下面的代码要在 notebook 模式下运行
首先,准备 minist 数据集
include lib.`github.com/allwefantasy/lib-core` where force="true" and libMirror="gitee.com" and -- proxy configuration. alias="libCore"; -- dump minist data to object storage include local.`libCore.dataset.mnist`; !dumpData /tmp/mnist; load parquet.`/tmp/mnist` as mnist_data; 在上面的示例中,通过 MLSQL 的模块支持,引入第三方开发的 lib-core,从而获得 !dumpData 命令获取 minist 数据集。
接着就开始拿测试数据 minist 进行训练,下面是模型训练代码,在训练代码中,我们引入 Ray 来训练:
#%python #%input=mnist_data #%schema=file #%output=mnist_model #%env=source /Users/allwefantasy/opt/anaconda3/bin/activate ray1.3.0 #%cache=true import ray import os from tensorflow.keras import models,layers from tensorflow.keras import utils as np_utils from pyjava.api.mlsql import RayContext from pyjava.storage import streaming_tar from pyjava import rayfix import numpy as np ray_context = RayContext.connect(globals(),"127.0.0.1:10001") data_servers = ray_context.data_servers() def data(): temp_data = [item for item in RayContext.collect_from(data_servers)] train_images = np.array([np.array(item["image"]) for item in temp_data]) train_labels = np_utils.to_categorical(np.array([item["label"] for item in temp_data]) ) train_images = train_images.reshape((len(temp_data),28*28)) return train_images,train_labels @ray.remote @rayfix.last def train(): train_images,train_labels = data() network = models.Sequential() network.add(layers.Dense(512,activation="relu",input_shape=(28*28,))) network.add(layers.Dense(10,activation="softmax")) network.compile(optimizer="rmsprop",loss="categorical_crossentropy",metrics=["accuracy"]) network.fit(train_images,train_labels,epochs=6,batch_size=128) model_path = os.path.join("tmp","minist_model") network.save(model_path) model_binary = [item for item in streaming_tar.build_rows_from_file(model_path)] return model_binary model_binary = ray.get(train.remote()) ray_context.build_result(model_binary) 最后把模型保存增强数据湖里:
save overwrite mnist_model as delta.`ai_model.mnist_model`; 模型部署
