
欢迎来到 SOLID 安卓开发系列的最后一篇。这个系列即将结束,今天我们将谈到 SOLID 缩写中的最后一个字母,D:依赖倒置原则(DIP)。
如果你错过了前四篇文章,你可以很容易的从这里开始:
- S: 单一职责原则
- O: 开、闭原则
- L: 里氏替换原则
- I: 接口隔离原则
- D: 依赖倒置原则 (本文)
不再做广告了,我们第五篇最后的原则 –
依赖倒置原则描述的是作为开发者你需要遵循下面两条建议:
a. 高层模块不应该依赖底层模块。两者都应该依赖抽象。
和
b. 抽象不应该依赖细节。细节需要依赖抽象。
简而言之,依赖倒置原则基本上是这样说的:
依赖抽象。不要依赖具体的东西。
迁移到支持依赖倒置原则
为了充分阐述这个原则的核心,我觉得我应该从软件是如何构建的开始谈起 – 采用传统的分层模式。我们看看这个传统的分层软件架构,然后谈谈我们如何把它改成符合 DIP 原则的架构。
在传统的分层模型软件架构设计中,高层级的软件模块依赖低层级的软件模块完成功能。例如,这是一个非常常见的分层结构,你可能已经见过了 (或者你在你的应用中正是这么实现的):
安卓 UI → 业务逻辑 → 数据层
在上面的图表中有三层。UI 层 (在这个例子中是安卓 UI) – 这指的是我们所有的 UI 控件,列表,文字视图,动画和任何安卓 UI 相关的视图。接下来,是业务逻辑层。这一层会实现公共的逻辑业务来支持核心应用功能。它有时候会被认为是 “专家领域层” 或者 “服务层。” 最后,还有一个所有应用数据集中的数据层。数据可以是数据库,API,纯文本,等等 – 这仅仅是一个单一职责的一层,它只负责存储和获取数据。
让我们假设我们有一个费用跟踪应用来允许用户跟踪他们的费用。根据上面传统的模型,当一个用户创建一个新的费用的时候,我们会有三个不同的操作同时发生。
- UI 层:允许用户输入数据。
- 业务层:验证输入的数据是否符合相关的业务逻辑。
- 数据层:允许费用数据的永久性存储。
关于代码,可能看起来像这样:
// In the Android UI layer findViewById(R.id.save_expense).setOnClickListener(new View.OnClickListener() {
public void onClick(View v) {
ExpenseModel expense = //... create the model from the view values BusinessLayer bl = new BusinessLayer(); if (bl.isValid(expense)) {
// Woo hoo! Save it and Continue to next screen/etc } else {
Toast.makeText(context, "Shucks, couldnt save expense. Erorr: " + bl.getValidationErrorFor(expense), Toast.LENGTH_SHORT).show(); } } }); 在业务层,你可能有如下的伪代码:
// in the business layer, return an ID of the expense public int saveExpense(Expense expense) {
// ... some code to check for validity ... then save // ... do some other logic, like check for duplicates/etc DataLayer dl = new DataLayer(); return dl.insert(expense); } 上述代码的问题是它破坏了依赖倒置的原则 – 引用上述条目 (a) : 高层级模块不应该依赖低层级模块。两者都应该依赖抽象。 UI 依赖于一个具体的业务层逻辑的实例,看这一行:
BusinessLayer bl = new BusinessLayer(); 这把安卓 UI 层和业务逻辑层永远绑定在了一起,而且 UI 层将来不可能在没有业务逻辑层的帮助下完成自己的工作。
业务逻辑层也违反了 DIP,因为它依赖于一个数据层的具体实现,如此行:
DataLayer dl = new DataLayer(); 该如何打破这个依赖链条呢?如果高层级模块不能依赖低层级模块的话,这个应用该如何做呢?
