
一、概述
# 目前最新版本是7.12.1 docker pull docker.elastic.co/logstash/logstash:7.5.1 docker pull docker.elastic.co/elasticsearch/elasticsearch:7.5.1 docker pull docker.elastic.co/kibana/kibana:7.5.1 二、Elasticsearch
elasticsearch官网https://www.elastic.co/cn/
1、正向索引和倒排索引
- 正向索引
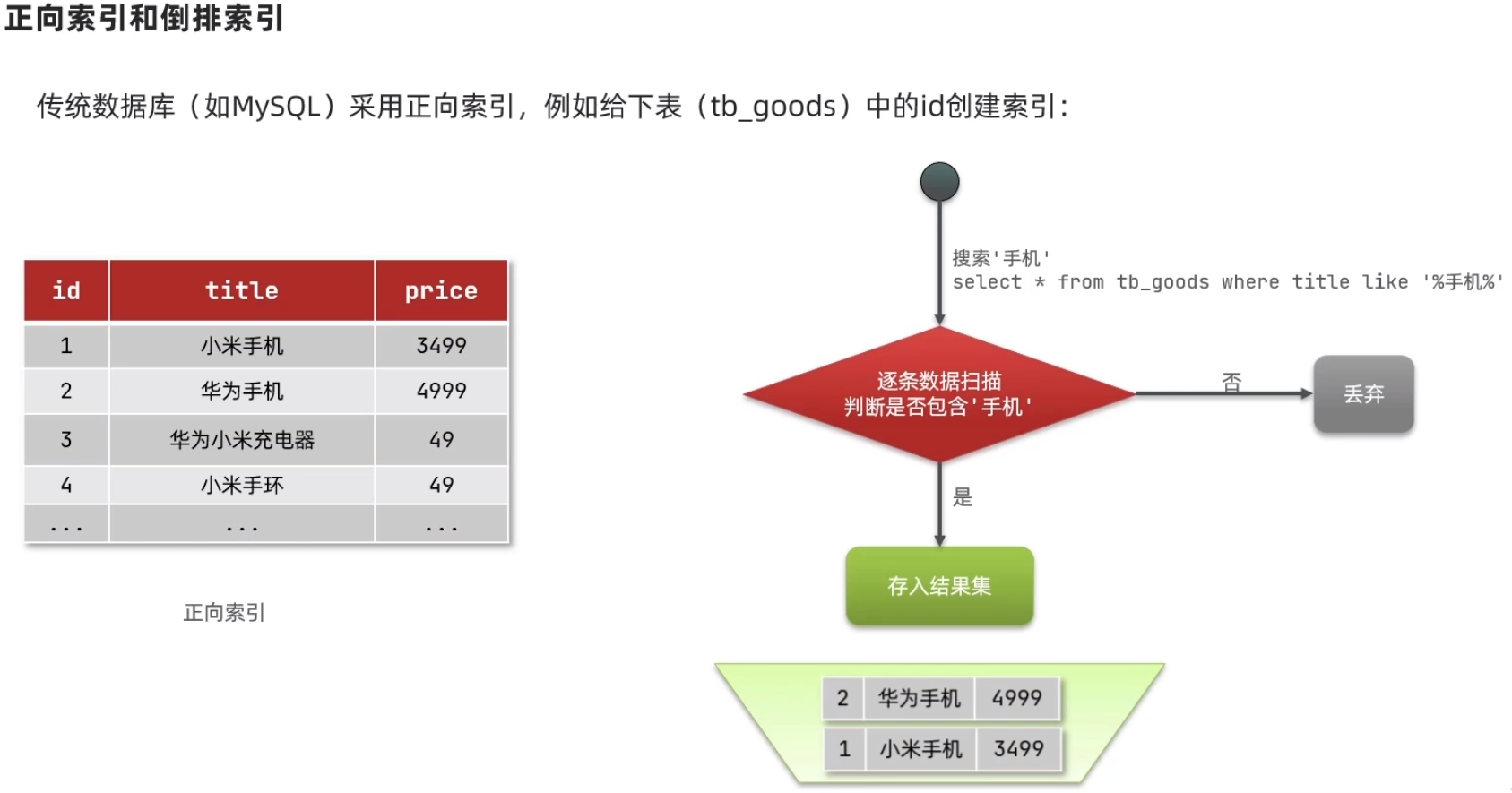

- 倒排索引
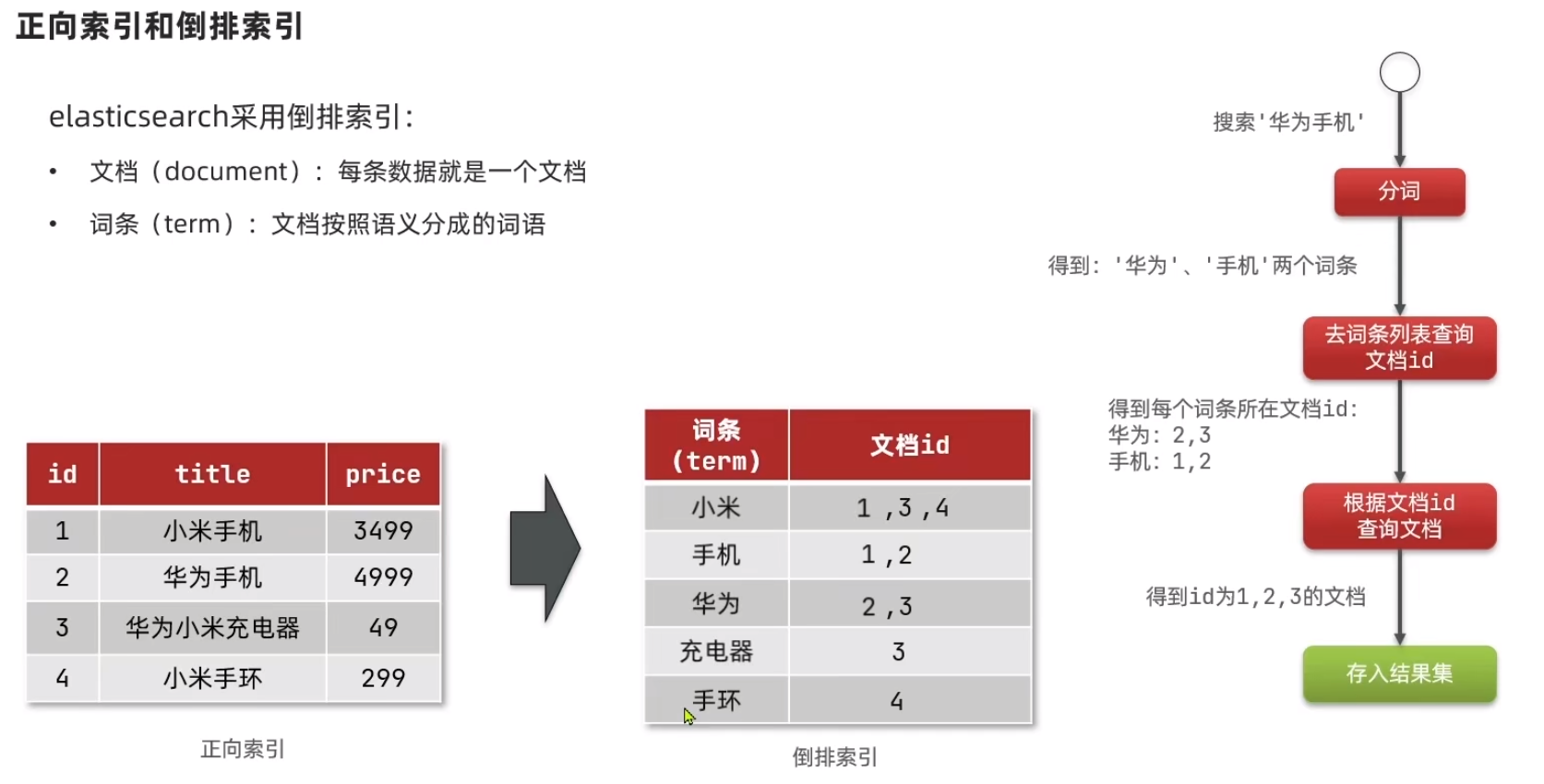
2、基本概念
2.1、文档
2.1.1、新增文档

# 新增文档 POST /edevp/_doc/1 {
"info": "黑马程序员Java讲师", "email":"", "name":{
"firstName":"云", "lastName":"赵" } } 2.1.2、查询、删除文档
查看文档语法
GET /索引库名/_doc/文档id # 示例 GET /edevp/_doc/1 删除文档语法
DELETE /索引库名/_doc/文档id # 示例 DELETE /edevp/_doc/1 2.1.3、修改文档
- 方式一:全量修改,会删除旧文档,添加新文档
如果id在数据库存在则修改,不存在则新增
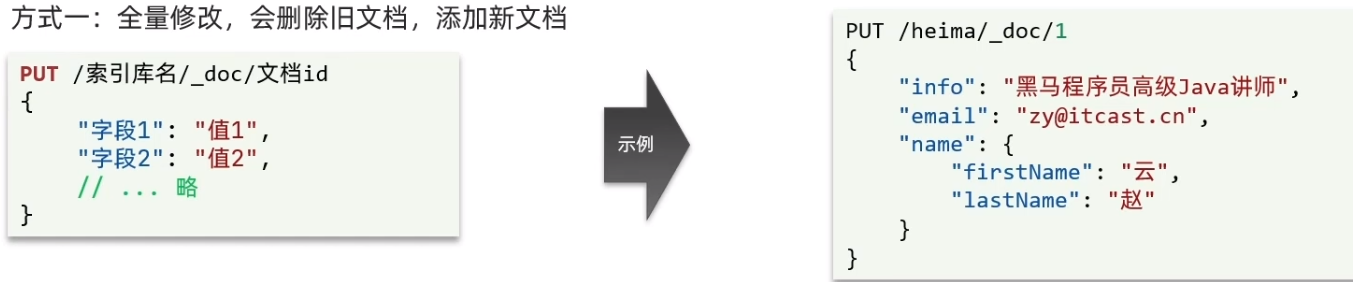
