
最近布置了个课堂作业,用python实现决策树算法 。整了几天勉勉强强画出了棵歪脖子树,记录一下。
大体思路:
1.创建决策树My_Decision_Tree类,类函数__init__()初始化参数、fit()进行决策树模型训练、predict()进行预测、evaluate()进行模型评估、save_model()保存模型(csv格式)、load_model()加载模型、show_tree()使用Pillow库绘制决策树以及其他一些封装的功能函数;
2.最佳划分点的度量通常有Gini值、Entropy、Classification error等,本程序采用Gini值,计算方法如下:
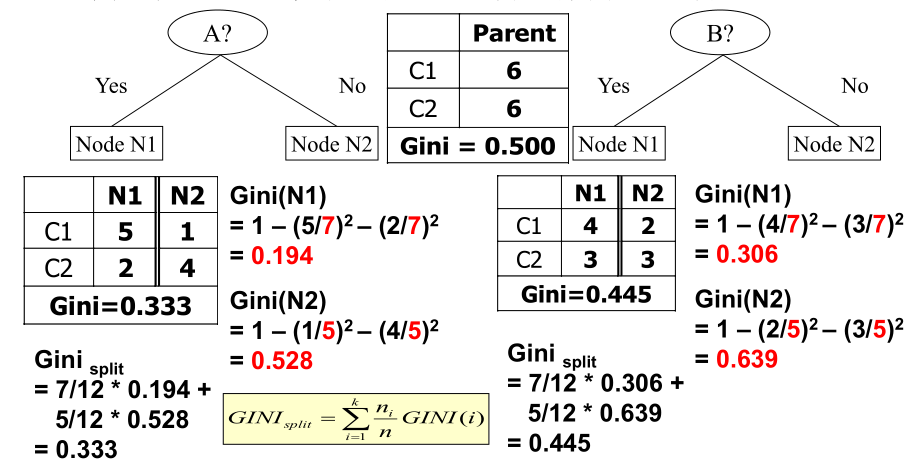

构建决策数模型所用到的功能函数(gini值计算相关)说明:
①get_col_gini(self,threshold_point, value_series, label_series):计算一列数据在某一阈值划分点下的gini_split值;
②get_best_point(self,value_series, label_series):对连续型数据进行大小排序,分别计算切分点及其对应的gini_split值,找到使得gini_split值最小的最佳切分点;
③get_best_column(self,data,label_series):遍历数据表中的属性列,计算每列的最佳划分点和gini_split值,并对比找到最适合划分的一列及其对应的划分点;
3.决策树构建(训练)的逻辑:
①程序开始以root为父节点,先找到6列属性(剩余属性)中最适合划分的列和划分点,并将其划分为两个子节点,记录判断条件和此节点位置。删除子节点中的该列属性以避免最终决策树模型倾向于某个属性,利用剩余的属性继续构造决策树;
②判断各个子节点中的标签是否相同,如果为同一类则移到叶节点中,否则将此节点更新到下个流程中的父节点中;
③一直循环以上过程,当父节点为空时结束训练,如果所有子节点都为叶节点时则决策树完美将数据分类;当然也会出现所有属性都用完但子节点中标签依旧不唯一的情况,这时以该节点中个数较多的标签类作为分类结果,终止模型构建。
# -*- coding: utf-8 -*- # @Version: Python 3.8.2 # @Author: 707 # @Use: 决策树算法编写 import numpy as np import pandas as pd from sklearn.model_selection import train_test_split #数据集划分 #采用Pillow可视化决策树 from PIL import Image from PIL import ImageDraw from PIL import ImageFont 决策树框架 class My_Decision_Tree(object): '''决策树框架''' def __init__(self, arg=None): 初始化类参数 self.arg = arg #存放决策树中的各层判断条件 self.decision_df=pd.DataFrame(columns=['parent_depth','parent_pos','this_depth','this_pos','column','point','label']) self.Parent_node_list=[] #存放父节点和子节点的DataFrame self.Child_node_list=[] self.leaf_list=[] #存放划分好的叶节点 self.branch_list=[] #存放未能划分出来的节点 def fit(self,x_train,y_train): '''传入训练集和标签构造决策树''' ''' 程序逻辑: (1)程序开始以root为父节点,先找到6列属性(剩余属性)中最适合划分的列和划分点,并将其划分为两个子节点, 记录判断条件和此节点位置。删除子节点中的该列属性以避免最终决策树模型倾向于某个属性,利用剩余的属性继续构造决策树 (2)判断各个子节点中的标签是否相同,如果为同一类则移到叶节点中,否则将此节点更新到下个流程中的父节点中 (3)一直循环以上过程,当父节点为空时结束训练,如果所有子节点都为叶节点时则决策树完美将数据分类;当然也会出现所有属性都用完但子节点 中标签依旧不唯一的情况,这时以该节点中个数较多的标签类作为分类结果,终止模型构建。 ''' x_data=x_train.copy() if(y_train.name not in x_data.columns): x_data[y_train.name]=y_train #把第一层(原数据)放入父节点列表Parent_node_list self.Parent_node_list.append(x_data) #写入第一层的决策(跟节点) decision={'this_depth':1,'this_pos':0,'column':'root','label':'#'} self.decision_df=self.decision_df.append(decision,ignore_index=True) #开始循环计算分类节点 parent_count=0 #循环的父节点数 child_pos=0 #子节点的位置 depth=2 #第几层节点 while True: parent_node=self.Parent_node_list[parent_count] #找到第一个适合划分的列和划分点 col_1,point_1=self.get_best_column(parent_node,parent_node[y_train.name]) print('decision condition:',col_1,point_1) #根据条件把父节点划分为两部分 Child_node1=parent_node.loc[parent_node[col_1]<=point_1] Child_node2=parent_node.loc[parent_node[col_1]>point_1] #每一部分的分类结果 result=[] for child_node in [Child_node1,Child_node2]: #删除已使用过的属性 del(child_node[col_1]) #判断子节点标签是否为一类,是则将其放入叶节点列表中 if(len(child_node[y_train.name].unique())==1): self.leaf_list.append(child_node) print('添加一个叶节点,标签类型:',child_node[y_train.name].unique()[0],'数据大小:',child_node.shape) result.append(child_node[y_train.name].unique()[0]) # 判断子节点标签是否还有剩余属性可以作为分类依据,如果有则添加到子节点列表中用于后续分类 elif(child_node.shape[1]!