
self attention是提出Transformer的论文《Attention is all you need》中提出的一种新的注意力机制,这篇博文仅聚焦于self attention,不谈transformer的其他机制。Self attention直观上与传统Seq2Seq attention机制的区别在于,它的query和massage两个序列是相等的。大家可能都以为self attention是attention的改进版,但其实self attention的设计思想来自RNN和CNN,希望这篇博文能对你有所启发。
广义注意力机制
在谈论self attention之前我们首先认识一下以KQV模型来解释的Attention机制。
Self Attention
Self Attention机制的优越之处
抖音算法面试题,Self Attention和Seq2Seq Attention相比,优越在哪里。
RNN本身对于长距离的依赖关系有一定的捕捉能力,但由于序列模型是通过门控单元使得信息保持流动,并且选择性地传递信息。但这种方式在文本长度越来越长的条件下,捕捉依赖关系的能力越来越低,因为每一次递归都伴随着信息的损耗,所以有了*Attention机制来增强对我们所关注的那部分依赖关系的捕捉*。除此之外,序列模型也不能对层次结构的信息进行有效的表达。
Attention(包括self attention在内)本身的优点(相较于RNN而言):
- 对长期依赖关系有着更强的捕捉能力
- 可以并行计算
- 元素与元素之间的距离从CNN的logarithmic path length进一步缩短到constant path length
- 由CNN fixed size perceptive变成了variable-sized的 perceptive,具体的长度等于文本长度,这也是self-attention相对于普通attention的优点。
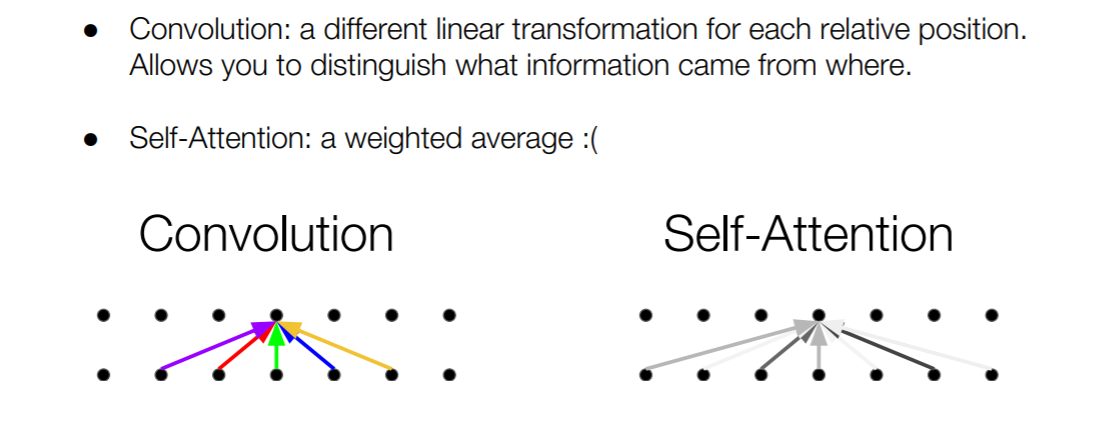

图片中的文字讲的是self-attention和卷积的区别,不能看作是优点。从图中能看出self-attention和卷积的关联之处
如果普通attention机制在一个窗口下计算attention score,正如我这篇博文介绍的attention机制,那么这种attention机制的感受野就只有窗口,而且随着窗口移动还需要计算多次。
所以self-attention相较于Seq2Seq attention还有另一个优点:
- 一步矩阵计算得到了文本序列中任意两个元素的相似度,而且是以整个文本作为观察范围的。
Self-Attention归纳如下:
Self-attention的优点归纳为以下:

Transformer里面一共有三种self-attetnion:
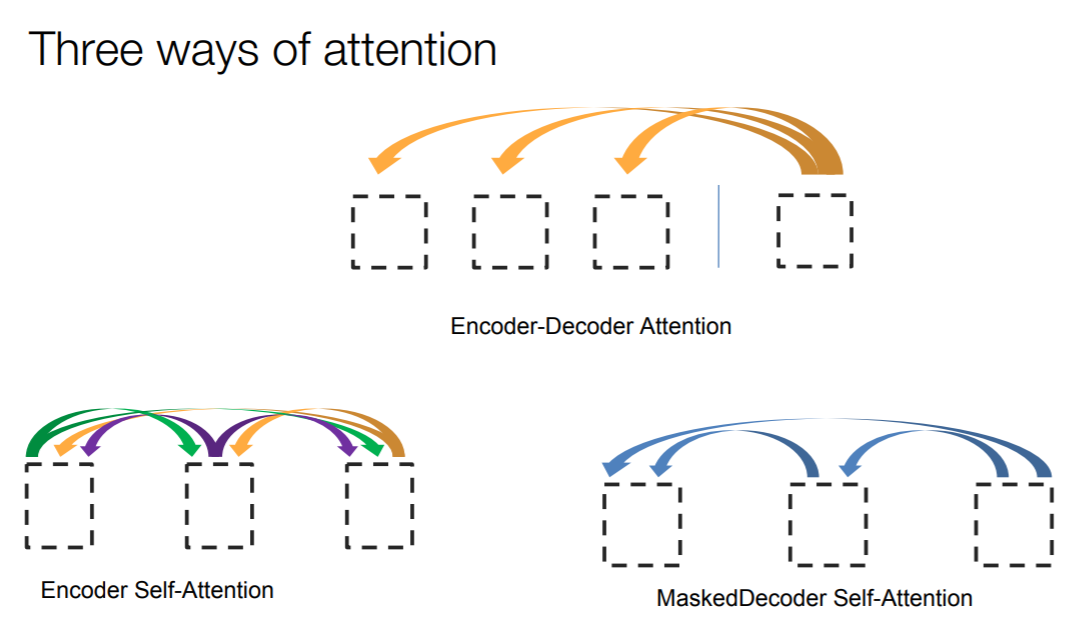
三种Self-attention的区别:

参考文献
- 注意力机制(Attention Mechanism) – NLP算法面试
- Attention and Self-Attention
- Attention机制详解(二)——Self-Attention与Transformer
- 完全图解GPT-2:看完这篇就够了(一)
- Deep Learning: 9 Convolutional Networks
- self-attention详解
- 浅谈Attention机制的理解
- 遍地开花的 Attention ,你真的懂吗
- Tensor2Tensor Transformers New Deep Models for NLP
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/220487.html原文链接:https://javaforall.net