我们当然不想要一个简单的完整的类来完成所有的事情。记住,我们还需要符合 SOLID 原则 – 单一职责原则。
谢天谢地我们可以依赖抽象来帮助实现这个应用里面的小间隙。这些间隙就是允许我们实现依赖倒置原则的抽象。把你的应用从一个传统的分层应用改变成一个依赖倒置的架构,仅仅只需要通过一个叫做所有权倒置的过程。
实现所有权倒置
所有权倒置不意味着整个架构都需要反转。我们当然不需要底层软件模块依赖高层软件模块。我们只需要从两端彻底反转关系。
这怎么实现呢?通过抽象。
在 Java 语言里面,有许多方法可以创建抽象,比如抽象类或者接口。我倾向使用接口因为它在应用各层间创建了一个干净的缝隙。一个接口简单地说就是一个契约,它用来通知接口的使用者这个接口实现的所有可能操作。
这使得每一层都依赖一个接口,一个抽象,而不是一个具体的实现 (aka: 一个具体的细节)。
在 Android Studio 里实现起来特别容易。让我们假设你有一个数据层的类,它看起来像这样:
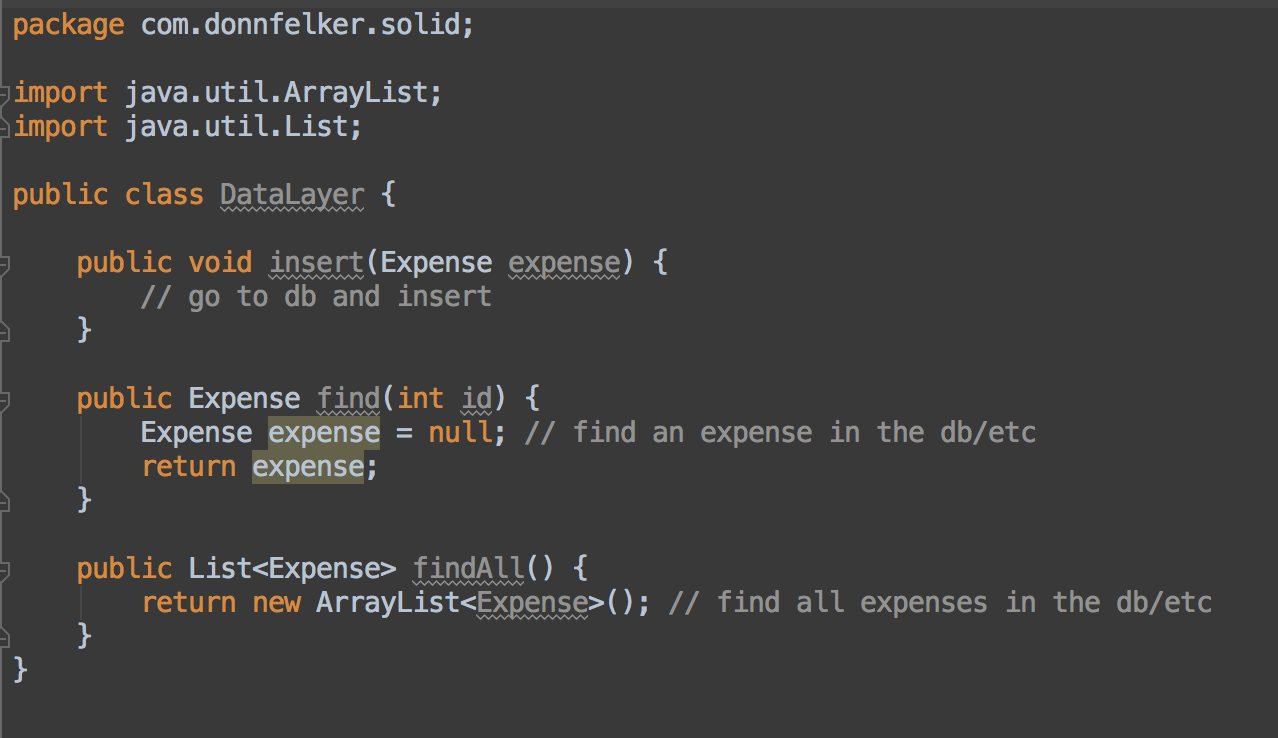

因为我们打算依赖于一个抽象,我们需要从这个类里面抽取出接口。你可以这样做:
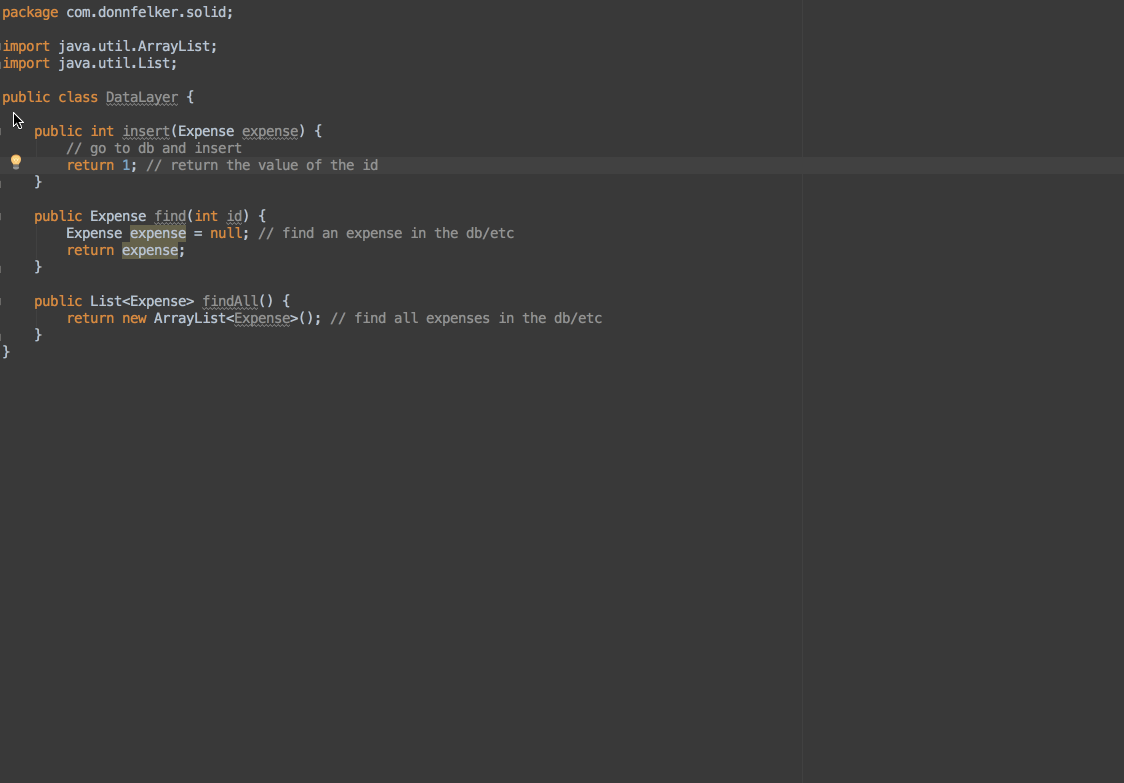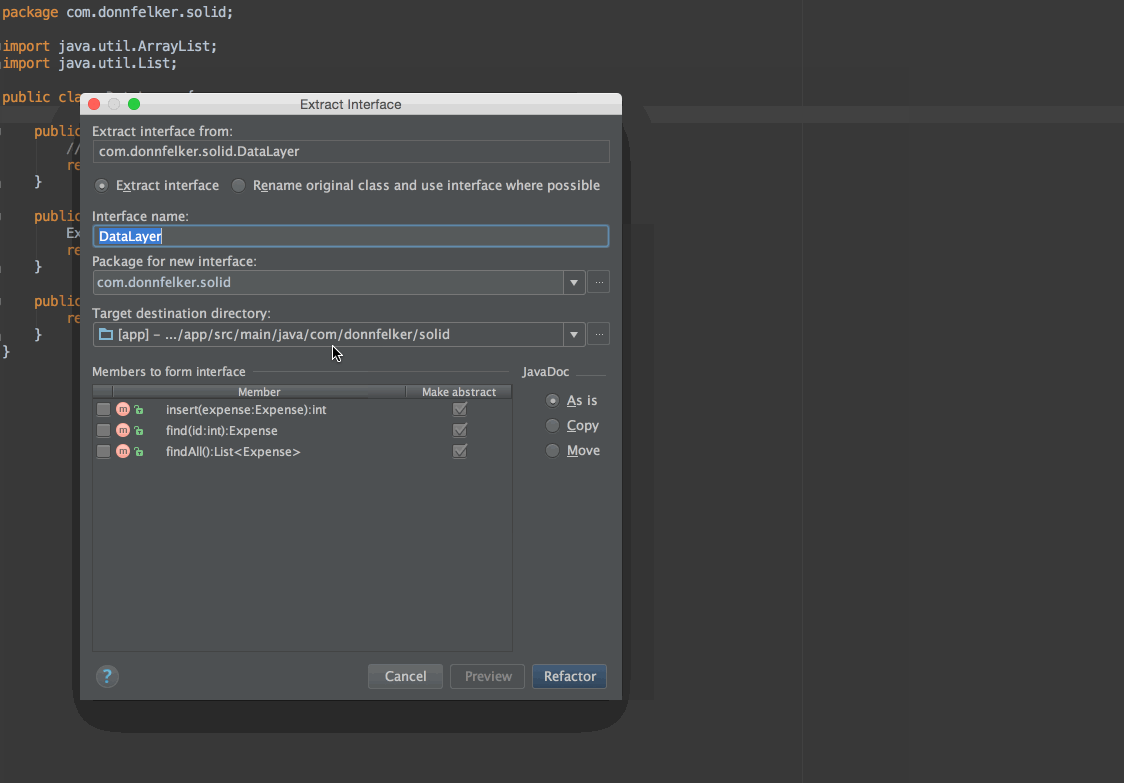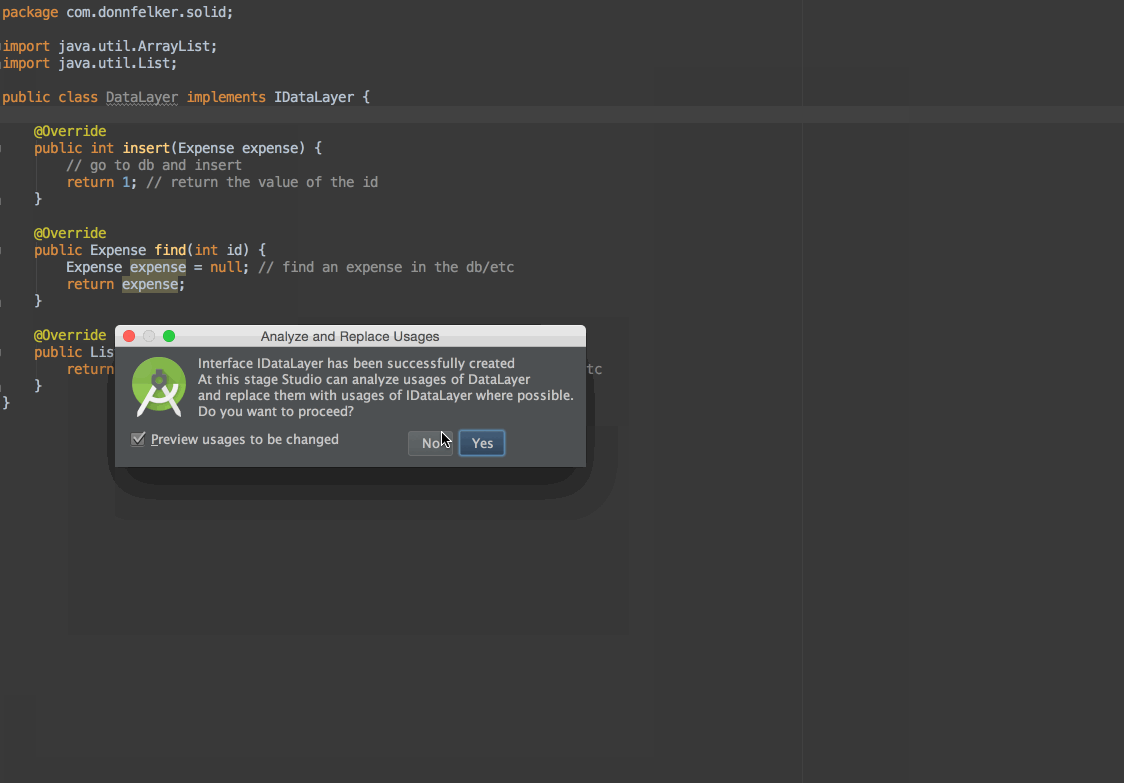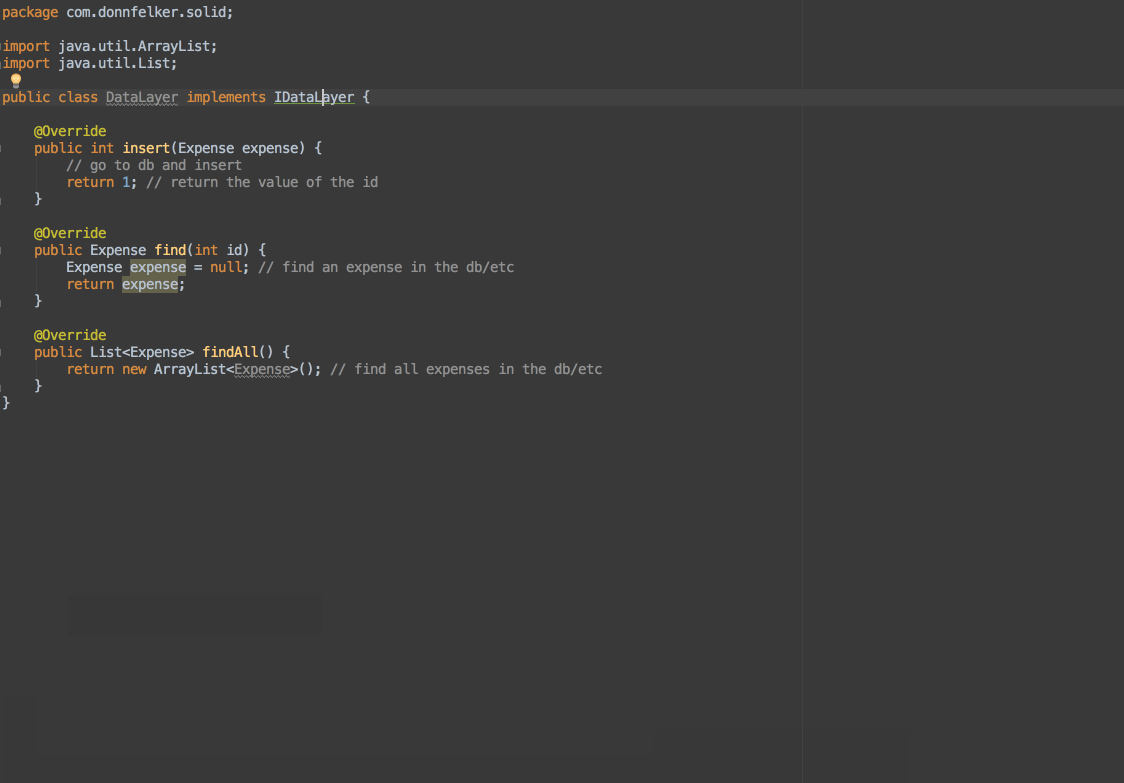
现在你有一个你能够依赖的接口了!然而,它还是需要被调用到,因为业务层仍然需要依赖于数据层。回到业务层,你可以改变你的代码,通过构造函数增加依赖注入,像这样:
public class BusinessLayer {
private IDataLayer dataLayer; public BusinessLayer(IDataLayer dataLayer) {