=1): self.Child_node_list.append(child_node) print('添加一个子节点,数据大小:',child_node.shape) result.append('#') #都不满足说明该节点没有分完但是分不下去了,提示错误 else: self.branch_list.append(child_node) print('child_node节点已用完所有属性,仍然没分出来,剩余数据大小:') print(child_node[y_train.name].value_counts()) values=child_node[y_train.name].value_counts() if(len(values)==0): replace=list(parent_node[y_train.name].value_counts().index)[0] else: replace=list(values.index)[0] print('用%s作为该条件下的预测结果' %replace) result.append(replace) #找到该父节点在该层中所对应的位置 p_pos_list=self.decision_df.loc[(self.decision_df['this_depth']==depth-1)&(self.decision_df['label']=='#'),'this_pos'] p_pos_list=list(p_pos_list) # print('p_pos_list:',p_pos_list) #判断完一个父节点之后,把判断条件加入decision_df中 decision1={'parent_depth':depth-1,'parent_pos':p_pos_list[parent_count],'this_depth':depth,'this_pos':child_pos, 'column':col_1,'point':point_1,'label':result[0]} decision2={'parent_depth':depth-1,'parent_pos':p_pos_list[parent_count],'this_depth':depth,'this_pos':child_pos+1, 'column':col_1,'point':point_1,'label':result[1]} self.decision_df=self.decision_df.append([decision1,decision2],ignore_index=True) #当遍历完父节点列表所有值后,将子节点更新为父节点 child_pos+=2 parent_count+=1 if(parent_count==len(self.Parent_node_list)): parent_count=0 child_pos=0 depth+=1 print('该层决策结束,进行下一层决策\n') self.Parent_node_list=self.Child_node_list.copy() self.Child_node_list.clear() print('更新parent_node_list,大小:%d' %len(self.Parent_node_list)) #判断父节点列表中是否还有未分类的节点,如果没有则表示已经全部分好,结束训练 if(len(self.Parent_node_list)==0): print('决策树构建完成') #显示构建好的决策树:判断条件及结果(叶节点) print(self.decision_df) break def predict(self,x_test): '''输入测试数据进行决策判断''' y_predict=list() if(type(x_test)==pd.core.series.Series): pred=self.get_ylabel(x_test) y_predict.append(pred) else: for index,row in x_test.iterrows(): pred=self.get_ylabel(row) y_predict.append(pred) y_predict=np.array(y_predict,dtype=str) return y_predict def evaluate(self,x_test,y_test): '''输入测试集和标签评估决策树准确性,返回acc''' y_true=np.array(y_test,dtype=str) y_pred=self.predict(x_test) # print(y_pred) # print(y_true) label_list=list(self.decision_df['label'].unique()) label_list.remove('#') label_list=np.array(label_list,dtype=str) #类型转换 #创建混淆矩阵(index为true,columns为pred) confusion_matrix=pd.DataFrame(data=0,columns=label_list,index=label_list) for i in range(len(y_true)): confusion_matrix.loc[y_true[i],y_pred[i]]+=1 print('混淆矩阵:') print(confusion_matrix) #计算准确率 acc=0 for i in range(len(label_list)): acc+=confusion_matrix.iloc[i,i] acc/=len(y_true) print('acc:%.5f' %acc) return acc def save_model(self,path): '''以csv格式保存模型''' self.decision_df.to_csv(path,index=False) def