# 修改文档 PUT /edevp/_doc/1 { "info": "黑马程序员Java讲师", "email":"", "name":{ "firstName":"云", "lastName":"赵" } } - 方式二:增量修改,修改指定字段

# 修改文档字段 POST /edevp/_update/1 { "doc":{ "email":"" } } 2.2、索引库

2.2.1、mapping

index模式是true,但是不是所有字段都需要创建索引
index为false表示不参与搜索
2.2.2、创建索引库
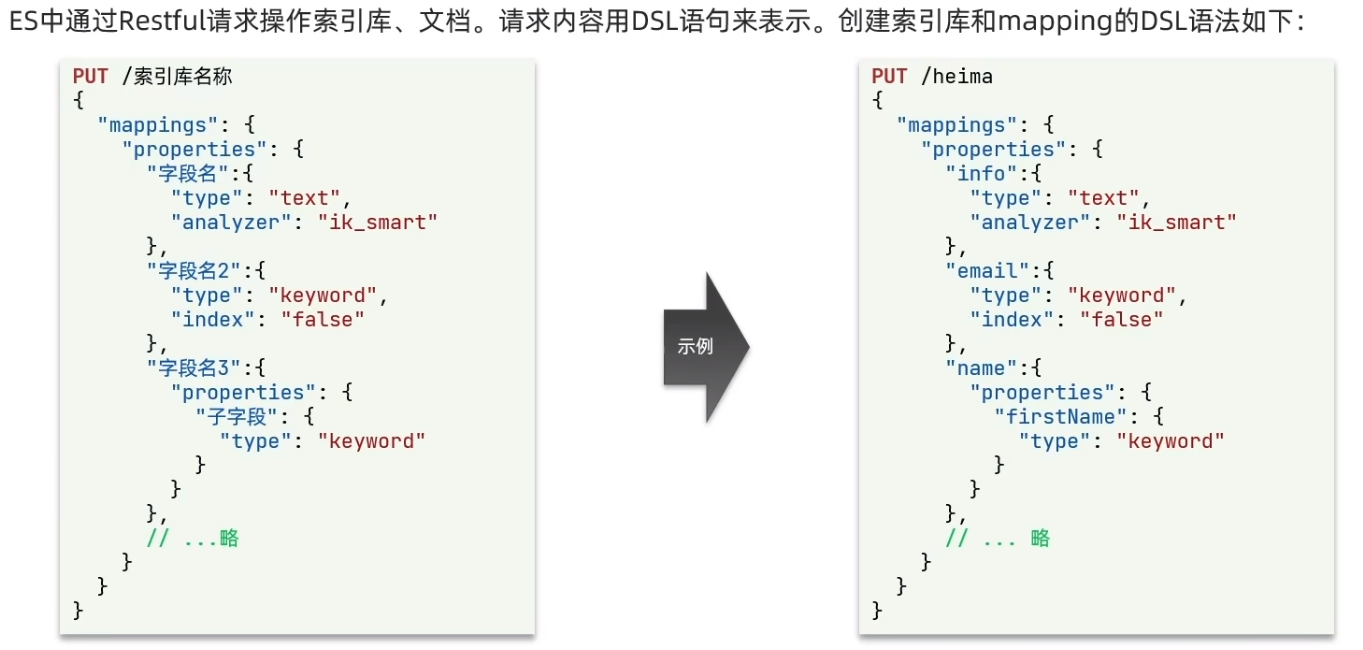
在Kibana的DevTools中Console中执行如下
# 创建索引库 PUT /edevp {
"mappings": {
"properties": {
"info":{
"type": "text", "analyzer": "ik_smart" }, "email":{
"type": "keyword", "index": false }, "name":{
"type": "object", "properties": {
"firstName":{
"type":"keyword" }, "lastName":{
"type":"keyword" } } } } } } 右侧结果是如下表示创建成功
{
"acknowledged" : true, "shards_acknowledged" : true, "index" : "edevp" } 2.2.2.1、字段拷贝
# 创建索引库 PUT /hotel {
"mappings": {
"properties": {
"id":{
"type": "keyword" }, "name":{