this.dataLayer = dataLayer; } // in the business layer, return an ID of the expense public int saveExpense(Expense expense) {
// ... some code to check for validity ... then save // ... do some other logic, like check for duplicates/etc return dataLayer.insert(expense); } } 业务逻辑层现在依赖于一个抽象了 – IDataLayer 接口。数据层现在通过构造函数被注入了,这被称作 “构造注入”。
用大白话说就是:”为了创建一个业务层的对象,它创建了一个实现 IDataLayer 的接口。它不关心谁实现了这个接口,它只需要一个实现这个接口的对象就可以了。”
那么,数据层从哪里来呢?好吧,它来自创建业务层对象的地方。在这个例子里面,它是安卓 UI。然而,我们知道前一个例子说明了安卓 UI 和业务逻辑因为创建了一个业务逻辑对象而强耦合在一起了。我们需要业务逻辑层也变成一个抽象。
在这个时候,我会再来一次同样的重构–>抽取–>抽取接口,正如我在之前的例子里面做的一样。这会创建一个 IBusinessLayer 接口,我的安卓 UI 会像这样依赖它:
// This could be a fragment too ... public class MainActivity extends AppCompatActivity {
IBusinessLayer businessLayer; @Override protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); } } 最后,我们高层级的模块都依赖于抽象了(接口)。更进一步,我们的抽象不依赖于细节,它们也依赖于抽象。
记住,UI 层是依赖于业务逻辑层的接口的,业务逻辑层的接口依赖于数据层的接口。抽象无处不在!
