
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
用Python爬虫来爬写真网图片
1.我们先要知道Python爬虫的原理
基本的Python爬虫原理很简单,分为三步
- 获取网页源码
- 通过分析源码并通过代码来获取其中想要的内容
- 进行下载或其他操作
话不多说直接开干
先准备上我们的目标网页
放图片不给过审。。。
开始
我用的工具是:JetBrains PyCharm 2019.1.1 x64
首先导入几个包
- import requests
- import urllib.request
- import re
- from bs4 import BeautifulSoup
- import os

遍历所有网页
先来看看网页结构
分页显示
 根据观察,除了第一页,其他页后缀都为*.html一共13页
根据观察,除了第一页,其他页后缀都为*.html一共13页
所以我们可以通过for遍历所有页码
for num in range(13):
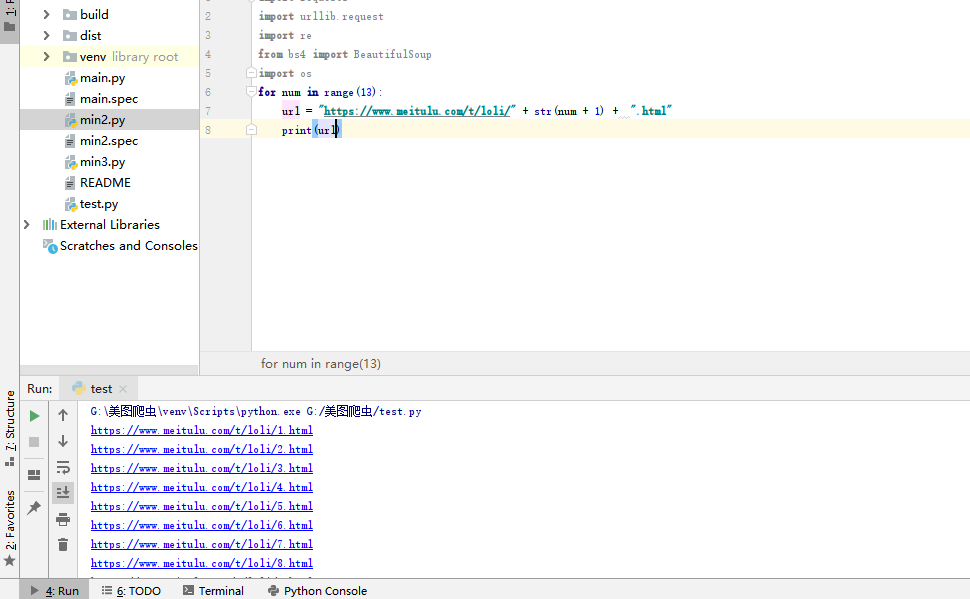
可以看到我们吧所有页面都便利了一遍
但是第一页比较奇葩他没有在浏览器里显示出来,应该是index.html
所以我们单独把第一页拎出来
最后就是这样:
for num in range(13):
url = "https://www.meitulu.com/t/loli/" + str(num + 1) + ".html"
if num == 0:
url = "https://www.meitulu.com/t/loli/" #第一页比较奇葩
接下来就是获取遍历到的每一页的HTML了
response = requests.get(url)
response.encoding='utf-8'
html = response.text
soup = BeautifulSoup(html,"html.parser")
这段主要就是向URL发送GET请求
把获取到的HTML代码存放在soup变量里
遍历所有图集
通过检查元素,我们可以看到每个图集对应的链接:
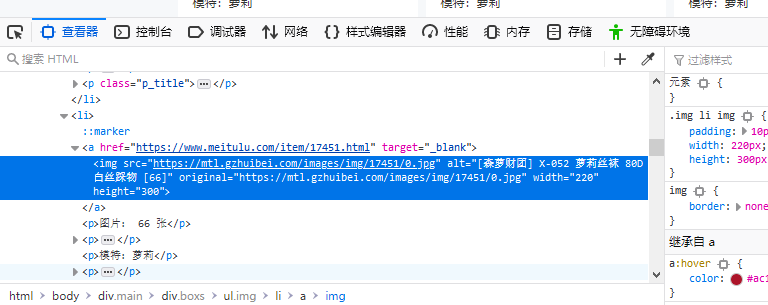 我们先提前初始化好图集链接
我们先提前初始化好图集链接
youngerSister_url = [] # 初始化图集链接list
既然是链接,所以我们要获取所有标签中的src,用来进入每个图集
a_link = soup.find_all('a') #所有a标签
for link in a_link: #遍历所有链接
u = link.get("href")
由于一个页面中不止有图集链接,也有其他链接,所以我们要进行筛选
if u != None:
u2 = re.sub("\d","",u) #获取连接类型
if u2 == "https://www.meitulu.com/item/.html":
if not(u in youngerSister_url):
youngerSister_url.append(u) #添加进列表
print("获取到" + str(len(youngerSister_url)) + "份图集")
os.system('cls')
具体原理大概就这样
接下来只用把每一页的图集都遍历一遍,并且用
urllib.request.urlretrieve(p_url, jpg_name) #下载
来下载
结果
一共获取到将近五万张图片
源码在这:
import requests
import urllib.request
import re
from bs4 import BeautifulSoup
import os
# 获取文件名
file_names = os.listdir("./") #获取所有文件名
#----------------------获取
youngerSister_url = [] # 初始化女生链接list
for num in range(13):
url = "https://www.meitulu.com/t/loli/" + str(num + 1) + ".html"