load_model(self,path): '''以csv格式读取模型''' self.decision_df=pd.read_csv(path) def get_col_gini(self,threshold_point, value_series, label_series): '''Gini值计算函数''' # 将输入进行重组 df_input = pd.DataFrame() df_input['value'] = value_series df_input['label'] = label_series # print(df_input) # 设计Gini值的计算表格 label_cols = label_series.value_counts() df_gini = pd.DataFrame(columns=['node1', 'node2'], index=label_cols.index) for c in label_cols.index: df_c = df_input.loc[df_input['label'] == c] df_gini.loc[c, 'node1'] = df_c.loc[df_c['value']<= threshold_point].shape[0] df_gini.loc[c, 'node2'] = df_c.loc[df_c['value']> threshold_point].shape[0] #计算node1、node2节点gini值中和的部分 sum_n1=df_gini['node1'].sum() sum_n2=df_gini['node2'].sum() # print(df_gini) # 计算node节点gini值 gini_n1=gini_n2=0 if(sum_n1==0): for c in label_cols.index: gini_n2+=(df_gini.loc[c,'node2']/sum_n2)2 elif(sum_n2==0): for c in label_cols.index: gini_n1+=(df_gini.loc[c,'node1']/sum_n1)2 else: for c in label_cols.index: gini_n1+=(df_gini.loc[c,'node1']/sum_n1)2 gini_n2+=(df_gini.loc[c,'node2']/sum_n2)2 gini_n1 = 1-gini_n1 gini_n2 = 1-gini_n2 #计算gini_split gini_split=sum_n1/(sum_n1+sum_n2)*gini_n1 +sum_n2/(sum_n1+sum_n2)*gini_n2 # print("point:%f,gini_split:%f" %(threshold_point,gini_split)) return gini_split def get_best_point(self,value_series, label_series): '''找到一列属性中最适合划分(gini值最小)的点''' value_array=np.array(value_series) value_array=np.sort(value_array) df_point = pd.DataFrame(columns=['point', 'gini_value']) # 循环属性值列,计算划分点及其gini值并添加至df_point数据表中 for i in range(len(value_array) + 1): if(i == 0): point = value_array[i] - 1 elif(i == len(value_array)): point = value_array[i - 1] else: point = 0.5 * (value_array[i] + value_array[i - 1]) gini = self.get_col_gini(point, value_series, label_series) s = pd.Series(data={'point': point, 'gini_value': gini}) df_point.loc[i] = s df_point.sort_values(by='gini_value', inplace=True) best_point = df_point.iloc[0, 0] best_gini = df_point.iloc[0,1] # print("best point for column '%s':%f" %(value_series.name,best_point)) # print(df_point) return best_point,best_gini def get_best_column(self,data,label_series): '''遍历data中的属性列,计算其最佳划分点及gini值,找出最适合划分的一列和划分点''' x_data=data.copy() if(label_series.name in x_data.columns): del(x_data[label_series.name]) gini_columns=pd.DataFrame(columns=['point','gini'],index=x_data.columns) for col_name in x_data.columns: point,gini=self.get_best_point(x_data[col_name],label_series) s=pd.Series({'point':point,'gini':gini}) gini_columns.loc[col_name]=[point,gini] # gini_columns=gini_columns.append(s,ignore_index=True) #append会更改索引 gini_columns.sort_values(by='gini',inplace=True) # print(gini_columns) best_col=gini_columns.index[0] best_point=gini_columns.iloc[0,0] return best_col,best_point def get_ylabel(self,x_series): '''计算一行x数据(Series)对应的标签''' model=self.decision_df