"type": "text", "analyzer": "ik_max_word", "copy_to": "all" }, "address":{
"type": "keyword", "index": false }, "price":{
"type":"keyword" }, "score":{
"type":"keyword" }, "brand":{
"type":"keyword", "copy_to": "all" }, "city":{
"type":"keyword" }, "starName":{
"type":"keyword" }, "business":{
"type":"keyword", "copy_to": "all" }, "location":{
"type":"geo_point" }, "pic":{
"type":"keyword", "index": false }, "all":{
"type": "text", "analyzer": "ik_max_word" } } } } 2.2.3、查看、删除索引库
查看索引库语法
GET /索引库名 # 示例 GET /edevp 删除索引库语法
DELETE /索引库名 # 示例 DELETE /edevp 2.2.4、修改索引库
# 修改索引库,添加新字段 PUT /edevp/_mapping {
"properties": {
"age":{
"type": "integer" } } } 2.3、与Mysql对比

2.4、架构
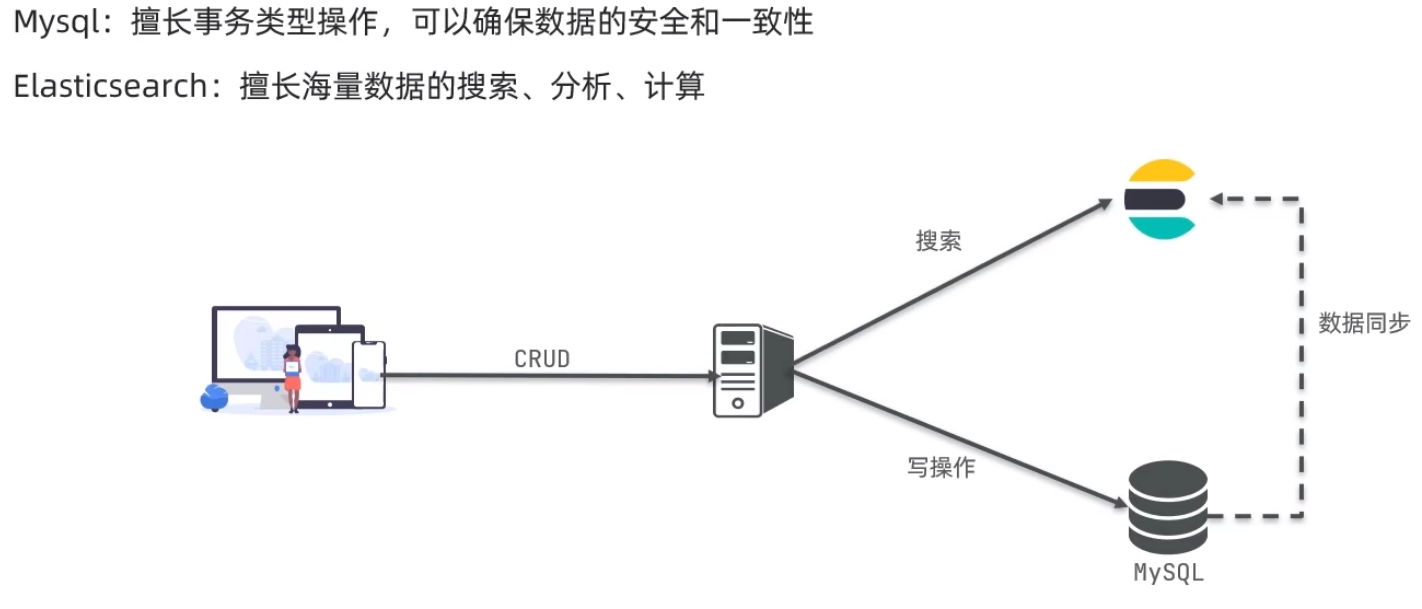
2.5、分词器
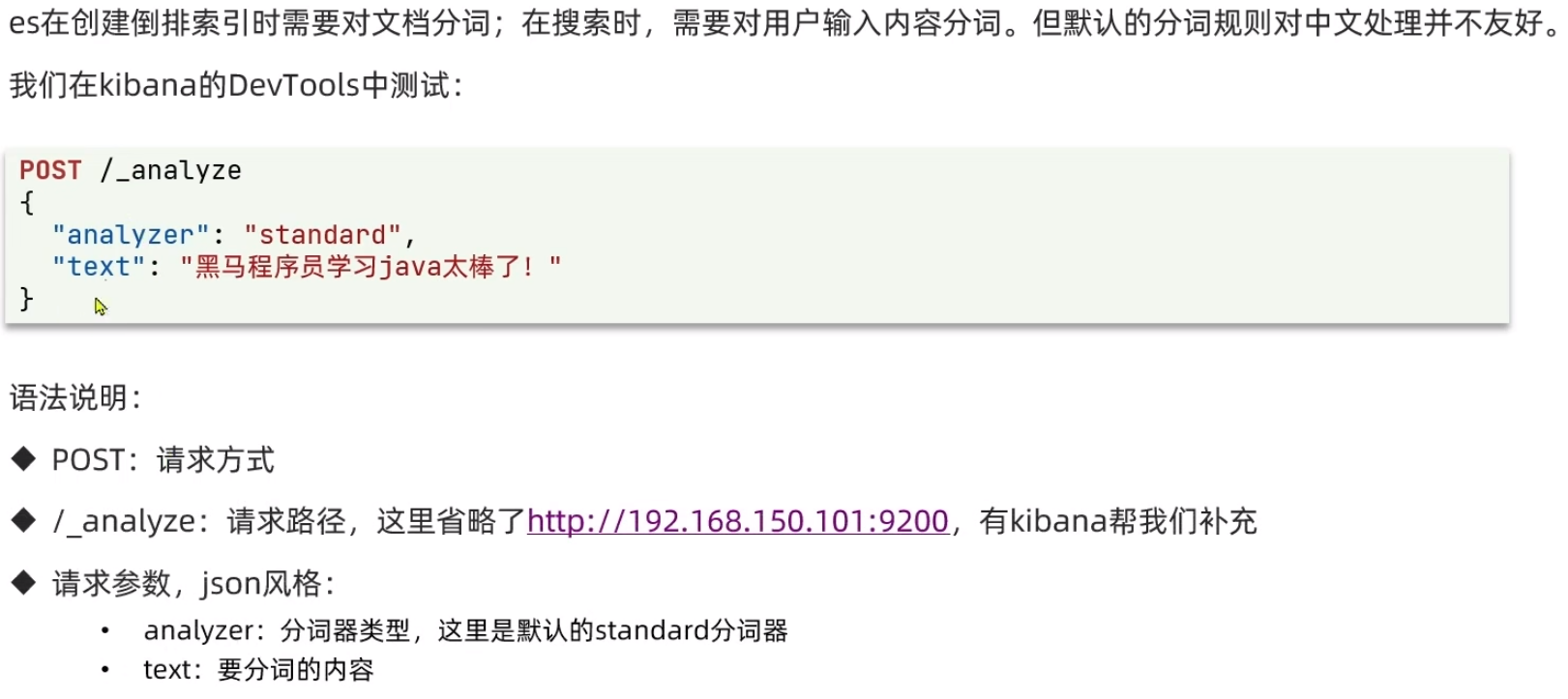
2.5.1、安装IK分词器
