
文章目录
Rasa
Rasa是一个开源机器学习框架,用于构建上下文AI助手和聊天机器人。
Rasa有两个主要模块:
Rasa NLU:用于理解用户消息,包括意图识别和实体识别,它会把用户的输入转换为结构化的数据。Rasa Core:是一个对话管理平台,用于举行对话和决定下一步做什么。
Rasa X是一个工具,可帮助您构建、改进和部署由Rasa框架提供支持的AI Assistants。 Rasa X包括用户界面和REST API。

Rasa官方文档: Build contextual chatbots and AI assistants with Rasa
github地址:RasaHQ/rasa
pip安装
pip install rasa_nlu pip install rasa_core[tensorflow] 术语
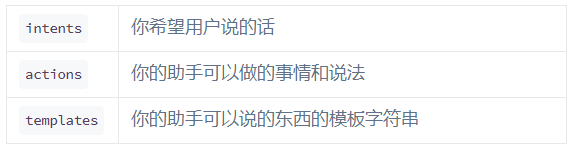
intents:意图pipeline:story:Core model 以训练“stories”的形式从真实的会话数据中学习。故事是用户和助手之间的真实对话.domain:定义了助手所处的universe:它应该获得的用户输入,应该能够预测的操作,如何响应以及要存储的信息
Rasa_NLU
Rasa NLU曾经是一个独立的库,但它现在是Rasa框架的一部分。
Rasa_NLU是一个开源的、可本地部署并配套有语料标注工具RASA NLU Trainer。其本身可支持任何语言,中文因其特殊性需要加入特定的tokenizer作为整个流程的一部分。
Rasa NLU 用于聊天机器人中的意图识别和实体提取。例如,下面句子:
"I am looking for a Mexican restaurant in the center of town"
返回结构化数据:
{
"intent": "search_restaurant", "entities": {
"cuisine" : "Mexican", "location" : "center" } } Rasa_NLU_Chi 作为 Rasa_NLU 的一个 fork 版本,加入了jieba 作为中文的 tokenizer,实现了中文支持。
该部分简单介绍基于 Rasa_NLU_Chi 构建一个本地部署的特定领域的中文 NLU 系统的过程。
目标
- 输入: 中文测试文本
- 输出: 结构化的数据,识别出文本中对应的意图和实体
1. Pipeline
rasa nlu 支持不同的 Pipeline,其后端实现可支持spaCy、MITIE、MITIE + sklearn 以及 tensorflow,其中 spaCy 是官方推荐的,另外值得注意的是从 0.12 版本后,MITIE 就被列入 Deprecated 了。
本例使用的 pipeline 为 MITIE+Jieba+sklearn, rasa nlu 的配置文件为 config_jieba_mitie_sklearn.yml如下:
language: "zh" pipeline: - name: "nlp_mitie" model: "data/total_word_feature_extractor_zh.dat" // 加载 mitie 模型 - name: "tokenizer_jieba" // 使用 jieba 进行分词 - name: "ner_mitie" // mitie 的命名实体识别 - name: "ner_synonyms" - name: "intent_entity_featurizer_regex" - name: "intent_featurizer_mitie" // 特征提取 - name: "intent_classifier_sklearn" // sklearn 的意图分类模型 2. 准备工作:训练MITIE模型文件
由于在pipeline中使用了MITIE,所以需要一个训练好的MITIE模型(先进行中文分词)。MITIE模型是非监督训练得到的,类似于word2vec中的word embedding,需要大量中文语料,训练该模型对内存要求较高,并且非常耗时,直接使用网友分享的中文的维基百科和百度百科语料生成的模型文件。
链接:https://pan.baidu.com/s/1kNENvlHLYWZIddmtWJ7Pdg 密码:p4vx
3. rasa_nlu 语料
那标注好的数据是什么样的呢?
