
本文从问题定义入手,再到近几年的工作,最后进行横向对比,并提供一些个人向的future work,以供参考。
文章目录
先验知识
这部分介绍一下聚类、图、图神经网络。都掌握的不错的同学可以直接跳过。
聚类
就聚类而言其定义是十分简单的:
聚类(Clustering) 是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。——知乎
在这里我们来提出一些问题:
- 如何衡量相似性的大小;
- 如何进行划分;
- 如何确定簇类。
关于第一个问题,在西瓜书机器学习里面有详细介绍,即相似性度量,如欧式距离、闵可夫斯基距离、马氏距离、余弦相似度、皮尔逊相关系数和KL散度等。
KL散度不能称之为距离(需满足非负性、同一性、对称性、直递性),因为其不满足交换性,不过有一个替代版本可用即JS距离
第二个问题也很简单,也就是K-means、谱聚类这些方法,当然近年也有关于深度嵌入聚类(Deep Embedding Clustering,DEC)的相关研究成果,来将深度学习引入特征聚类领域。下面提供简单的介绍:
- K-means:迭代求解的聚类分析算法。预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心,多次迭代直到收敛或者达到迭代次数上限。 聚类中心以及分配给它们的对象就代表一个聚类。
- 谱聚类:从图论中演化出来的算法。把所有的数据看做空间中的点,这些点之间可以用边连接起来。距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的。
- 深度嵌入聚类(DEC):一种引入KL loss来迭代优化非监督算法,详见论文。
Xie, Junyuan, Ross Girshick, and Ali Farhadi. “Unsupervised deep embedding for clustering analysis.” International conference on machine learning. PMLR, 2016.
第三点是大家接触较少的点。就仿佛题目总是让你去将这堆数据分为3类、分为5类,但是却不知道为何是3类5类。其实也是有一些方法的,如肘部法则SSE、轮廓系数等。
知乎:https://zhuanlan.zhihu.com/p/
这里再列一下我在论文中看到的一个方法,度量可概化性G:
- 将数据分为训练和验证集,并将G设为两者损失值之间的比率,对各种簇类别数k下计算G
- 当k大于最佳簇数时会出现G急剧下降的现象
图
- 结构化信息(欧式数据)
- 语音、文本、图像、视频 ……
- 具有规范的数据存储或表示形式
- 迎合人类的认知和计算机的存取处理
- 非结构信息(非欧式数据)
- 社交网络、化学分子、引文网络 ……
- 没有规范的数据格式
- 来自于自然世界
非结构数据往往可以使用关系进行表示,即被视为关系数据。而关系数据的主流数据结构就是图结构。看到这有的人会说了,图不就是节点和边嘛,有啥可讲的。
其实不然,大家传统认知的图只是普通图,但是研究可并不会受限于普通图。这里我们给出一些研究前沿比较热衷的图的种类,以供大家细化自己的工作方向。
- 普通图:由节点和边组成,且每条边只能两个节点。且节点之间、边之间不做区分。
- 二部图:将节点分为两类,所有的边只会连接不同类的节点;
- 超图:由节点和超边组成,每条超边可以连接不限数量的节点;
- 异质图:节点之间、边之间可以具有不同的语义。
在实际应用的时候,这些图都会有不同的效果,其实最核心的地方在于,如何定义节点和边,也就是如何解释节点和边成为你的方法是否work的重点。
图神经网络
关于GNN的知识还是建议大家从博客或者一些survey入手。下面提供一些不错的survey文章,其中第一篇非常值得一看。
图节点聚类
看到这相信大家应该能猜测到图节点聚类到底是怎么一回事了。图节点聚类也就是针对具有图结构的节点集做聚类研究。
其实图节点聚类也有不少的细化。这里我们根据节点是否提供特征可以分为:
- 属性图节点聚类:结构特征+节点特征
- 结构图节点聚类:仅结构特征
这里1是兼容2的,不过2也有一些专门的独立工作,如对比学习模型GCC(2020[KDD] GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training),感兴趣的可以参考。
我们核心讨论对象是更加具有普适性的属性图聚类。
- 输入:结构特征、节点特征(邻接矩阵等)
- 输出:节点标签集
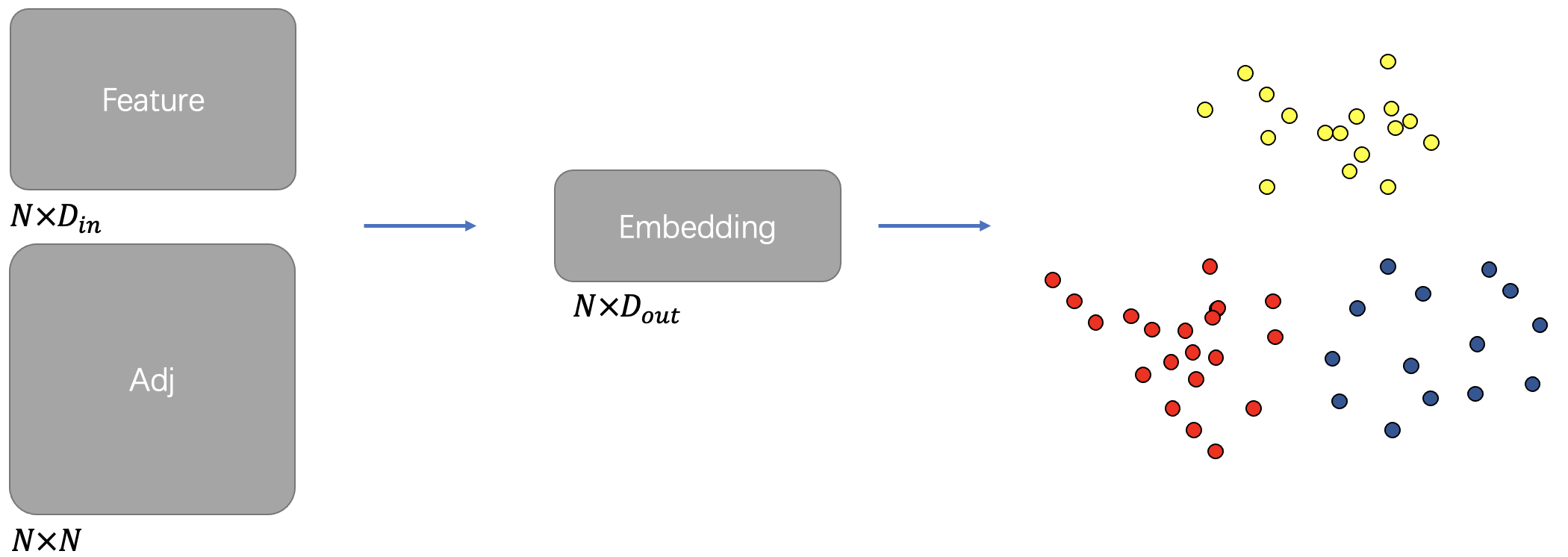

其研究本质就是如何更好的融合结构特征和节点特征,以完成特征的高效融合来完成聚类标签的生成。
相关工作
图聚类(Graph Clustering)
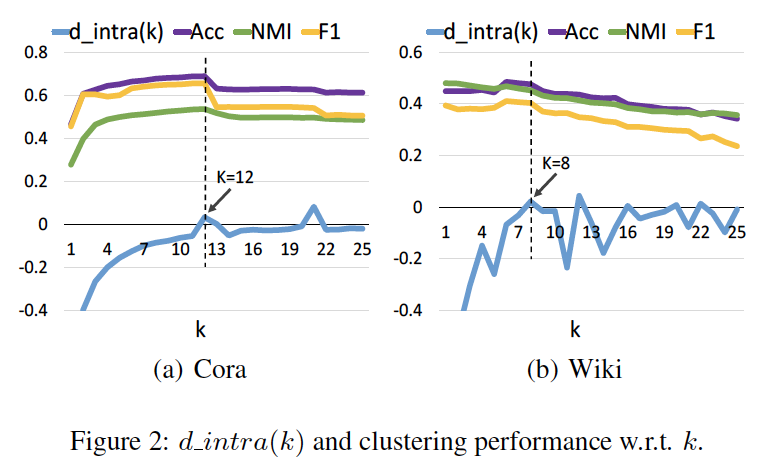