训练好模型之后,我们就可以用 MLSQL 的 Register 语法将模型注册成基于 Ray 的服务了,下面是模型注册的代码
把模型注册成 UDF 函数
!python env "PYTHON_ENV=source /Users/allwefantasy/opt/anaconda3/bin/activate ray1.3.0"; !python conf "schema=st(field(content,string))"; !python conf "mode=model"; !python conf "runIn=driver"; !python conf "rayAddress=127.0.0.1:10001"; -- 加载前面训练好的tf模型 load delta.`ai_model.mnist_model` as mnist_model; -- 把模型注册成udf函数 register Ray.`mnist_model` as model_predict where maxConcurrency="8" and debugMode="true" and registerCode=''' import ray import numpy as np from pyjava.api.mlsql import RayContext from pyjava.udf import UDFMaster,UDFWorker,UDFBuilder,UDFBuildInFunc ray_context = RayContext.connect(globals(), context.conf["rayAddress"]) def predict_func(model,v): train_images = np.array([v]) train_images = train_images.reshape((1,28*28)) predictions = model.predict(train_images) return {"value":[[float(np.argmax(item)) for item in predictions]]} UDFBuilder.build(ray_context,UDFBuildInFunc.init_tf,predict_func) ''' and predictCode=''' import ray from pyjava.api.mlsql import RayContext from pyjava.udf import UDFMaster,UDFWorker,UDFBuilder,UDFBuildInFunc ray_context = RayContext.connect(globals(), context.conf["rayAddress"]) UDFBuilder.apply(ray_context) ''' ; -- 这个代码可以将分区数目减少,避免并发太高导致的排队等待 -- load parquet.`/tmp/mnist` as mnist_data; -- save mnist_data as parquet.`/tmp/minst-8` where fileNum="8"; load parquet.`/tmp/minst` as mnist_data; select cast(image as array
) as image from mnist_data limit 100 as new_mnist_data; select model_predict(array(image)) as predicted from new_mnist_data as output;
模型调用
模型注册结束之后,如何调用注册的模型呢?MLSQL 提供最简易的类 SQL 语句做批量(Batch)查询。具体操作如下展示
load parquet.`/tmp/minst` as mnist_data; select cast(image as array
) as image from mnist_data limit 100 as new_mnist_data; select model_predict(array(image)) as predicted from new_mnist_data as output;
PyJava UDF调用关系图
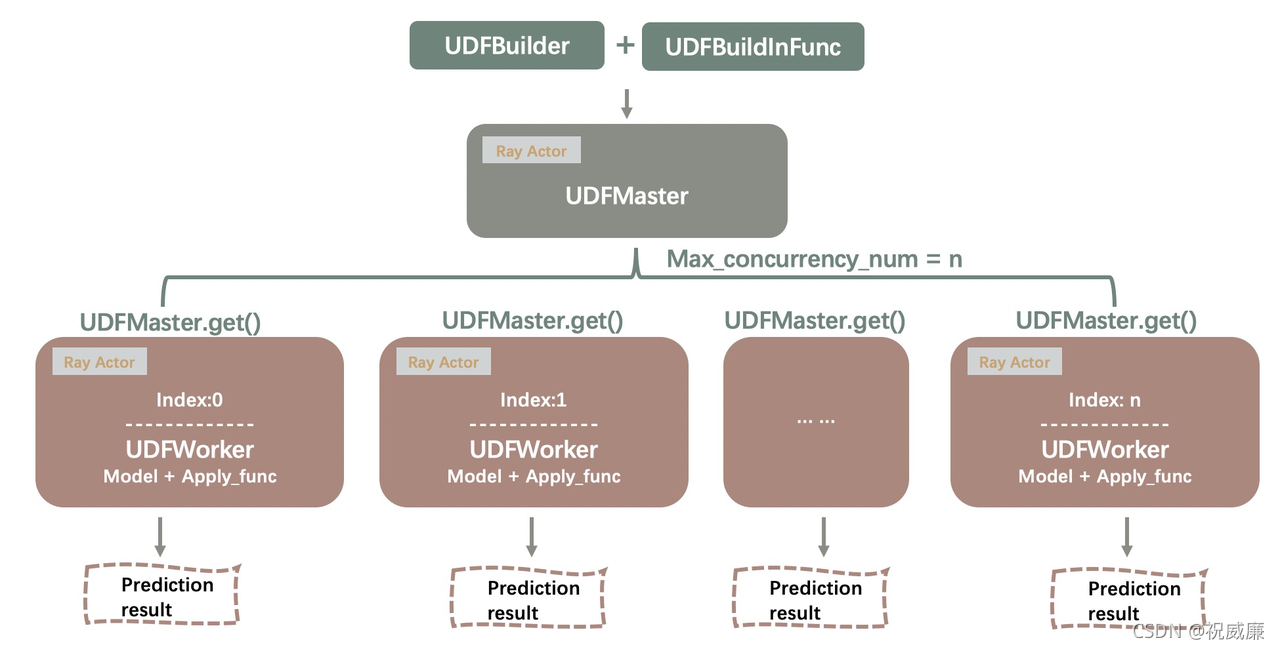
在这里插入图片描述
