
一 原理简介
最大熵原理是一种选择随机变量统计特性最符合客观情况的准则,也称为最大信息原理。在投资时常常讲不要把所有的鸡蛋放在一个篮子里,这样可以降低风险。在信息处理中,这个原理同样适用。在数学上,这个原理称为最大熵原理。
二 熵
可以考虑从 log \log log函数的性质方面考虑熵的定义,下面是熵定义的公式。
H ( X ) = − ∑ x p ( x ) log p ( x ) = − ∑ i = 1 n p ( x i ) log p ( x i ) H(X) = -\sum_{x}p(x)\log p(x)=-\sum_{i=1}^np(x_i)\log p(x_i) H(X)=−x∑p(x)logp(x)=−i=1∑np(xi)logp(xi)

H ( X ) H(X) H(X)就被称为随机变量 X X X的熵,它是表示随机变量不确定的度量,是对所有可能发生的事件产生的信息量的期望。从公式可得,随机变量的取值个数越多,状态数也就越多,信息熵就越大,混乱程度就越大。当随机分布为均匀分布时,熵最大,且 0 ≤ H ( X ) ≤ log n 0\leq H(X)\leq \log n 0≤H(X)≤logn。
- 简单案例
现在考虑一个具有4种可能的状态的随机变量 { a , b , c , d } \begin{aligned}\left\{ a,b,c,d\right\}\end{aligned} {
a,b,c,d},每个状态各自的概率为 1 2 \frac{1}{2} 21。这种情形下的熵为:
H ( X ) = − 4 × 1 4 log 2 1 4 = 2 b i t s H(X) =-4 \times \frac{1}{4}\log_2\frac{1}{4} = 2\ bits H(X)=−4×41log241=2 bits
假如各个状态的取值为 ( 1 2 1 4 1 8 1 8 ) \begin{aligned}\left(\frac{1}{2} \frac{1}{4} \frac{1}{8} \frac{1}{8} \right)\end{aligned} (21418181),这时熵为:
H ( X ) = − 1 2 × log 2 1 2 − 1 4 × log 2 1 4 − 1 8 × log 2 1 8 − 1 8 × log 2 1 8 = 1.75 b i t s H(X) =-\frac{1}{2} \times \log_2\frac{1}{2}-\frac{1}{4} \times \log_2\frac{1}{4}-\frac{1}{8} \times \log_2\frac{1}{8}-\frac{1}{8} \times \log_2\frac{1}{8}=1.75\ bits H(X)=−21×log221−41×log241−81×log281−81×log281=1.75 bits
我们可以看到,非均匀分布比均匀分布的熵要小。
- 证明 0 ≤ H ( X ) ≤ log n 0\leq H(X)\leq \log n 0≤H(X)≤logn
利用拉格朗日乘子法证明:由 p ( 1 ) + p ( 2 ) + ⋯ + p ( n ) = 1 p(1)+p(2)+\cdots+p(n)=1 p(1)+p(2)+⋯+p(n)=1得
目标函数: f ( p ( 1 ) , p ( 2 ) , ⋯ , p ( n ) ) = − ( p ( 1 ) log p ( 1 ) + p ( 2 ) log p ( 2 ) + ⋯ + p ( n ) log p ( n ) ) f(p(1),p(2),\cdots,p(n))=-(p(1)\log p(1)+p(2)\log p(2)+\cdots+p(n)\log p(n)) f(p(1),p(2),⋯,p(n))=−(p(1)logp(1)+p(2)logp(2)+⋯+p(n)logp(n))
约束条件 g ( p ( 1 ) , p ( 2 ) , ⋯ , p ( n ) , λ ) = p ( 1 ) + p ( 2 ) + ⋯ + p ( n ) − 1 = 0 g(p(1),p(2),\cdots,p(n),\lambda)=p(1)+p(2)+\cdots+p(n)-1=0 g(p(1),p(2),⋯,p(n),λ)=p(1)+p(2)+⋯+p(n)−1=0- 1 定义拉格朗日函数
