
代码在 https://github.com/crownpku/rasa_nlu_chi
自然语言理解(NLU)系统是问答系统、聊天机器人等更高级应用的基石。基本的NLU工具,包括实体识别和意图识别两个任务。
已有的NLU工具,大多是以服务的方式,通过调用远程http的restful API来对目标语句进行解析完成上述两个任务。这样的工具有Google的API.ai, Microsoft的Luis.ai, Facebook的Wit.ai等。刚刚被百度收购的Kitt.ai除了百度拿出来秀的语音唤醒之外,其实也有一大部分工作是在NLU上面,他们很有启发性的的Chatflow就包含了一个自己的NLU引擎。
(话说,现在.ai的域名都好贵呢…其实是安圭拉的国家域名,这个小岛就这么火了…)
以上这些工具,一边为用户提供NLU的服务,一边也通过用户自己上传的大量标注和非标注数据不断训练和改进自己的模型。而对于数据敏感的用户来说,开源的NLU工具如Rasa.ai就为我们打开了另一条路。更加重要的是,这样的开源工具可以本地部署,自己针对实际需求训练和调整模型,据说对一些特定领域的需求效果要比那些通用的在线NLU服务还要好很多。
我们在这里就简单介绍使用Rasa NLU构建一个本地部署的特定领域的中文NLU系统。
Rasa NLU本身是只支持英文和德文的。中文因为其特殊性需要加入特定的tokenizer作为整个流水线的一部分。我加入了jieba作为我们中文的tokenizer,这个适用于中文的rasa NLU的版本代码在github上。
语料获取及预处理
Rasa NLU的实体识别和意图识别的任务,需要一个训练好的MITIE的模型。这个MITIE模型是非监督训练得到的,类似于word2vec中的word embedding。
要训练这个MITIE模型,我们需要一个规模比较大的中文语料。最好的方法是用对应自己需求的语料,比如做金融的chatbot就多去爬取些财经新闻,做医疗的chatbot就多获取些医疗相关文章。
我使用的是awesome-chinese-nlp中列出的中文wikipedia dump和百度百科语料。其中关于wikipedia dump的处理可以参考这篇帖子。
仅仅获取语料还不够,因为MITIE模型训练的输入是以词为单位的。所以要先进行分词,我们使用结巴分词。
安装结巴分词:
$ pip install jieba 将一个语料文件分词,以空格为分隔符:
$ python -m jieba -d " " ./test > ./test_cut MITIE模型训练
我们把所有分好词的语料文件放在同一个文件路径下。接下来我们要训练MITIE模型。
首先将MITIE clone下来:
$ git clone https://github.com/mit-nlp/MITIE.git 我们要使用的只是MITIE其中wordrep这一个工具。我们先build它。
$ cd MITIE/tools/wordrep $ mkdir build $ cd build $ cmake .. $ cmake --build . --config Release 然后训练模型,得到total_word_feature_extractor.dat。注意这一步训练会耗费几十GB的内存,大概需要两到三天的时间。。。
$ ./wordrep -e /path/to/your/folder_of_cutted_text_files 我用中文wikipedia和百度百科语料生成了一个total_word_feature_extractor_chi.dat,分享如下。
链接:http://pan.baidu.com/s/1micEF0G 密码:opli 对于一些比较general的NLU使用场景,这个应该是够用了。
构建rasa_nlu语料和模型
- 将rasa_nlu_chi clone下来并安装:
$ git clone https://github.com/crownpku/rasa_nlu_chi.git $ cd rasa_nlu_chi $ python setup.py install - 构建尽可能多的示例数据来做意图识别和实体识别的训练数据:
data/examples/rasa/demo-rasa_zh.json
格式是json,例子如下。’start’和’end’是实体对应在’text’中的起止index。
{ "text": "找个吃拉面的店", "intent": "restaurant_search", "entities": [ { "start": 3, "end": 5, "value": "拉面", "entity": "food" } ] }, { "text": "这附近哪里有吃麻辣烫的地方", "intent": "restaurant_search", "entities": [ { "start": 7, "end": 10, "value": "麻辣烫", "entity": "food" } ] }, { "text": "附近有什么好吃的地方吗", "intent": "restaurant_search", "entities": [] }, { "text": "肚子饿了,推荐一家吃放的地儿呗", "intent": "restaurant_search", "entities": [] } 这里有个小bug,就是这个entity一定要刚刚好是text被jieba分词后其中的一个词。如果jieba分词的结果中分错了你设定的entity这个词就会报错。所以写这个示例数据的时候,要参考jieba对text的分词结果来写。
