

文档包含以下内容:
- 安装配置
- 常用参数详解
- 常用测试用例
1.2 产品版本
|
产品名称 |
版本 |
描述 |
|---|---|---|
| Vdbench | 5.04.07 | 性能测试工具 |
| Linux 客户端 | CentOS 7.6 X64 | Linux 操作系统 |
| Windows 客户端 | Windows 2012 R2 X64 | Windows 操作系统 |
- 部门工程师
- 合作伙伴技术工程师
- 客户技术工程师
二、 下载地址
官网下载链接: Vdbench Downloads
3.1 Linux 安装步骤
- Linux 对应版本操作系统的 iso
- vdbench50407.zip

|
|
|
|
|
|
|
|
4、安装 java
|
|
|
|
|
|

- jre-8u241-windows-x64.exe
- vdbench50407.zip
c) 完成安装

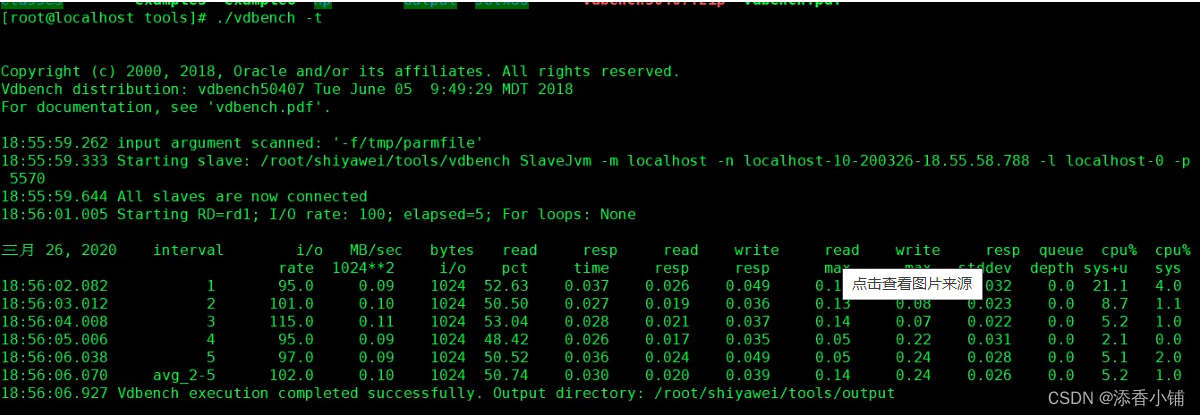
看到结尾输入如下,则说明安装成功:

4.2.4 运行定义(RD)
|
|
|
|
|
|
6.1.2 文件存储常用测试脚本
|
|
|
|
6.2.2 文件存储常用测试脚本
|
|
七、 测试结果解读
- errorlog.html:当为测试启用了数据验证(-jn)时,它可包含一些数据块中的错误的相关信息
- flatfile.html:包含 Vdbench 生成的一种逐列的 ASCII 格式的信息。
- histogram.html:种包含报告柱状图的响应时间、文本格式的文件。
- logfile.html:包含 Java 代码写入控制台窗口的每行信息的副本。logfile.html 主要用于调试用途
- parmfile.html:显示已包含用于测试的每项内容的最终结果
- resourceN-M.html、resourceN.html、resourceN.var_adm_msgs.html:摘要报告、stdout/stderr 报告、主机 N 的摘要报告。
- sdN.histogram.html、sdN.html:每个 N 存储定义的柱状图和存储定义 “N” 报告。
- summary.html:主要报告文件,显示为在每个报告间隔的每次运行生成的总工作负载,以及除第一个间隔外的所有间隔的加权平均值。
|
|
7.3.2 文件存储 sunmary.html 说明
|
|
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/222333.html原文链接:https://javaforall.net