标注好的语料存储在json文件中,具体格式如下所示,包含text, intent,entities,实体中start和end是实体对应在text中的起止index。
以data/examples/rasa/demo-rasa_zh.json为例:
{ "rasa_nlu_data": { "common_examples": [ { "text": "你好", "intent": "greet", "entities": [] }, { "text": "我想找地方吃饭", "intent": "restaurant_search", "entities": [] }, { "text": "我想吃火锅啊", "intent": "restaurant_search", "entities": [ { "start": 2, "end": 5, "value": "火锅", "entity": "food" } ] } ] } } 4. 训练模型
到目前,已经获取了训练所需的标注好的语料,以及词向量模型MITIE文件。接下来就可以训练Rasa_NLU模型了。
插一句 安装:
- 源码安装
$ git clone https://github.com/crownpku/Rasa_NLU_Chi.git // clone 源码 $ cd Rasa_NLU_Chi $ python setup.py install // 安装依赖
模型训练命令
python -m rasa_nlu.train -c sample_configs/config_jieba_mitie_sklearn.yml --data data/examples/rasa/demo-rasa_zh.json --path models --project nlu 所需参数:
- 训练配置文件:
-c - 训练语料:
--data - 模型保存路径:
--path - 项目名称:
--project
模型训练完成后,会在--path指定的路径下保存训练好的模型文件,如果训练时指定了模型名称(即–project),模型就会存储在models/project_name/model_目录中,如models/chat_nlu_test/model_-
结构如下:
5. 测试验证
- 启动服务
python -m rasa_nlu.server -c sample_configs/config_jieba_mitie_sklearn.yml --path models - 测试服务(打开一个新的终端,使用curl命令获取结果)
curl -XPOST localhost:5000/parse -d '{"q":"明天天气预报", "project":"nlu", "model":"model_-"}'
Rasa Core
Rasa Core是用于构建AI助手的对话引擎,是开源Rasa框架的一部分。
Rasa Core消息处理流程
由前面描述的对话管理模块了解到,它应该是负责协调聊天机器人的各个模块,起到维护人机对话的结构和状态的作用。对话管理模块涉及到的关键技术包括对话行为识别、对话状态识别、对话策略学习以及行为预测、对话奖励等。下面是Rasa Core消息处理流程:
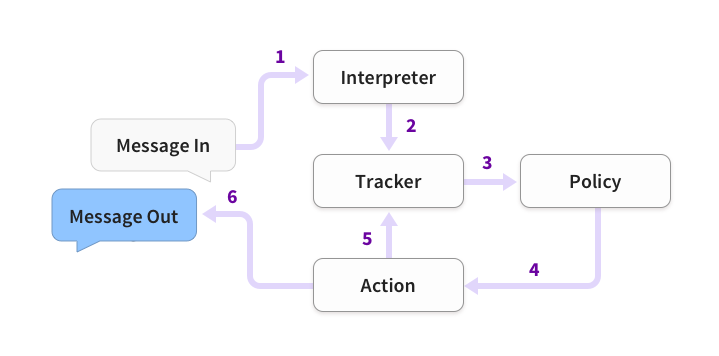
- 首先,将用户输入的Message传递到
Interpreter(NLU模块),该模块负责识别Message中的”意图(intent)“和提取所有”实体”(entity)数据; - 其次,Rasa Core会将Interpreter提取到的意图和识别传给
Tracker对象,该对象的主要作用是跟踪会话状态(conversation state); - 第三,利用
policy记录Tracker对象的当前状态,并选择执行相应的action,其中,这个action是被记录在Track对象中的; - 最后,将执行action返回的结果输出即完成一次人机交互。
Rasa Core包含两个内容: stories和domain。
domain.yml:包括对话系统所适用的领域,包含意图集合,实体集合和相应集合story.md:训练数据集合,原始对话在domain中的映射。
1. Stories
stories可以理解为对话的场景流程,我们需要告诉机器我们的多轮场景是怎样的。Story样本数据就是Rasa Core对话系统要训练的样本,它描述了人机对话过程中可能出现的故事情节,通过对Stories样本和domain的训练得到人机对话系统所需的对话模型。
Stories存储在md文件中。story的符号说明如下:
| 符号 | 说明 |
|---|---|
| sotry标题 | |
| * | 意图和填充的slot |
| – | 动作 |
示例:
simple_story_with_multiple_turns * affirm OR thank_you - utter_default * goodbye - utter_goodbye > check_goodbye story_0 * greet - utter_ask_howcanhelp * inform{
"location": "london", "people": "two", "price": "moderate"} - utter_on_it - utter_ask_cuisine * inform{
"cuisine": "spanish"} - utter_ask_moreupdates * inform{
"cuisine": "british"} - utter_ask_moreupdates * deny - utter_ack_dosearch - action_search_restaurants - action_suggest * affirm - utter_ack_makereservation * thankyou - utter_goodbye 如上所示,几个需要注意的点:
> check_*: 用于模块化和简化训练数据,即story复用。OR:用于处理同一个story中可能出现2个以上意图,这有利于简化story,但是相应的训练时间等于训练了两个以上的故事,不建议密集使用。
可视化stories
Rasa Core中提供了rasa_core.visualize模块可视化故事,有利于掌握设计故事流程。
命令:
python -m rasa_core.visualize -d domain.yml -s data/sotries.md -o graph.html -c config.yml
参数:
-m:指定运行模块-d:指定domain.yml文件路径-s:指定story路径-o:指定输出文件名-c:指定Policy配置文件。
最终,在项目根目录下得到一个graph.html,可用浏览器打开。
具体实现,可参考源代码rasa/core/visualize.py。
from rasa_core.agent import Agent from rasa_core.policies.keras_policy import KerasPolicy from rasa_core.policies.memoization import MemoizationPolicy if __name__ == '__main__': agent = Agent("domain.yml", policies=[MemoizationPolicy(), KerasPolicy()]) agent.visualize("data/stories.md", output_file="graph.html", max_history=2) 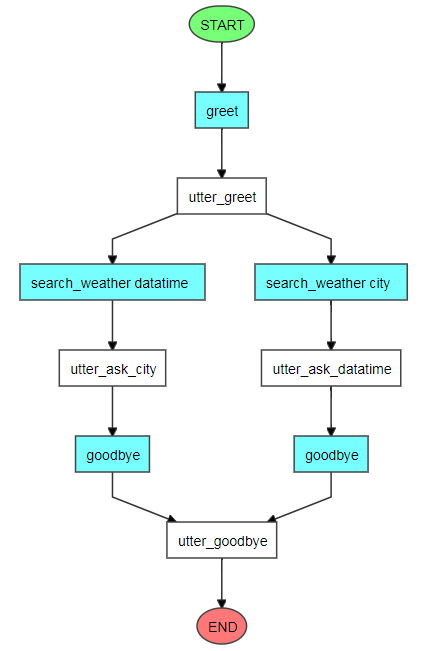
2. Domain
domain.yml定义了对话机器人应知道的所有信息,相当于大脑框架,指定了意图intents, 实体entities, 插槽slots以及动作actions。
其种,intents和entities与Rasa NLU模型训练样本中标记的一致。slot与标记的entities一致,actions为对话机器人对应用户的请求作出的动作。
此外,domain.yml中的templates部分针对utter_类型action定义了模板消息,便于对话机器人对相关动作自动回复。
| 项 | 说明 |
|---|---|
intents |
意图 |
entities |
实体信息 |
slots |
词槽,对话中想要跟踪的信息 |
actions |
机器人作出的动作 |
templates |
回复的模板语句 |
意图intents
使用-符号表示每个意图
intents: - greet - goodbye - search_weather 实体entities
实体,即样本中标出的所有entity
entities: - city 槽slot
slots: city: type: text initial_value:"北京" datatime: type:text initial_value:"明天" matches: type:unfeaturized initial_value:"none" Slot Types类型:
Text Slot:文本Boolean Slot:布尔值Categorical Slot:接受枚举所列的值slots: risk_level: type: categorical values: - low - medium - highFloat Slot:浮点型slots: temperature: type: float min_value: -100.0 max_value: 100.0Defaults: max_value=1.0, min_value=0.0