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,Elasticsearch的标准分词器,会将中文分为一个一个的字,而不是词,比如:“石原美里”会被分为“石”、“原”、“美”、“里”,这显然是不符合要求的,所以我们需要安装中文分词器IK来解决这个问题。
- 下载
官网地址:https://github.com/medcl/elasticsearch-analysis-ik/releases?page=6
cd /usr/local/elasticsearch wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.5.1/elasticsearch-analysis-ik-7.5.1.zip - 解压
mkdir ik unzip -d ./ik elasticsearch-analysis-ik-7.5.1.zip - 安装
mv ik ./plugins/ # 重启es docker restart elasticsearch - 查看es日志
发现有loaded plugin [analysis-ik]字样说明成功
2.5.2、IK分词器配置和停用词条字典
首先编辑 ik 的配置文件 /usr/local/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置
comment>
<entry key="ext_dict">ext.dic
entry>
<entry key="ext_stopwords">stopword.dic
entry>
<entry key="remote_ext_dict">http://localhost:8162/test/downloadExtDic?fileName=extWords.dic
entry>
<entry key="remote_ext_stopwords">http://localhost:8162/test/downloadExtDic?fileName=stopWords.dic
entry>
properties> 在/usr/local/elasticsearch/plugins/ik/config/新建ext.dic
程序员 程序 测试 edevp 在stopword.dic中添加
的 你 吗 哦 了 嗯 改完之后需要重启es
2.5.3、IK分词器的两种分词模式
两种分词模式:ik_max_word和ik_smart模式
ik_max_word(常用) 会将文本做最细粒度的拆分
ik_smart会做最粗粒度的拆分
2.5.4、同义词典使用
意思相同的词,在搜索时应该同时查出来,比如“馒头”和“馍”,这种情况叫做同义词查询 注意:扩展词和停用词时在索引的时候使用,同义词是检索的时候 1、创建synonym.txt vi synonym.txt 输入同义词 2、重启es /usr/elasticsearch/bin/elasticsearch 3、使用是指定synonym.text 前缀路径为:/usr/elasticsearch/config/ analysis:为自己创建的目录 2.6、地理坐标
- geo_point
由维度(latitude)和经度(longitude)确定一个点。例如“21.,120.” - geo_shape
由多个geo_point组成的几何图形,例如一条线,“LINESTRING(-77.13123 38.,-77. 38.)”