L ( p ( 1 ) , p ( 2 ) , ⋯ , p ( n ) , λ ) = − ( p ( 1 ) log p ( 1 ) + p ( 2 ) log p ( 2 ) + ⋯ + p ( n ) log p ( n ) ) + λ ( p ( 1 ) + p ( 2 ) + ⋯ + p ( n ) − 1 ) L(p(1),p(2),\cdots,p(n),\lambda)=-(p(1)\log p(1)+p(2)\log p(2)+\cdots+p(n)\log p(n))+\lambda(p(1)+p(2)+\cdots+p(n)-1) L(p(1),p(2),⋯,p(n),λ)=−(p(1)logp(1)+p(2)logp(2)+⋯+p(n)logp(n))+λ(p(1)+p(2)+⋯+p(n)−1) - 2 L ( p ( 1 ) , p ( 2 ) , ⋯ , p ( n ) , λ ) L(p(1),p(2),\cdots,p(n),\lambda) L(p(1),p(2),⋯,p(n),λ)分别对 p ( 1 ) , p ( 2 ) , ⋯ , p ( n ) , λ p(1),p(2),\cdots,p(n),\lambda p(1),p(2),⋯,p(n),λ求偏导数,令偏导数为0
λ − log ( e ⋅ p ( 1 ) ) = 0 λ − log ( e ⋅ p ( 2 ) ) = 0 ⋯ ⋯ λ − log ( e ⋅ p ( n ) ) = 0 p ( 1 ) + p ( 2 ) + ⋯ + p ( n ) − 1 = 0 \begin{aligned} \lambda – \log(e \cdot p(1))&=0\\ \lambda – \log(e \cdot p(2))&=0\\ \cdots \cdots \\ \lambda – \log(e \cdot p(n))&=0\\ p(1)+p(2)+\cdots+p(n)-1&=0 \end{aligned} λ−log(e⋅p(1))λ−log(e⋅p(2))⋯⋯λ−log(e⋅p(n))p(1)+p(2)+⋯+p(n)−1=0=0=0=0 - 3 求出 p ( 1 ) , p ( 2 ) , ⋯ , p ( n ) p(1),p(2),\cdots,p(n) p(1),p(2),⋯,p(n)的值
解方程容易求的: p ( 1 ) = p ( 2 ) = ⋯ = p ( n ) = 1 n p(1)=p(2)=\cdots=p(n)=\frac{1}{n} p(1)=p(2)=⋯=p(n)=n1,代入 f ( p ( 1 ) , p ( 2 ) , ⋯ , p ( n ) ) f(p(1),p(2),\cdots,p(n)) f(p(1),p(2),⋯,p(n))中得到目标函数的极值为 f ( 1 n , 1 n , ⋯ , 1 n ) = − log 1 n = log n f(\frac{1}{n},\frac{1}{n},\cdots,\frac{1}{n})=-\log \frac{1}{n}=\log n f(n1,n1,⋯,n1)=−logn1=logn
易知 log 1 = 0 \log 1 =0 log1=0,容易证得: 0 ≤ H ( X ) ≤ log n 0\leq H(X)\leq \log n 0≤H(X)≤logn。从熵的定义方面思考这一公式,熵是对信息不确定性的度量。当一件事情完全确定,概率为1时,这个时候熵自然最小;当事情等概率发生,这时候信息的不确定性最大,熵自然最大。
- 1 定义拉格朗日函数
条件熵
条件熵 H ( Y ∣ X ) H(Y |X ) H(Y∣X)表示在已知随机变量 X X X的条件下随机变量 Y Y Y的不确定性。
H ( Y ∣ X ) = ∑ x p ( x ) H ( Y ∣ X = x ) = − ∑ x p ( x ) ∑ y p ( y ∣ x ) log p ( y ∣ x ) = − ∑ x ∑ y p ( x , y ) log p ( y ∣ x ) = − ∑ x , y p ( x , y ) log p ( y ∣ x ) \begin{aligned} H(Y|X) &= \sum_xp(x)H(Y|X=x) \\ &=- \sum_xp(x)\sum_yp(y|x)\log p(y|x)\\ &=- \sum_x\sum_yp(x,y)\log p(y|x)\\ &=- \sum_{x,y}p(x,y)\log p(y|x) \end{aligned} H(Y∣X)=x∑p(x)H(Y∣X=x)=−x∑p(x)y∑p(y∣x)logp(y∣x)=−x∑y∑p(x,y)logp(y∣x)=−x,y∑p(x,y)logp(y∣x)
三 最大熵原理
假如现在有一个色子,让你猜测每个面向上的概率分别是多少?
最合理的猜测:各个面的概率均为1/6,从投资的角度来说,这是风险最小的做法。
假如现在告诉你,这个色子被做过手脚,已知一点向上的概率是1/3,在这种情况下,其他面向上的概率是多少?