上述bug已解决。
- 修改pipeline的设置
对于中文我们现在有两种pipeline:
使用 MITIE+Jieba:
[“nlp_mitie”, “tokenizer_jieba”, “ner_mitie”, “ner_synonyms”, “intent_classifier_mitie”]
这种方式训练比较慢,效果也不是很好,最后出现的intent也没有分数排序。
我们推荐使用下面的pipeline:
MITIE+Jieba+sklearn (sample_configs/config_jieba_mitie_sklearn.json):
[“nlp_mitie”, “tokenizer_jieba”, “ner_mitie”, “ner_synonyms”, “intent_featurizer_mitie”, “intent_classifier_sklearn”]
这里也可以看到Rasa NLU的工作流程。”nlp_mitie”初始化MITIE,”tokenizer_jieba”用jieba来做分词,”ner_mitie”和”ner_synonyms”做实体识别,”intent_featurizer_mitie”为意图识别做特征提取,”intent_classifier_sklearn”使用sklearn做意图识别的分类。
2017.11.16更新: 关于加入jieba自定义词典,暂时没有找到非常优雅的做法。现在的版本,需要用户把jieba自定义词典放到rasa_nlu_chi/jieba_userdict/下面。系统在训练和预测时都会自动寻找并导入jieba分词。
- 训练Rasa NLU的模型
$ python -m rasa_nlu.train -c sample_configs/config_jieba_mitie_sklearn.json 这样就会生成一个类似model_-的文件在 /models/your_project_name 的文件夹里。
如果config文件中没有project_name,模型会存储在默认的 /models/default 文件夹下。
搭建本地rasa_nlu服务
- 启动rasa_nlu的后台服务:
python -m rasa_nlu.server -c sample_configs/config_jieba_mitie_sklearn.json - 打开一个新的terminal,我们现在就可以使用curl命令获取结果了, 举个例子:
$ curl -XPOST localhost:5000/parse -d '{"q":"我发烧了该吃什么药?", "project": "rasa_nlu_test", "model": "model_-"}' | python -mjson.tool % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 652 0 552 100 100 157 28 0:00:03 0:00:03 --:--:-- 157 { "entities": [ { "end": 3, "entity": "disease", "extractor": "ner_mitie", "start": 1, "value": "发烧" } ], "intent": { "confidence": 0.31861, "name": "medical" }, "intent_ranking": [ { "confidence": 0.31861, "name": "medical" }, { "confidence": 0., "name": "restaurant_search" }, { "confidence": 0.37397, "name": "affirm" }, { "confidence": 0., "name": "goodbye" }, { "confidence": 0.010374, "name": "greet" } ], "text": "我发烧了该吃什么药?" } Rasa UI界面
上面可以看到这种后台服务、前台curl的方式,其实已经可以代替之前提到的一大票云端的NLU服务了。
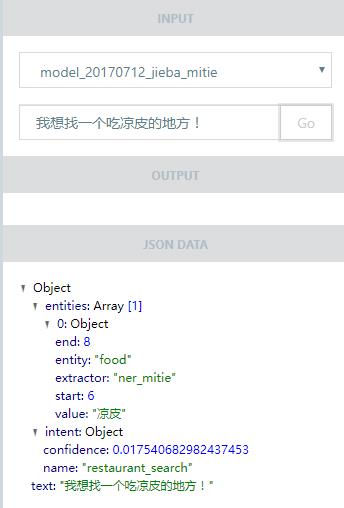
有热心的前端大牛还做了一个Rasa UI,提供Rasa的界面。理论上是要将前面提到的示例数据的添加、模型的训练以及服务的监控等等都做成一个漂亮的web界面。只是现在还开发的非常不完善,大部分的功能还都没有加进去。
有兴趣的朋友可以clone下来装一个试试。效果如下:

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/222424.html原文链接:https://javaforall.net