在安卓里把它们连在一起
其中存在困难。在应用或者屏幕上总是有进入点。在安卓里,典型的就是 Activity 或者 Fragment 类 (应用对象在这里不是一个有效的对象,因为我们可能只希望我们的对象在某个屏幕会话中激活)。你可能想知道 – 如果安卓 UI 层是最上层的时候,我是如何依赖于抽象的呢?
好吧,有许多方法可以在安卓里解决这个问题,比如采用创建性模式诸如 工厂模式 或者 工厂方法模式,或者依赖注入框架。
我个人建议采用依赖注入框架来帮助你构建这些对象,这样你就不需要手工创建它们。这使得你能写出看起来像这样的代码:
public class MainActivity extends AppCompatActivity {
@Inject IBusinessLayer businessLayer; @Override protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); // businessLayer is null at this point, can't use it. getInjector().inject(this); // this does the injection // businessLayer field is now injected valid and NOT NULL, we can use it // do something with the business layer ... businessLayer.foo() } } 我个人推荐使用 Dagger 作为你的依赖注入的框架。有许多的教程和视频课程来教你配置 dagger,这样你就可以在你的应用里面实现依赖注入了。
如果你不想用创建性模式或者依赖注入,你的代码会看起来像这样:
public class MainActivity extends AppCompatActivity {
IBusinessLayer businessLayer; @Override protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); businessLayer = new BusinessLayer(new DataLayer()); businessLayer.foo() } } 这现在看起来还不是太坏,但是你最终会发现你的对象图会增长到特别大,而且这样实例化对象也是十分容易出错的,它还破坏了 SOLID 原则。还有,它使得你的应用更加脆弱,因为在你的应用里,代码修改无处不在。不使用创建性模式或者注入依赖框架,你的安卓 UI 最终也不会遵循 DIP。
隔离接口的模式
有两个模式可以隔离接口。你喜欢用哪个就用哪个。
- 保持接口在实现它们的类的附近。
- 把接口移到它们自己的包中。
保持接口在实现它们的类附近的好处是十分简洁。这不复杂,也容易理解。这也有一个缺点,当你想给你的接口和实现写些高级的工具或者你需要共享这些接口时,就不太方便了。
第二个方法是把所有你的接口抽象都移到它们自己的包中,然后你的实现引用这个包来获取接口的访问权限。这样做的好处是更灵活了,但是坏处就是有另外一个包需要维护而且很可能是另一个 java 模块(如果你到目前为止已经采用它了)。这也会增加复杂性。然而,有时这是必须的,这取决于你的应用环境 (和它的其他相关依赖) 是如何构建的。
结论
依赖倒置原则是我写的每一个独立应用里都非常倚重的首要原则。我开发的每一个应用最后都使用了依赖注入框架,比如 Dagger,来帮助创建和管理对象生命周期。依赖抽象使得我创建的应用代码是解耦的,容易测试的,更好维护的,这样工作起来也很愉悦(最后这个也是最关键的)。
我高度推荐 (我以我生命的每一盎司保证) 你可以花些时间学习诸如 Dagger 的工具,然后应用到你的应用程序中去。一旦你完全理解了像 Dagger 这样的工具能为你做的事情 (或者仅仅是创建性模式),你真的可以掌握依赖倒置原则的力量。
一旦你跨越依赖注入和依赖倒置的鸿沟,你都无法想象没有它们的日子该如何度过。
原文连接:https://academy.realm.io/cn/posts/donn-felker-solid-part-5/
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/225020.html原文链接:https://javaforall.net