除去一点的概率是1/3,其余的均是2/15。也就是在满足已知条件的情况下,将其余各点的概率均分。
这种基于直觉的猜测恰恰符合了最大熵的原理。
四 最大熵模型的简单实例
但上面的限制,都没有考虑上下文的环境,翻译效果不好,因此我们引入特征。
例如,英文“take”翻译为“乘坐”的概率很小,但是当“take”后面跟一个交通工具的名字“bus”时,它翻译成“乘坐”的概率就变得非常大。为了表示take跟有bus时,翻译成“乘坐”的事件,我们引入二值函数:
f ( x , y ) = { 1 1 if y=“乘坐” and ˆ next(x)=“bus” 0 f(x,y)= \begin{cases} 1& \text{1 if y=“乘坐” and \^ next(x)=“bus”}\\ 0& \end{cases} f(x,y)={
101 if y=“乘坐” and ˆnext(x)=“bus”
x表示上下文环境,这里可以看作是含有单词take的一个英文短语,而y代表输出,对应着“take”的中文翻译。^next (x) 看作是上下文环境x的一个函数,表示x中跟在单词take后的一个单词为“bus”。这样一个函数我们称作一个特征函数,或者简称一个特征。特征是为了使我们的模型具有更强的泛化能力。
引入诸如上述公式的特征,它们对概率分布模型加以限制,求在限制条件下具有一致分布的模型,该模型熵值最大。
五 拉格朗日对偶问题
- x不满足原始问题的约束条件,即有 c ( x ) > 0 c(x)>0 c(x)>0或 h ( x ) ≠ 0 h(x)\neq 0 h(x)=0。那么上式求解max的解为无穷大,因为这个时候可以取 a i = ∞ , β j h j = ∞ a_i = \infty,\beta_jh_j=\infty ai=∞,βjhj=∞
- x满足原始问题的约束条件,则上式取max时, α = 0 , h ( x ) = 0 \alpha=0,h(x)=0 α=0,h(x)=0,这时发现上式的最大值条件不存在了,最大值就是定值 f ( x ) f(x) f(x)
所以在满足原始问题约束的条件下, θ p ( x ) = f ( x ) \theta_p(x)=f(x) θp(x)=f(x)。去掉原始问题中的 s . t . s.t. s.t.条件,得到原始问题的等价问题:
m i n x f ( x ) = m i n x θ p ( x ) = m i n x m a x α , β L ( x , α , β ) min_x f(x)=min_x \theta_p(x) = min_x max_{\alpha,\beta} L(x,\alpha,\beta) minxf(x)=minxθp(x)=minxmaxα,βL(x,α,β) - 对偶问题:若原始问题和对偶问题都有最优值,则对偶问题最优值 d ∗ d^* d∗ <=原始问题最优值 p ∗ p^* p∗
d ∗ = m a x α , β m i n L ( x , α , β ) ≤ m i n x m a x α , β L ( x , α , β ) = p ∗ d^* = max_{\alpha,\beta} min L(x,\alpha,\beta) \leq min_x max_{\alpha,\beta} L(x,\alpha,\beta) = p^* d∗=maxα,βminL(x,α,β)≤minxmaxα,βL(x,α,β)=p∗
直观理解:清华北大的差生的成绩也比一般学校的优生成绩好。或者说:从一群人中挑选10个人,先挑20个矮个子再从中选择10个高个子所得到人的身高是小于等于先挑20个高个子再从其中选择10个矮个子的人身高。 - 求解对偶问题的好处
对于对偶问题来说,我们求解最小化部分时没有任何限制条件,而没有限制条件的最小化问题的解一定是在求得x的偏导数=0处,那我们就能得到一些等式,将这些等式代入拉格朗日函数中就可以简化计算。
六 模型框架形式化描述
假设对于训练数据有一个样本集合 { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n ) } \begin{aligned}\left\{ (x_1,y_1),(x_2,y_2),\cdots,(x_n,y_n) \right\}\end{aligned} {
(x1,y1),(x2,y2),⋯,(xn,yn)},每一个 x i ( 1 ≤ i ≤ n ) x_i(1 ≤ i ≤ n) xi(1≤i≤n)表示一个上下文, y i ( 1 ≤ i ≤ n ) y_i (1 ≤ i ≤ n) yi(1≤i≤n)表示对应的结果。对于这个训练样本,我们得到 ( x , y ) (x,y) (x,y)的经验分布,定义如下:
p ~ ( x , y ) = 1 N × n u m b e r o f t i m e s t h a t ( x , y ) o c c u r s i n t h e s a m p l e \begin{aligned} \widetilde p(x,y) = \frac{1}{N}\times number\ of\ times\ that(x,y)\ occurs\ in\ the\ sample \end{aligned} p
(x,y)=N1×number of times that(x,y) occurs in the sample
要对上面大小为N的训练样本集合建立统计模型,可利用的是样本集合的统计数据。模型中特征函数的引入,使模型依赖于上下文的信息。假设我们给出n个特征函数 f i f_i fi,对每个特征条件进行限制:期望概率值等于经验值