3、部署
3.1、创建docker子网络
docker network create mynet 3.2、安装ElasticSearch
3.3、拉取镜像
docker search elasticsearch docker pull docker.elastic.co/elasticsearch/elasticsearch:7.5.1 3.4、查看镜像
docker images
3.5、创建文件夹
mkdir -p /usr/local/elasticsearch/config mkdir -p /usr/local/elasticsearch/data mkdir -p /usr/local/elasticsearch/plugins echo "http.host: 0.0.0.0">>/usr/local/elasticsearch/config/elasticsearch.yml 3.6、文件夹赋权
chmod -R 777 /usr/local/elasticsearch 3.7、安装
docker run --name elasticsearch --network mynet -p 9100:9100 -p 9200:9200 \ -p 9300:9300 \ -e "discovery.type=single-node" \ -e ES_JAVA_OPTS="-Xms256m -Xmx256m" \ -v /usr/local/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \ -v /usr/local/elasticsearch/data:/usr/share/elasticsearch/data \ -v /usr/local/elasticsearch/plugins:/usr/share/elasticsearch/plugins \ -d docker.elastic.co/elasticsearch/elasticsearch:7.5.1 参数说明
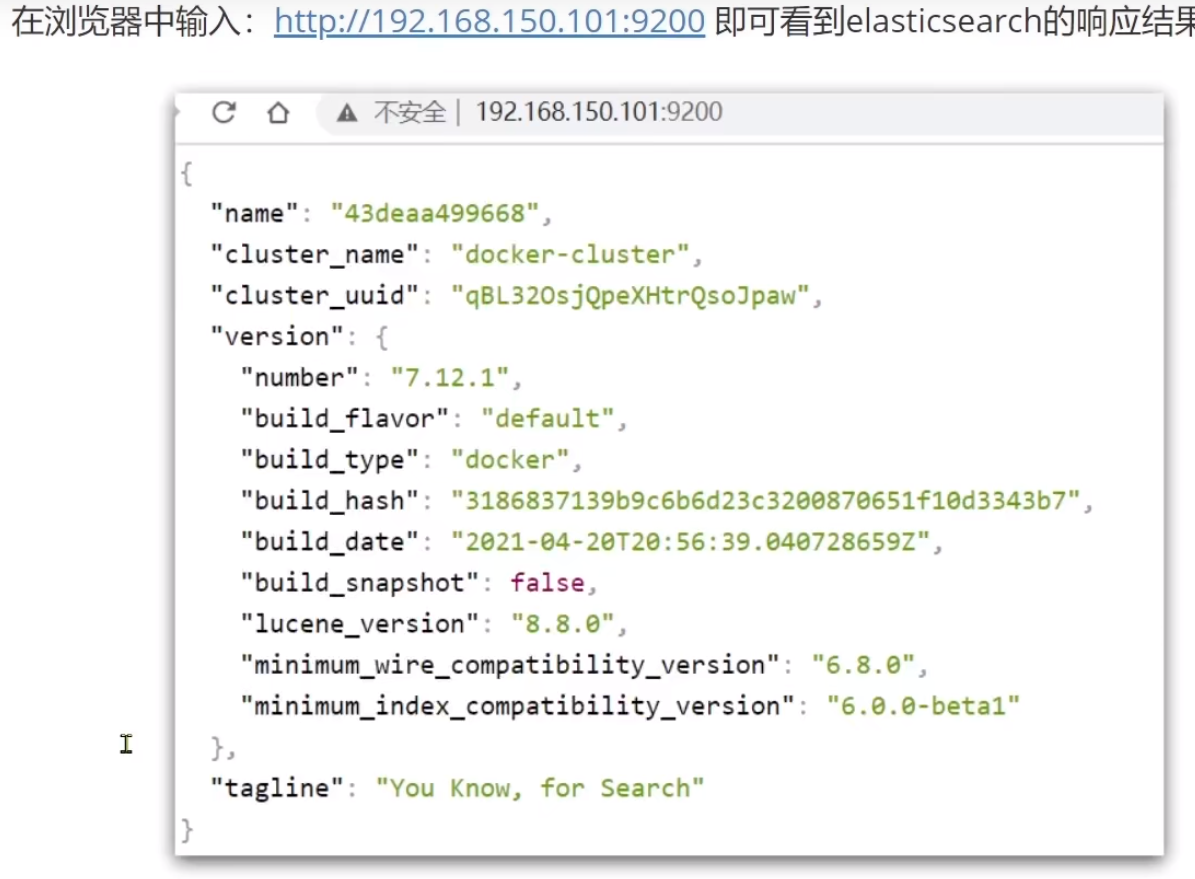
# -d 后台运行 # --name elasticsearch 容器名称 # -p 9200:9200 -p 9300:9300 映射端口 # --network elasticsearch_net 指定网络 # -v 具名共享目录 # -e:设置环境变量 # -e "privileged=true" 配置访问权限 # -e "discovery.type=single-node" 指定elasticsearch部署模式单机运行 # -e "cluster.name=es-docker-cluster" 设置集群名称 # elasticsearch 指定镜像 # 如果启动不了,可以减小内存设置:-e ES_JAVA_OPTS="-Xms512m -Xmx512m" # -v elasticsearch_volume:/root 具名共享目录 # -e "privileged=true" 配置访问权限 # 开始没有配置访问权限,es一直起不起来,加了权限就可以起来了 3.8、运行效果
三、logstash
1、概念
2、安装
2.1、拉取镜像
docker pull docker.elastic.co/logstash/logstash:7.5.1 2.2、启动
docker run -p 5044:5044 --name logstash --network mynet -d docker.elastic.co/logstash/logstash:7.5.1 2.3、COPY配置文件至本地
COPY配置文件至本地 mkdir -p /usr/local/logstash docker cp logstash:/usr/share/logstash/config /usr/local/logstash/ docker cp logstash:/usr/share/logstash/data /usr/local/logstash/ docker cp logstash:/usr/share/logstash/pipeline /usr/local/logstash/ chmod 777 -R /usr/local/logstash 2.4、移除容器
移除容器 docker rmi logstash 2.5、修改配置文件
配置logstash.yml,也可以不配置
xpack.monitoring.elasticsearch.username: "logstash_system" xpack.monitoring.elasticsearch.password: "" xpack.monitoring.elasticsearch.url: ["http://elasticsearch:9200"] vi logstash.conf
2.6、启动logstash
docker run -d --user root \ --name logstash \ --network mynet \ -p 5044:5044 -p 9900:9900 -p 4560:4560 \ -v /usr/local/logstash/config:/usr/share/logstash/config \ -v /usr/local/logstash/pipeline:/usr/share/logstash/pipeline \ -v /usr/local/logstash/data:/usr/share/logstash/data \ -e TZ=Asia/Shanghai \ docker.elastic.co/logstash/logstash:7.5.1 docker exec -it logstash bash 2.3、配置Elasticsearch
