
双向链表操作
在学习了单链表之后,就顺带学习了双链表的操作。
什么是双链表?
双链表顾名思义,就是链表由单向的链变成了双向链。 使用这种数据结构,我们可以不再拘束于单链表的单向创建于遍历等操作,大大减少了在使用中存在的问题。
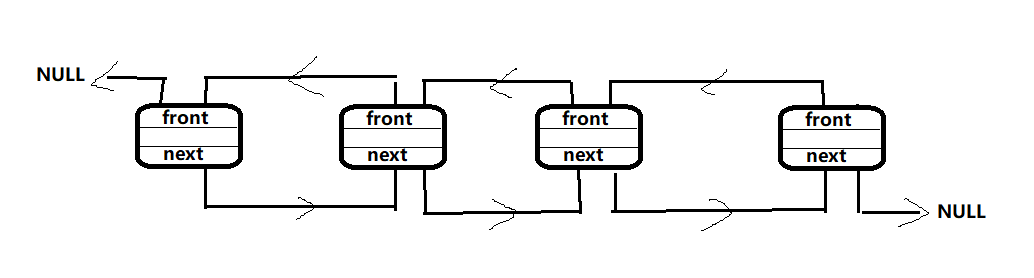

在单链表中,我们有一个数据域,还有一个指针域,数据域用来存储相关数据,而指针域则负责链表之间的“联系”。 而在双向链表中,我们需要有两个指针域,一个负责向后连接,一个负责向前连接。
/* 单链表的结构 */ struct List{
int data; // 数据域 struct List *next; // 指针域 }; /* 双向链表的结构 */ typedef struct List{
int data; // 数据域 struct List *next; // 向后的指针 struct List *front; // 向前的指针 }; typedef struct List* pElem; typedef struct List eElem; 同单链表一样,对双向链表的操作也有创建,插入,遍历,删除,销毁。
双向链表的创建
在创建双向链表的时候,我们需要初始化的有两个指针。同单链表一样,我们需要一个头指针来标志链表的信息。因此我们可以写出该函数的定义:
pElem CreatList(){
pElem head = (pElem)malloc( sizeof(eElem) ); assert( head != NULL ); // 包含于标准库
双向链表的插入
在单向链表的头插法中,最主要的语句自然就是tmp->next = head->next, 而在双向链表中,自然也是一样,只不过多了连接一个向前的指针而已。
void InsertElem( pElem head , int data ){
if( head == NULL ){
printf("The list is empty.\n"); // 头结点为空,则无法插入 return; } pElem tmpHead = head; // 创建一个临时的头结点指针 if( tmpHead->next == NULL ){
/* 当双向链表只有一个头结点时 */ pElem addition = (pElem)malloc( sizeof(eElem) ); assert( addition != NULL ); addition->data = data; // 数据域赋值 addition->next = tmpHead->next; // 后向指针连接 tmpHead->next = addition; addition->front = tmpHead; // 将插入结点的front 指向头结点 } else{
/* 当双向链表不只一个头结点时 */ pElem addition = (pElem)malloc( sizeof(eElem) ); assert( addition != NULL ); addition->data = data; // 数据域赋值 tmpHead->next->front = addition; // 头结点的下一个结点的front 指针 addition->front = tmpHead; // 插入的结点的front 指针指向头结点 addition->next = tmpHead->next; // 插入结点的next 指针指向原本头指针的下一结点 tmpHead->next = addtion; // 将头结点的next 指针指向插入结点 } } 许多人肯定是被最后四条语句弄得一脸懵逼,都一样。但是当你画出图像时,你就会懂得一切。
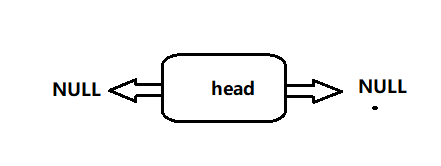
我们创建一个新的结点addition, 此时链表中只有头结点,因此执行if中的程序,执行完毕之后就变成了:
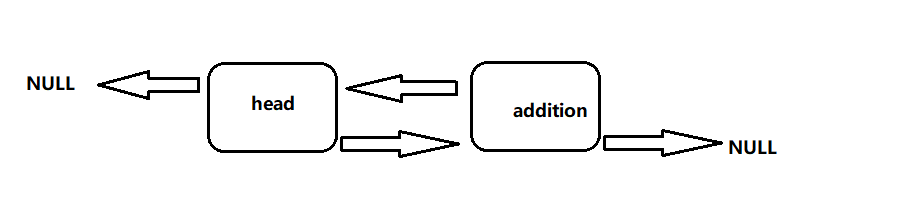
具体步骤有以前的博客《创建单链表的头插法与尾插法详解》。
而当链表中不只有一个头结点时,这时有点意思了。
此时,head的next指针指向addition、front指针指向NULL,addition的next指向NULL、front 指针指向head。
此时,我们要在链表中再插入一个新的结点。 此时,不只要对next 链进行断链,增链,还要对front 链进行同样操作。这样才能完成两条链的连接。
双向链表的遍历
不同于单链表的单向遍历,双向链表提供了操作的便捷性,可前可后的遍历方式简直聊咋咧… 因此在遍历中将实现next 的向后遍历,也会实现front的向前遍历。
void IlluList( pElem head ){
printf("-------------------------------\n"); if( head == NULL ){
printf("The list is empty.\n"); return; } pElem tmpHead = head; while( tmpHead->next != NULL ){
tmpHead = tmpHead->next; // 头结点数据域为空,因此直接从头结点的下一结点开始遍历 printf("%d\n",tmpHead->data); } // 此时tmpHead 的地址在链表的最后一个结点处 while( tmpHead->front->front != NULL ){
printf("%d\n",tmpHead->data); // 最后一个结点要输出 tmpHead = tmpHead->front; } printf("%d\n",tmpHead->data); return; } 当向后遍历完成之后,此时tmpHead的地址是链表的最后一个结点的地址,因此使用front 来进行向前的遍历。 如果判断条件是tmpHead->front != NULL 的话,会将头结点的数据域也输出,然头结点的数据域未使用,因此会输出一个不确定的值。 正因如此将判断条件定为tmpHead->front->front != NULL
删除一个结点
就像这幅图一样,当删除addition结点时,先讲addition的下一个结点与head相连,而下一个结点是NULL , 因此可以得出函数为:
void DeleteElem( pElem head , int data ){
if( head == NULL ){
printf(""The list is empty.\n); return; } pElem tmpHead = head; while( tmpHead->next != NULL ){
tmpHead = tmpHead->next; if( tmpHead->data == data ){
tmpHead->front->next = tmpHead->next; // 将被删结点的上一个结点的next 指针指向 被删结点的下一个结点 tmpHead->next->front = tmpHead->front; // 将被删结点的下一个结点的 front 指针指向 被删结点的上一个结点 break; } } free(tmpHead); // 释放内存 } 销毁链表
销毁一个双向链表的操作同单链表的相似。指针不断向后运动,每运动一个结点,释放上一个结点。
void DestroyList( pElem head ){
pElem tmp; while( head->next != NULL ){
tmp = head; // 指针不断后移 head = head->next; free(tmp); } free(head); } 这样就是双向链表的基本操作
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/226246.html原文链接:https://javaforall.net