设置max_value和min_value后,大于max_value和小于min_value的值被设为max_value和min_value。List Slot:列表型数据,且长度不影响对话Unfeaturized Slot:存储不影响会话流程的数据。
如果值本身很重要,请使用categorical或bool槽。还有float和list slots。如果您只想存储一些数据,但不希望它影响会话流,请使用unfeaturized的插槽。type表示slot存储的数据类型,initial_value为slot初始值,该值可有可无(无意义)。
slots: name: type: text initial_value: "human" matches: type:unfeaturized actions
当Rasa NLU识别到用户输入信息的意图后,Rasa Core对话管理模块会对其作出回应,回应的操作就是action。
Rasa Core支持三种action:
- default actions:默认的一组动作,无需定义,可以直接使用
- action_listen:监听action
- action_restart:重置状态
- action_default_fallback:当Rasa Core得到的置信度低于设置的阈值时,默认执行该动作。
- utter actions:以
utter_为开头,只发送一条信息给用户作为反馈的动作。
定义很简单,只需在domain.yml文件中的actions:字段定义以utter_为开头即可。具体的回复内容将被定义在templates部分。如果没有utter_这个前缀,那么action就会被识别为custom actions。actions: - utter_greet - utter_cheer_up - custom actions:自定义动作,允许开发者执行任何操作并反馈给用户,是action多轮的关键点。需要在
domain.yml文件中的actions部分先定义,然后在指定的webserver中实现它。其中,webserver的url地址在endpoint.yml文件中指定。
官方提供了一个小的python sdk来方便用户编写自定义的action,首先需要安装一下对应的rasa_core_sdk。后续再讲。。actions: - action_search_weather
templates
此次定义了utter actions具体的回复内容,且每个utter actions下可以定义多条回复信息。当用户发起一个意图,比如”你好!”,就触发utter_greet操作,Rasa Core会从该action的模板中自动选择其中的一条信息作为结果反馈给用户。
templates: utter_greet: - text: "您好!请问我可以帮到您吗?" - text: "您好!请说出您要查询的具体业务,比如跟我说'查询身份证号码'" - text: "您好!" utter_default是Rasa Core默认的action_default_fallback,当Rasa NLU识别该意图时,它的置信度低于设定的阈值时,就会默认执行utter_default中的模板。
除了回复简单的Text Message,Rasa Core还支持在Text Message后添加按钮和图片,以及访问插槽中的值(如果该插槽的值有被填充的话,否则返回None)。举个栗子:
utter_introduce_self: - text: "您好!我是您的AI机器人呀~" image: "https://i.imgur.com/sayhello.jpg" utter_introduce_selfcando: - text: "我能帮你查询天气信息" buttons: - title: "好的" payload: "ok" - title: "不了" payload: "no" utter_ask_city: - text: "请问您要查询{ datetime }哪里的天气?" utter_ask_datetime: - text: "请问您要查询{ city }哪天的天气" 一个示例:
intents: - greet - goodbye - affirm - deny - search_weather slots: city: type: text matches: type: unfeaturized entities: - city actions: - utter_greet - utter_cheer_up - utter_did_that_help - utter_happy - utter_goodbye templates: utter_greet: - text: "Hey! How are you?" utter_cheer_up: - text: "Here is something to cheer you up:" image: "https://i.imgur.com/nGF1K8f.jpg" utter_did_that_help: - text: "Did that help you?" utter_happy: - text: "Great carry on!" utter_goodbye: - text: "Bye" utter_default: - text: "小x还在学习中,请换种说法吧~" - text: "小x正在学习中,等我升级了您再试试吧~" - text: "对不起,主人,您要查询的功能小x还没学会呢~" 3. 训练对话模型
训练命令如下:
python -m rasa_core.train -d domain.yml -s stories.md -o models/chat1 参数解释:
-d或--domain:指domain.yml文件的路径-s或--stories:指定stories.md文件路径。可以将故事请假保存在一个md文件中,也可以分类保存在多个md文件中(存放到一个目录下)-o或--out:指对话模型的输出路径,保存训练好的模型文件-c或--c:指定Policy规范文件
训练所需数据示例:
- domain.yml文件:
intent: - greet - goodbye - search_weather entities: - city actions: - utter_greet - utter_goodbye - utter_ask_city templates: utter_greet: - text: "你好啊" - text: "又见面了" utter_goodbye: - text: "再见" - text: "下次再见啊" utter_ask_city: - text: "请问您要查询哪里的天气?" - stories.md文件:
search weather * greet - utter_greet * search_weather{ "datatime" : "明天"} - utter_ask_city * goodbye - utter_goodbye
训练网络结构:
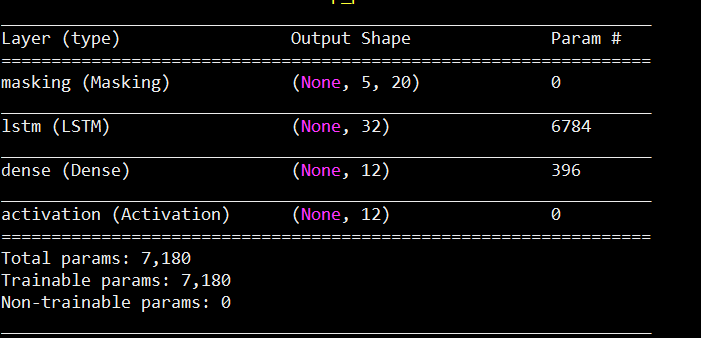
生成模型文件如下:
测试对话模型
经过训练,我们已经得到了对话模型,那现在我们就来测试一下。
测试命令如下:
python -m rasa_core.run -d models/chat1 参数-d:指定模型路径
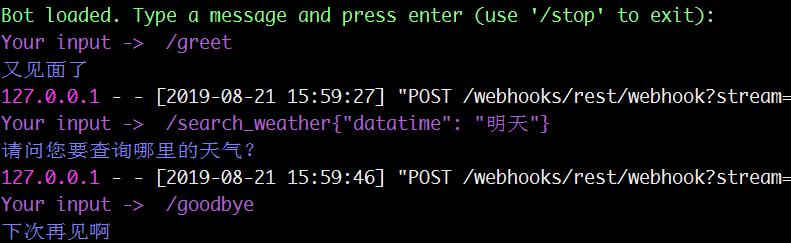
注:此时测试rasa_core对话模型,并没有加入core_nlu模型,因此还无法进行意图识别,只能够根据已知的意图(输入意图)返回特定的答案。因此,我们测试的时候,需要手动输入在domain.yml中定义好的意图,输入意图以/符号开头。
如输入greet意图:/greet
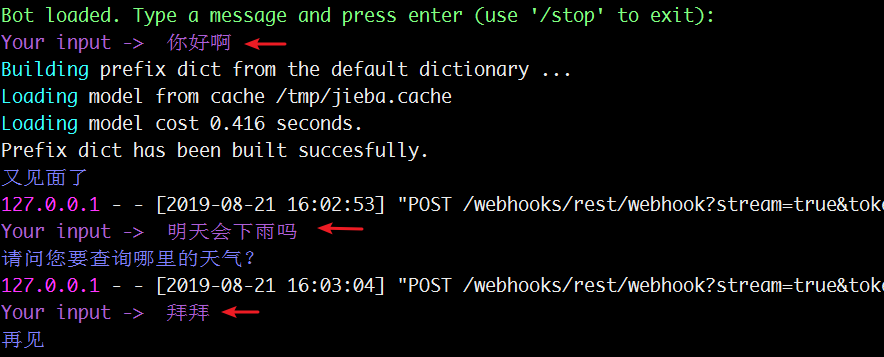
测试聊天机器人
通过前面的步骤,已经训练了Rasa_nlu的意图识别模型和Rasa_Core的对话模型。接下来就进行两者的整体的测试。
- 输入:待测试文本
- 输出:机器人回应
- 中间过程:包含意图识别、实体识别和会话流程
测试命令
python -m rasa_core.run -d models/chat1 -u models/nlu/model_-
参数解释;
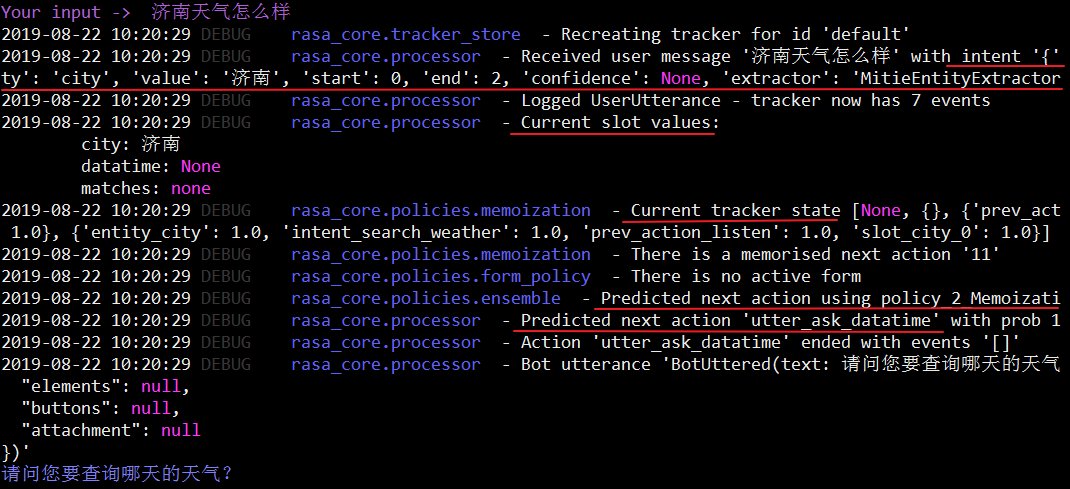
-d:modeldir 指定对话模型路径(即Rasa_core训练的模型路径)-u:Rasa NLU训练的模型路径--port:指定Rasa Core Web应用运行的端口号--credentials:指定通道(input channels)属性--endpoints:用于指定Rasa Core连接其他web server的url地址,比如nlu web-o:指定log日志文件输出路径--debug:打印调试信息。在显示的信息中,我们可以看到输入message后Rasa NLU模型是否识别出意图、实体及其置信度信息。槽位的填充以及policy预测的下一个action信息。
加入--debug参数后打印出的调试信息如下:
参考博文:
Rasa_NLU_Chi 中文处理实践 · Spring Boot
Rasa Core开发指南
Rasa使用指南01 – u0的博客 – CSDN博客
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/227057.html原文链接:https://javaforall.net