if num == 0:
url = "https://www.meitulu.com/t/loli/" #第一页比较奇葩
response = requests.get(url)
response.encoding='utf-8'
html = response.text
soup = BeautifulSoup(html,"html.parser")
a_link = soup.find_all('a') #所有a标签
for link in a_link: #遍历所有链接
u = link.get("href")
if u != None:
u2 = re.sub("\d","",u) #获取连接类型
if u2 == "https://www.meitulu.com/item/.html":
if not(u in youngerSister_url):
youngerSister_url.append(u) #添加进列表
print("获取到" + str(len(youngerSister_url)) + "份图集")
os.system('cls')
print("共" + str(len(youngerSister_url)) + "个女生图集")
print("开始下载")
for link in range(len(youngerSister_url)): #进入图集
print("开始下载第" + str(link + 1) + "份图集")
# ----------------------获取
url = youngerSister_url[link]
response = requests.get(url)
response.encoding = 'utf-8'
html = response.text
soup = BeautifulSoup(html, "html.parser")
a_link = soup.find_all('p') # 所有a标签
for link in a_link: # 获取图片数量
p_text = link.text
if not p_text.find("图片数量:"):
print(p_text)
num_start = p_text.index(":") + 2 # 查找字符串开始位置
num_over = p_text.index("张") - 1 # 查找字符串结束位置
p_num = int(p_text[num_start:num_over])
break # 结束循环
num_url = re.sub("\D", "", url) # 替换非数字字符
print("女生编号:" + num_url)
for link in range(p_num): # 循环图片次数遍
jpg_name = num_url + "_"+ str(link + 1) + ".jpg" #图片名
if not(jpg_name in file_names): #文件如果存在就跳过
p_url = "https://mtl.gzhuibei.com/images/img" + "/" + num_url + "/" + str(link + 1) + ".jpg"
html_head = requests.head(p_url) # 用head方法去请求资源头
re_code = html_head.status_code #返回请求值
print(p_url)
print("进度" + str(link + 1) + "/" + str(p_num))
if re_code == 200:
urllib.request.urlretrieve(p_url, jpg_name) #下载
else:
print("该连接无效,跳过!")
print("第" + str(link + 1) + "份下载完成!")
input("全部下载完成,按回车键退出")
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/223417.html原文链接:https://javaforall.net