Attributed Graph Clustering via Adaptive Graph Convolution [2019IJCAI]
- 通过特征分解图拉普拉斯算子,得到的特征值分布图「0~2」分析,设计Frequency response函数应该很好的将其包含进来即可。即设计了 p ( λ p ) = 1 − 1 / 2 × λ q p(\lambda_p)=1-1/2\times\lambda_q p(λp)=1−1/2×λq的频率响应函数,来将所有的特征包括起来,进行无损/低损特征融合。
- 以类内平均距离作为衡量卷积次数的方法,以达到自适应融合的效果。类内平均距离的局部最小值可以和最佳聚类效果基本对应如下图所示。
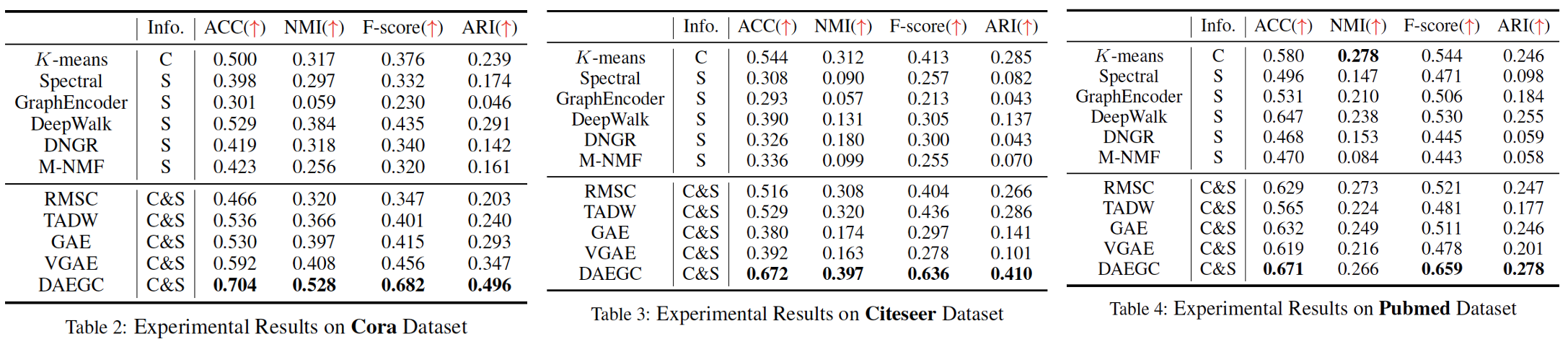
Attributed Graph Clustering: A Deep Attentional Embedding Approach [2019IJCAI]

其本质由图注意力自动编码器组成,进而通过KL loss来优化嵌入表示,最终达到优化聚类的效果。其算法流程如下:

下面是实验效果:
Structural Deep Clustering Network [2020WWW]
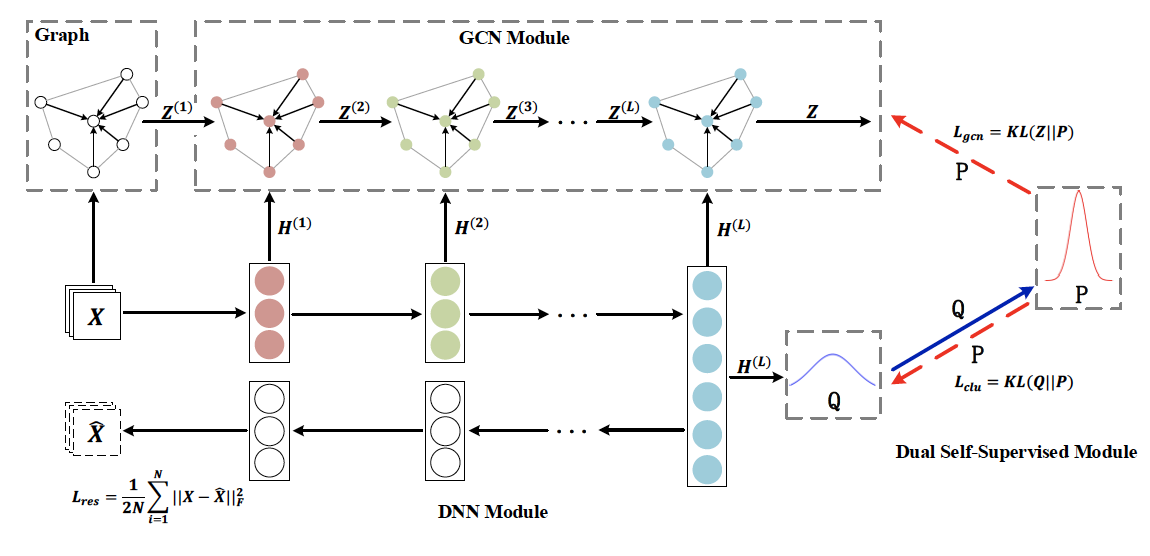
SDCN本质由两部分组成:
- (下)自动编码器Auto-Encoder
- (上)图卷积神经网络
其中Auto-Encoder是无监督自学习的,其目的是学习到节点特征的低维嵌入表示。而GCN模块是将图和图结构进行充分融合,而其监督信息来自于低维嵌入和GCN出来的融合特征之间的KL loss:
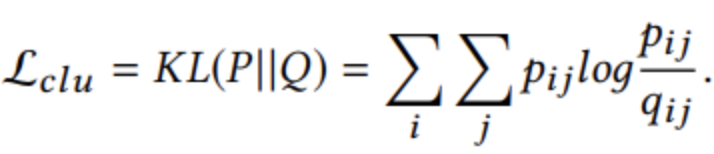
通过最小化 Q Q Q和P PP分布之间的KL散度损失,目标分布 P P P可以帮助Auto-Encoder模块学习更好的聚类任务表示,即使数据表示围绕聚类中心更近。 这是一种自我监督机制,因为目标分布 P P P由分布 Q Q Q计算,并且P PP分布监督依次更新分布 Q Q Q。这部分可以参考原文,或者参考DEC的论文进行进一步学习(Unsupervised deep embedding for clustering analysis【2016ICML】)。
其本质:图卷积神经网络GCN+自动编码器AE+深度嵌入聚类DEC
图嵌入(Graph Embedding)
