
Fisher判别分析
Fisher判别分析和PCA差别
刚学完感觉两个很类似,实际上两个方法是从不同的角度来降维。
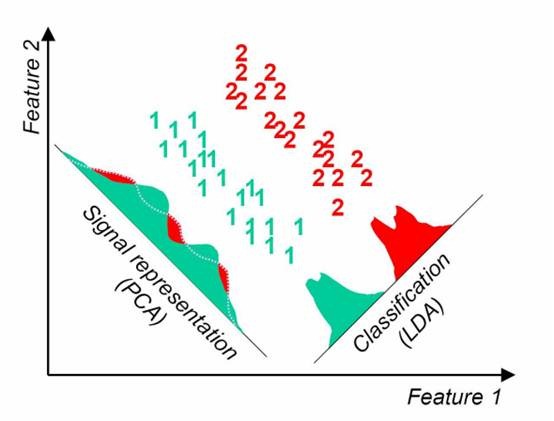

PCA是找到方差尽可能大的维度,使得信息尽可能都保存,不考虑样本的可分离性,不具备预测功能。
LAD(线性判别分析) 是找到一个低维的空间,投影后,使得可分离性最佳,投影后可进行判别以及对新的样本进行预测。
Fisher判别详解
记 μ i \mu_i μi为第i类样本质心, N i N_i Ni为第i类的数量 μ i = 1 N i ∑ x ∈ X i x \mu_i=\frac{1}{N_i}\sum_{x\in X_i} x μi=Ni1∑x∈Xix
- 最大的类间距离
即要投影后两个样本的质心离得越远越好,那么就能得到
J 0 = ( W T μ 1 − W T μ 0 ) 2 = ( W T ( μ 1 − μ 0 ) ) 2 = ( W T ( μ 1 − μ 0 ) ) ( W T ( μ 1 − μ 0 ) ) T = W T ( μ 1 − μ 0 ) ( μ 1 − μ 0 ) T W J_0=(W^T\mu_1-W^T\mu0)^2=(W^T(\mu_1-\mu0))^2=(W^T(\mu_1-\mu0))(W^T(\mu_1-\mu0))^T=W^T(\mu_1-\mu0)(\mu_1-\mu0)^TW J0=(WTμ1−WTμ0)2=(WT(μ1−μ0))2=(WT(μ1−μ0))(WT(μ1−μ0))T=WT(μ1−μ0)(μ1−μ0)TW
S 0 = ( μ 1 − μ 0 ) ( μ 1 − μ 0 ) T S_0=(\mu_1-\mu0)(\mu_1-\mu0)^T S0=(μ1−μ0)(μ1−μ0)T ,那么 J 0 = W T S 0 W J_0=W^TS_0W J0=WTS0W - 最小的类内距离
即要使得投影后同一类的样本点尽可能聚拢在一起,离质心越近越好。
J 1 = ∑ x ∈ X i ( W T x − W T u i ) 2 = ∑ x ∈ X i ( W T ( x − u i ) ) ( W T ( x − u i ) ) T = ∑ x ∈ X i W T ( x − u i ) ( x − u i ) T W J1=\sum_{x\in X_i} (W^Tx-W^Tu_i)^2=\sum_{x\in X_i} (W^T(x-u_i))(W^T(x-u_i))^T=\sum_{x\in X_i} W^T(x-u_i)(x-u_i)^TW J1=x∈Xi∑(WTx−WTui)2=x∈Xi∑(WT(x−ui))(WT(x−ui))T=x∈Xi∑WT(x−ui)(x−ui)TW
S 1 = ∑ x ∈ X i ( x − u i ) ( x − u i ) T S_1=\sum_{x\in X_i}(x-u_i)(x-u_i)^T S1=∑x∈Xi(x−ui)(x−ui)T,那么 J 1 = W T S 1 W J1=W^TS_1W J1=WTS1W
那么我们现在要使得 J 0 J0 J0尽可能大, J 1 J_1 J1尽可能小,那么就是最大化 J = J 0 J 1 = W T S 0 W W T S 1 W J=\frac{J_0}{J_1}=\frac{W^TS_0W}{W^TS_1W} J=J1J0=WTS1WWTS0W
分式上下都有W,那么W和 α W \alpha W αW效果是一样的,不妨令 W T S 1 W = 1 W^TS_1W=1 WTS1W=1,那么优化条件变成
J = W T S 0 W , s . t . : W T S 1 W = 1 J=W^TS_0W,s.t. :W^TS_1W=1 J=WTS0W,s.t.:WTS1W=1
用拉格朗日乘子法求解, L ( W , λ ) = W T S 0 W − λ ( W T S 1 W − 1 ) L(W,\lambda)=W^TS_0W-\lambda(W^TS_1W-1) L(W,λ)=WTS0W−λ(WTS1W−1)
d L = ( d w ) T S 0 W + W T S 0 d W − λ ( ( d w ) T S 1 W + W T S 1 d W ) dL=(dw)^TS_0W+W^TS_0dW-\lambda((dw)^TS_1W+W^TS_1dW) dL=(dw)TS0W+WTS0dW−λ((dw)TS1W+WTS1dW)
= W T S 0 T d W + W T S 0 d W − λ ( W T S 1 T d W + W T S 1 d W ) =W^TS_0^TdW+W^TS_0dW-\lambda(W^TS_1^TdW+W^TS_1dW) =WTS0TdW+WTS0dW−λ(WTS1TdW+WTS1dW)
= ( 2 W T S 0 − 2 λ W T S 1 ) d W =(2W^TS_0-2\lambda W^TS_1)dW =(2WTS0−2λWTS1)dW
运算过程是用到矩阵求导, S 0 T = S 0 S_0^T=S_0 S0T=S0。
那么 ∂ L ∂ W = ( 2 W T S 0 − 2 λ W T S 1 ) T = 2 S 0 W − 2 λ S 1 W \frac{\partial L}{\partial W}=(2W^TS_0-2\lambda W^TS_1)^T=2S_0W-2\lambda S_1W ∂W∂L=(2WTS0−2λWTS1)T=2S0W−2λS1W ,导数为0处, S 0 W = λ S 1 W S_0W=\lambda S_1W S0W=λS1W
当 S 1 S_1 S1可逆的时候, λ W = S 1 − 1 S 0 W \lambda W=S_1^{-1}S0W λW=S1−1S0W,那么最优的 W W W即为 S 1 − 1 S 0 S_1^{-1}S_0 S1−1S0的最大的特征向量。
如果要将 X ∈ R n X\in R^n X∈Rn投影到 R d ( d < n ) R^d (d
Rd(d<n)
注意点:
参考博客:
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/226242.html原文链接:https://javaforall.net