y_pred='#' x_index=1 parent_index=[] child_df=pd.DataFrame() # for i in range(1): while (y_pred=='#'): #判断条件 condition=[model.loc[x_index,'column'],model.loc[x_index,'point']] if(x_series[condition[0]]>condition[1]): x_index+=1 # print('%s>%f' %(condition[0],condition[1])) # else: # print('%s<=%f' %(condition[0],condition[1])) y_pred=model.loc[x_index,'label'] #更新父节点索引并找到其子节点 parent_index=[model.loc[x_index,'this_depth'],model.loc[x_index,'this_pos']] child_df=model.loc[(model['parent_depth']==parent_index[0])&(model['parent_pos']==parent_index[1])] #找到标签时结束 if(child_df.shape[0]!=0): x_index=list(child_df.index)[0] # print('跳到第%d行继续判断' %x_index) # else: # print('预测结束') # print('pred:',y_pred) return y_pred def show_tree(self): '''将决策树进行可视化''' def add_text(im_draw,text_str,xy,multiline=1): '''在绘图对象的某个位置添加文字''' #设置大小 font_h,font_w=25,14 font_h*=multiline text_len=round(len(text_str)/multiline) font=ImageFont.truetype(font='simsun.ttc',size=20) im_draw.text(xy=(xy[0]-font_w*3,xy[1]),text=text_str,font=font,fill='black',align='center') #绘制矩形 # im_draw.rectangle(xy=(xy[0],xy[1],xy[0]+font_w*text_len,xy[1]+font_h),outline='black',width=2) interval_x,interval_y=60,80 model=self.decision_df.copy() model['x_pos']=model['this_pos'] model['y_pos']=(model['this_depth']-1)*interval_y model['text']='text' max_depth=model.iloc[-1,2] #创建图像 img_w,img_h=1500,600 tree_img=Image.new(mode='RGB',size=(img_w,img_h),color='white') draw=ImageDraw.Draw(tree_img) #创建绘图对象 parent_pos=[] parent_x_pos=0 x_pos=0 for x_index in model.index: text=model.loc[x_index,'column'] if (str(model.loc[x_index,'point']) == 'nan'): x_pos=img_w/4 else: #跟新text内容和x位置 model.loc[x_index,'x_pos']=x_pos parent_pos=[model.loc[x_index,'parent_depth'],model.loc[x_index,'parent_pos']] parent_x_pos=model.loc[(model['this_depth']==parent_pos[0])&(model['this_pos']==parent_pos[1]),'x_pos'] depth=model.loc[x_index,'this_depth']-1 if(model.loc[x_index,'this_pos']%2==0): text+='\n<='+('%.3f' %model.loc[x_index,'point']) x_pos=parent_x_pos-interval_x*np.sqrt(max_depth-depth) else: text+='\n>'+('%.3f' %model.loc[x_index,'point']) x_pos=parent_x_pos+interval_x*np.sqrt(max_depth-depth) x_pos=x_pos.iloc[0] if(model.loc[x_index,'label'] !='#'): text+='\nClass:'+str(model.loc[x_index,'label']) #将文字和位置添加到 model.loc[x_index,'text']=text model.loc[x_index,'x_pos']=x_pos # 调整节点横坐标位置 gap=140 for depth in model['this_depth'].unique(): if(depth!=1): same_depth=model.loc[model['this_depth']==depth] for x_index in same_depth.index[:-1]: if(x_index==same_depth.index[0]): if((model.loc[same_depth.index[0],'x_pos']-model.loc[same_depth.index[-1],'x_pos'])
结果:
用我的数据跑了一下,成功长出一棵歪脖子树,nice!
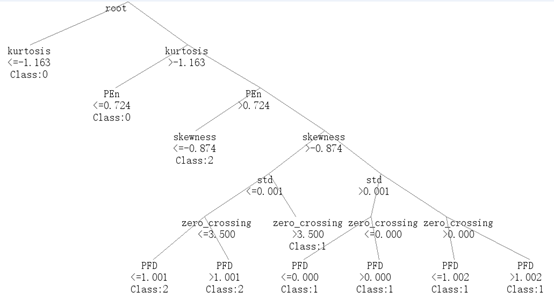
代码能力有限,有错误的地方欢迎大佬们交流,批评指正[狗头抱拳]
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/226389.html原文链接:https://javaforall.net