参考:https://www.pianshen.com/article//
由于/usr/local/logstash/config/pipeline.yml中配置如下
- pipeline.id: main path.config: "/usr/share/logstash/pipeline" 所以修改配置应该去/usr/local/logstash/pipeline/logstash.conf
[root@localhost ~]# docker exec -it logstash bash bash-4.2$ ls bin data lib logstash-core-plugin-api pipeline x-pack config Gemfile LICENSE.txt modules tools CONTRIBUTORS Gemfile.lock logstash-core NOTICE.TXT vendor bash-4.2$ cd pipeline/ bash-4.2$ ls logstash.conf bash-4.2$ vi logstash.conf # 修改为如下 input {
tcp {
mode => "server" host => "0.0.0.0" port => 5044 codec => json_lines } } output {
elasticsearch{
hosts => ["elasticsearch:9200"] } stdout {
codec => rubydebug } } 如果是集群不是es,则可以配置多个host
output {
stdout {
codec => rubydebug } elasticsearch {
hosts => ["devcdhsrv1:9200","devcdhsrv2:9200","devcdhsrv3:9200"] user => "" password => "" index => "%{[@metadata][index_prefix]}-%{+YYYY.MM.dd}" codec => json } } 2.4、重启logstash
docker restart logstash 2.5、查看docker日志
docekr logs -f logstash 四、kibana
1、概念
提供一个elasticsearch的可视化界面,便于我们操作
2、安装
2.1、拉取镜像
docker pull docker.elastic.co/kibana/kibana:7.5.1 启动
# 简洁版 docker run -p 5601:5601 --name kibana --network mynet -d docker.elastic.co/kibana/kibana:7.5.1 # 可以指定elastic的位置 docker run --name kibana --network mynet -p 5601:5601 -d -e ELASTICSEARCH_URL=http://192.168.2.153:9200 kibana:5.6.14 # 可以指定elastic的位置,因为在同一个网络直接使用es名称 docker run --name kibana --network mynet -p 5601:5601 -d -e ELASTICSEARCH_URL=http://elasticsearch:9200 kibana:7.5.1 2.2、访问
http://127.0.0.1:5601/app/kibana
2.3、测试es是否连接
2.4、测试分词器
测试ik中文分词器
# 测试中文分词器 POST /_analyze {
"text": "Edevp的程序员学习java太棒了", "analyzer": "ik_max_word" } 五、filebeat采集日志方案
参考:https://blog.csdn.net/Blueeyedboy521/article/details/
1、采集普通log日志文件
1.1、filebeat配置
拷贝一份filebeat.example.yml重命名为filebeat.yml修改配置如下
#=========================== Filebeat inputs ============================= filebeat.inputs: - type: log enabled: true # 要抓取的文件路径 paths: - /data/logs/oh-coupon/info.log - /data/logs/oh-coupon/error.log # 添加额外的字段 fields: log_source: oh-coupon fields_under_root: true # 多行处理 # 不以"yyyy-MM-dd"这种日期开始的行与前一行合并 multiline.pattern: ^\d{
4}-\d{
1,2}-\d{