具体详细的函数参数介绍,请看 【UDFBuilder 与UDFBuildInFunc参数使用详解】部分
MLSQL 执行 Python 的交互
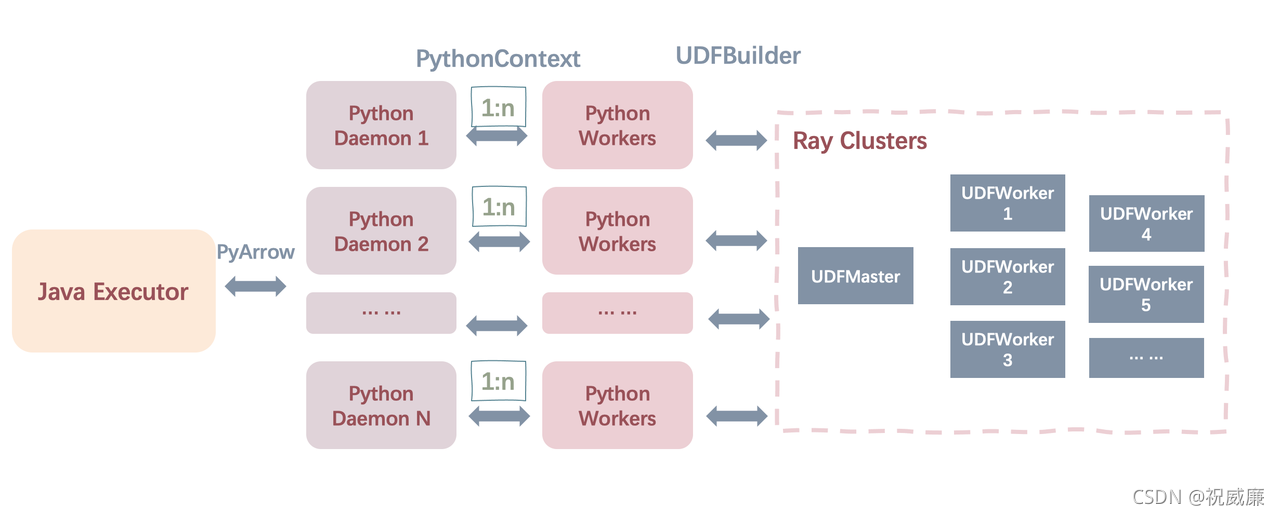
在这里插入图片描述
首先 MLSQL Engine 端会在启动的 java 应用进程里调用 pyjava 模块。pyjava 中 python SDK 部分的入口是 daemon.py 文件,该入口文件的主要功能是创建 python worker,同时担任数据流的管道角色。worker 的核心逻辑包括,导入ray, 设置自己的内存限制,读取配置参数,读取 python 脚本,执行python 脚本(通过 Arrow 传递 python 脚本数据),并执行。最后通过 Arrow 传递 python 执行结果(也就是本文提到的预测结果)给 MLSQL Engine 端,同时 python worker 执行的输入数据(也就是本文场景下的模型预测输入数据)借助 pyarrow 从 MLSQL engine 端获取。
在 Python Daemon 线程中,通过 UDFBuilder 创建构造 Ray Actor 包括 UDFMaster 和 UDFWorker。如上一节所述,UDFMaster 主要充当管理 UDFWorker 节点的功能,真正预测的逻辑在 UDFWoker 的 Ray节点里执行。最后的执行结果通过 Ray 获取 future 的方式返回给 PythonContext,python worker再通过 pyarrow 返回给 MLSQL Engine。
UDFBuilder 与 UDFBuildInFunc 参数使用详解
UDFBuilder
ray_context = RayContext.connect(globals(),"127.0.0.1:10001") init_func: 模型初始化函数。可以是用户自定义的模型初始化函数,如果没有特别定制化的业务场景,可以直接复用 BuilderInFunc 的 init_tf 函数。UDFBuildInFunc 部分介绍了 init_func 的实现基本思路。
apply_func:模型预测函数,也就是用户定义的接收到数据之后做的数据处理函数,以及喂给模型整个流程的函数。
def build(ray_context: RayContext, init_func: Callable[[List[ClientObjectRef], Dict[str, str]], Any], apply_func: Callable[[Any, Any], Any]) -> NoReturn: UDFBuildInFunc
这里的 init_func 是函数的引用,所以仅需要传递一个函数的引用就可以。因为基本大部分的 AI 场景都是 load 模型,然后把模型存储在某个 storage 里,因此,pyjava 的 UDF 模块为用户提供的通用的init_func,也就是 UDFBuildInFunc 里的 init_tf。这里的 init_tf 是 UDFBuildInFunc 的一个静态函数,可以通过静态调用就可以了。
再来看一下这个 init_tf,用户需要传递的两个值是,分别是 model_refs,以及 conf。对于 model_refs,它是一个 ray 存储的 object 类型,也就是说,基于我们上一步在 ray 框架里训练好的模型,可以通过 ray 的 get 方式获取得到【因为上一步的 train,是基于 ray.remote 调用的,结果会产生】。
class UDFBuildInFunc(object): @staticmethod def init_tf(model_refs: List[ClientObjectRef], conf: Dict[str, str]) [1] https://zhuanlan.zhihu.com/p/ Ray 分布式计算框架介绍
[2] Moritz, Philipp, et al. “Ray: A distributed framework for emerging AI applications.” 13th Symposium on Operating Systems Design and Implementation ({OSDI} 18). 2018.
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/220287.html原文链接:https://javaforall.net