图嵌入领域目的在于给图中节点学习到融合自身特征和图结构信息的低维特征表示,这与聚类的目的基本相仿。图嵌入领域也有很多工作在聚类方面也有很好的效果。
Adaptive Graph Encoder for Attributed Graph Embedding(AGE)

本文先针对GAE模型(如上图)提出三个缺点:
- 图卷积滤波器与权矩阵的融合学习会影响性能和鲁棒性;
- 图卷积滤波器是广义拉普拉斯平滑滤波器的特殊情况,但它们并不保留最优低通特性;
- 现有算法的训练目标通常是通过AutoEncoder框架恢复邻接矩阵或特征矩阵,这与实际所需并不总是一致的。
第一,针对经典的图卷积滤波器进行改造。通过针对真实图结构进行特征分解,发现基本特征值处于0~1.5之间。所以为了更好的综合精细度和覆盖率,这里将频率响应函数设置为 p ( λ p ) = 1 − 2 / 3 × λ q p(\lambda_p)=1-2/3\times\lambda_q p(λp)=1−2/3×λq(是不是和上面的AGC)有一丝丝的相像。然后通过多层的滤波学习到最好的融合特征。
尽管作者提出了很多有意思的思路和创新点,但是笔者认为该模型存在着很大的一个缺陷:超参数太多,实践成本高,比如融合特征需要进行滤波的阶次、第二步中正负样本对比例的选择。且文中没有给出具体的参数选择方案,同时各个数据所用的参数没有什么规律性。
链路预测效果:

图对比学习(Graph Contrastive Learning)
图对比学习是近期最热的topic之一了,也可以用来做聚类任务,并且取得了不错的效果。关于这个建议阅读我的另一篇博文,来更加细致的了解:
图对比学习入门
Future Work
- 大规模聚类算法:大数据时代的聚类落地的数据量规模肯定是很大的,一个高效的聚类算法肯定能够很好的得到关注。
- 通用的关系数据聚类算法:上面提到各种图结构都可以用来建模关系数据,是否有大一统的方法可以很好的将他们整合起来。
- 非普通图的对比学习:图、对比学习已经大热,图加对比学习各大实验室也开始研究了。但是非普通图的对比学习任务还是很前瞻具有研究价值的。
论文集
这里分享一下我收集的论文集吧,希望有所帮助。入门级科研无非是大量输入+持续思考+定期产出。
图神经网络GNN
基础
应用
方法
图嵌入
图对比学习
图聚类
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/226685.html原文链接:https://javaforall.net