1,2} multiline.negate: true multiline.match: after # 5秒钟扫描一次以检查文件更新 scan_frequency: 5s # 如果文件1小时都没有更新,则关闭文件句柄 close_inactive: 1h # 忽略24小时前的文件 #ignore_older: 24h - type: log enabled: true paths: - /data/logs/oh-promotion/info.log - /data/logs/oh-promotion/error.log fields: log_source: oh-promotion fields_under_root: true multiline.pattern: ^\d{
4}-\d{
1,2}-\d{
1,2} multiline.negate: true multiline.match: after scan_frequency: 5s close_inactive: 1h ignore_older: 24h #================================ Outputs ===================================== #-------------------------- Elasticsearch output ------------------------------ #output.elasticsearch: # Array of hosts to connect to. # hosts: ["localhost:9200"] # Optional protocol and basic auth credentials. #protocol: "https" #username: "elastic" #password: "changeme" #----------------------------- Logstash output -------------------------------- output.logstash: # The Logstash hosts hosts: ["localhost:5044"] # Optional SSL. By default is off. # List of root certificates for HTTPS server verifications #ssl.certificate_authorities: ["/etc/pki/root/ca.pem"] # Certificate for SSL client authentication #ssl.certificate: "/etc/pki/client/cert.pem" # Client Certificate Key #ssl.key: "/etc/pki/client/cert.key" 1.2、logstash配置
vi /usr/local/logstash/pipeline/logstash.conf # 配置如下 input {
beats {
port => "5044" } } filter {
grok {
match => {
"message" => "%{TIMESTAMP_ISO8601:log_date}\s+\[%{LOGLEVEL:log_level}" } } date {
match => ["log_date", "yyyy-MM-dd HH:mm:ss.SSS"] target => "@timestamp" } } output {
if [log_source] == "jr-gdb" {
elasticsearch {
hosts => [ "elasticsearch:9200" ] index => "jr-gdb-%{+YYYY.MM.dd}" # user => "logstash_internal" # password => "" } } if [log_source] == "jr-sgb" {
elasticsearch {
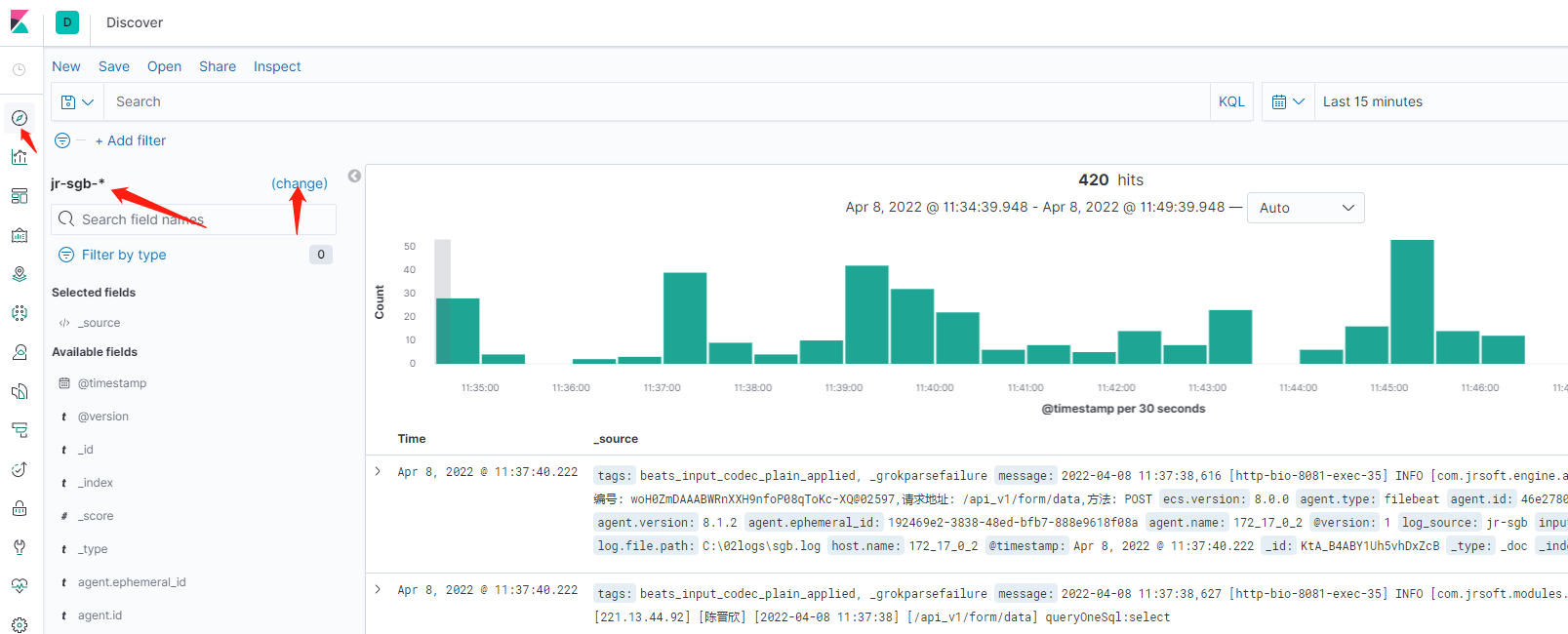
hosts => [ "elasticsearch:9200" ] index => "jr-sgb-%{+YYYY.MM.dd}" # user => "logstash_internal" # password => "" } } } 1.3、kibana查看
然后在Discover的页面中查看
2、采集nginx日志
https://blog.csdn.net/_/article/details/
3、filebeat多行采集log4j日志
参考:https://www.amd5.cn/atang_4152.html
六、elasticsearch集群部署
https://blog.csdn.net/weixin_/article/details/?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_title~default-4.pc_relevant_default&spm=1001.2101.3001.4242.3&utm_relevant_index=7
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/222082.html原文链接:https://javaforall.net


