
指数加权移动平均法(EWMA)
https://www.cnblogs.com/jiangxinyang/p/9705198.html
本文内容来自于吴恩达深度学习公开课
1、概述
加权移动平均法,是对观察值分别给予不同的权数,按不同权数求得移动平均值,并以最后的移动平均值为基础,确定预测值的方法。采用加权移动平均法,是因为观察期的近期观察值对预测值有较大影响,它更能反映近期变化的趋势。
指数移动加权平均法,是指各数值的加权系数随时间呈指数式递减,越靠近当前时刻的数值加权系数就越大。
指数移动加权平均较传统的平均法来说,一是不需要保存过去所有的数值;二是计算量显著减小。
2、算法理解
引入一个例子,例子为美国一年内每天的温度分布情况,具体如下图所示
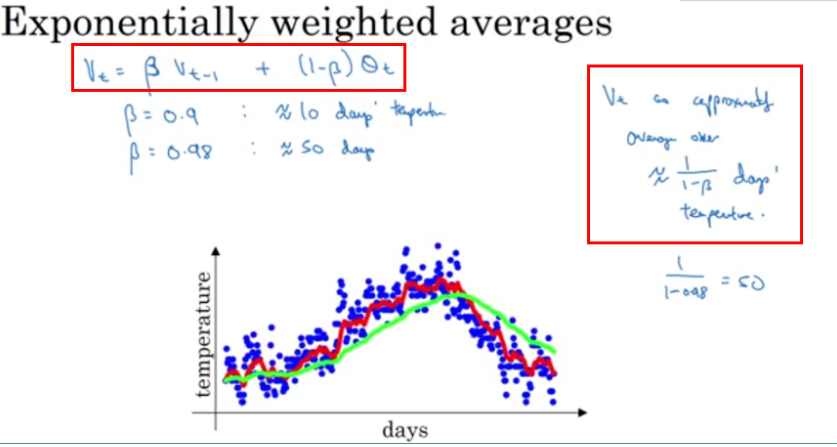

EWMA 的表达式如下:
vt=βvt−1+(1−β)θt
上式中 θt
为时刻 t 的实际温度;系数 β 表示加权下降的速率,其值越小下降的越快;vt 为 t
时刻 EWMA 的值。
在上图中有两条不同颜色的线,分别对应着不同的 β
值。
当 β=0.9
时,有 vt=0.9vt−1+0.1θt
,对应着图中的红线,此时虽然曲线有些波动,但总体能拟合真实数据
当 β=0.98
时,有 vt=0.98vt−1+0.02θt
,对应着图中的绿线,此时曲线较平,但却有所偏离真实数据
在 t=0
时刻,一般初始化 v0=0 ,对 EWMA 的表达式进行归纳可以将 t
时刻的表达式写成:
vt=(1−β)(θt+βθt−1+…+βt−1θ1)
从上面式子中可以看出,数值的加权系数随着时间呈指数下降。在数学中一般会以 1e
来作为一个临界值,小于该值的加权系数的值不作考虑,接着来分析上面 β=0.9 和 β=0.98
的情况。
当 β=0.9
时,0.910 约等于 1e
,因此认为此时是近10个数值的加权平均。
当 β=0.98
时,0.950 约等于 1e
,因此认为此时是近50个数值的加权平均。这种情况也正是移动加权平均的来源。
具体的分析如下图所示:

3、偏差修正
在初始化 v0=0
时实际上会存在一个问题。具体的如下图所示:
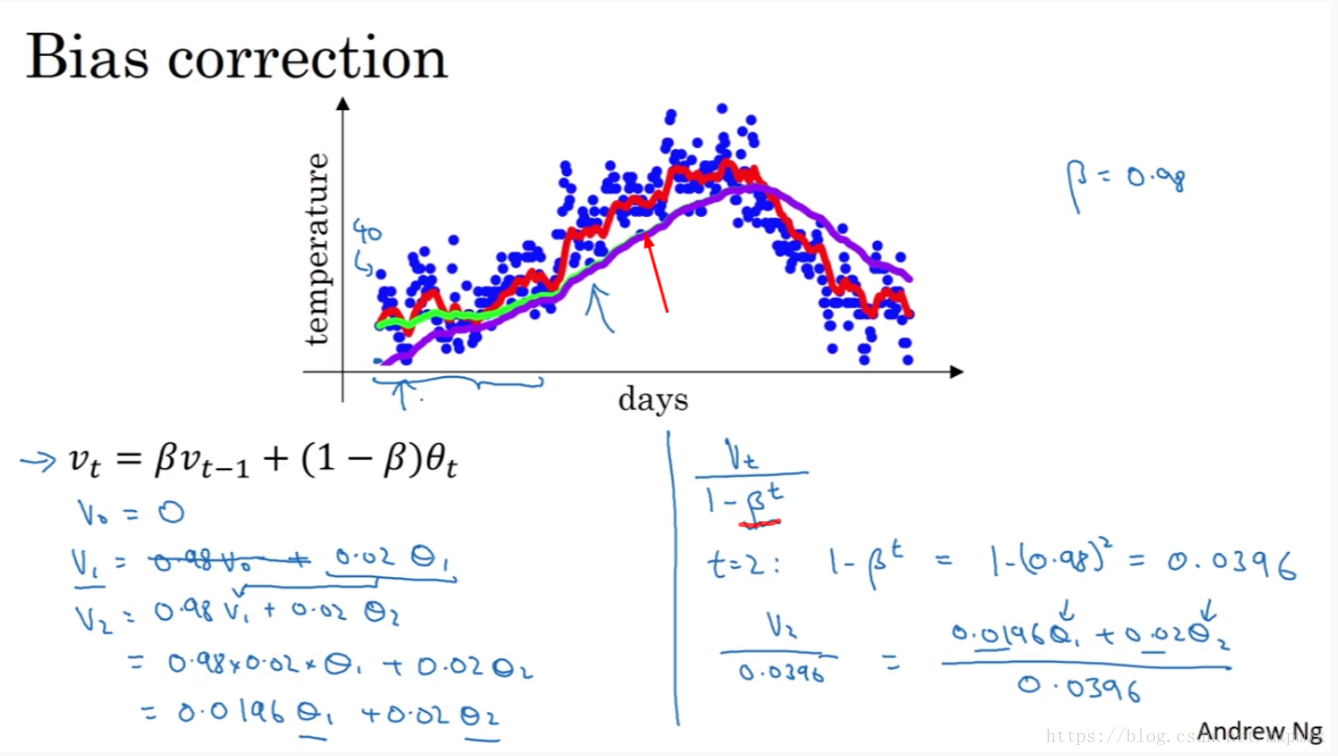
从上图中可以看出有一条绿色和紫色的曲线,都是对应于 β=0.98
时的曲线。理想状况下应该是绿色的曲线,但当初始化 v0=0
时却会得到紫色的曲线,这是因为初始化的值太小,导致初期的数值都偏小,而随着时间的增长,初期的值的影响减小,紫色的曲线就慢慢和绿色的曲线重合。我们对公式做一些修改:
vt=βvt−1+(1−β)θt1−βt
当 t很小时,分母可以很好的放大当前的数值;当 t很大时,分母的数值趋于1,对当前数值几乎没有影响。
EWMA 主要是被应用在动量优化算法中,比如Adam算法中的一阶矩和二阶矩都采用了上面修改后的EWMA算法。
深入解析TensorFlow中滑动平均模型与代码实现
2018年08月09日 21:00:56 无敌的白金之星 阅读数:2271
因为本人是自学深度学习的,有什么说的不对的地方望大神指出
指数加权平均算法的原理
偏差修正
指数加权平均值通常都需要偏差修正,TensorFlow中提供的ExponentialMovingAverage()函数也带有偏差修正。
滑动平均模型的代码实现
看到这里你应该大概了解了滑动平均模型和偏差修正到底是怎么回事了,接下来把这个想法对应到TensorFlow的代码中。
# 1、定义训练的轮数,需要用trainable=False参数指定不训练这个变量, # 避免这个变量被计算滑动平均值 global_step = tf.Variable(0, trainable=False) # 2、给定滑动衰减率和训练轮数,初始化滑动平均类 # 定训练轮数的变量可以加快训练前期的迭代速度 variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step) # 3、用tf.trainable_variable()获取所有可以训练的变量列表,也就是所有的w和b # 全部指定为使用滑动平均模型 variables_averages_op = variable_averages.apply(tf.trainable_variables()) # 反向传播更新参数之后,再更新每一个参数的滑动平均值,用下面的代码可以一次完成这两个操作 with tf.control_dependencies([train_step, variables_averages_op]): train_op = tf.no_op(name="train")设置完使用滑动平均模型之后,只需要在每次使用反向传播的时候改为使用run.(train_op)就可以正常执行了。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/225003.html原文链接:https://javaforall.net

![[AI应用与提效-170] – AI龙虾智能体平台OpenClaw详解,包括内部架构和技术实现](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