p ( f i ) = p ~ ( f i ) i ∈ { 1 , 2 , ⋯ , n } \begin{aligned} p(f_i)= \widetilde p(f_i) i \in \left\{1,2,\cdots,n \right\} \end{aligned} p(fi)=p
(fi)i∈{
1,2,⋯,n}
其中期望值和经验值分别为:
p ( f ) = ∑ x , y p ~ ( x ) p ( y ∣ x ) f ( x , y ) p ~ ( f ) = p ~ ( x , y ) f ( x , y ) \begin{aligned} p(f)&=\sum_{x,y} \widetilde p(x)p(y|x)f(x,y)\\ \widetilde p(f)&= \widetilde p(x,y)f(x,y) \end{aligned} p(f)p
(f)=x,y∑p
(x)p(y∣x)f(x,y)=p
(x,y)f(x,y)
要求出最优的 P ( y ∣ x ) P(y|x) P(y∣x)值,我们要得到一个最为一致分布的模型,条件熵作为衡量一致的标准。熵的最小值是0,这时模型没有任何不确定性;熵的最大值是 l o g ∣ Y ∣ log|Y| log∣Y∣, 即在所有可能的 y y y上的均匀分布。
求在限制条件下具有最大熵值的模型, C C C表示所有可能满足限制条件的概率分布模型的集合
m a x p ∈ C H ( P ) = − ∑ x , y p ~ ( x ) p ( y ∣ x ) log p ( y ∣ x ) C = { p ∈ P ∣ p ( f i ) = p ~ ( f i ) f o r i i n ( 1 , 2 , ⋯ , n ) } \begin{aligned} max_{p \in C} H(P) = – \sum_{x,y} \widetilde{p}(x)p(y|x)\log p(y|x)\\ C = \left \{p \in P|p(f_i)=\widetilde{p}(f_i) for\ i\ in\ (1,2,\cdots,n)\right\} \end{aligned} maxp∈CH(P)=−x,y∑p
(x)p(y∣x)logp(y∣x)C={
p∈P∣p(fi)=p
(fi)for i in (1,2,⋯,n)}
H ( P ) H(P) H(P)满足以下限制:
p ( y ∣ x ) ≥ 0 f o r a l l x , y ∑ y p ( y ∣ x ) = 1 f o r a l l x ∑ x , y p ~ ( x ) p ( y ∣ x ) f ( x , y ) = ∑ x , y p ~ ( y ∣ x ) f ( x , y ) f o r i ∈ { 1 , 2 , ⋯ , n } \begin{aligned} p(y|x) &\geq 0\ for \ all \ x,\ y\\ \sum_y p(y|x) &= 1\ for\ all\ x \\ \sum_{x,y} \widetilde{p}(x)p(y|x)f(x,y) &= \sum_{x,y} \widetilde{p}(y|x)f(x,y) \ for\ i \in \left\{ 1,2,\cdots,n \right\} \end{aligned} p(y∣x)y∑p(y∣x)x,y∑p
(x)p(y∣x)f(x,y)≥0 for all x, y=1 for all x=x,y∑p
(y∣x)f(x,y) for i∈{
1,2,⋯,n}
七 GIS算法原理
最大熵模型参数训练的任务就是选取有效的特征 f i f_i fi及其权重 w i w_i wi。由于特征数量大,模型复杂,因此需要依赖数值解的方法,下面介绍GIS算法。GIS算法要求对训练样本集中每个实例的任意 ( x , y ) ∈ X × Y (x,y)\in X\times Y (x,y)∈X×Y,特征函数之和为常数,即对每个实例的k个特征函数均满足 ∑ i = 1 k f i ( x , y ) = C \sum_{i=1}^kf_i(x,y)=C ∑i=1kfi(x,y)=C(C为一常数)。如果该条件不能满足,则在训练集中取: C = m a x x ∈ X , y ∈ Y ∑ i = 1 k f i ( x , y ) C=max_{x\in X,y\in Y}\sum_{i=1}^kf_i(x,y) C=maxx∈X,y∈Y∑i=1kfi(x,y),并增加一个特征 f l : f l ( x , y ) = C − ∑ i = 1 k f i ( x , y ) f_l:f_l(x,y)=C-\sum_{i=1}^kf_i(x,y) fl:fl(x,y)=C−∑i=1kfi(x,y)。其中 l = k + 1 l=k+1 l=k+1。与其他特征函数不一样, f l ( x , y ) f_l(x,y) fl(x,y)的取值范围为:0~C。
GIS的算法流程如下:(N表示样本总数,n表示特征总数)
(1)初始化: w [ 1 ⋯ l ] = 0 w[1 \cdots l]=0 w[1⋯l]=0;
(2)根据公式 p ~ ( f ) = p ~ ( x , y ) f ( x , y ) \widetilde p(f)=\widetilde p(x,y)f(x,y) p
(f)=p
(x,y)f(x,y)计算每个特征函数 f i f_i fi的训练样本期望值 p ~ ( f ) \widetilde p(f) p
(f);
(3)执行如下循环,迭代计算特征函数的模型期望值:
- [1] 利用如下公式计算 p ~ ( x , y ) \widetilde{p}(x,y) p
(x,y)
P ~ ( y ∣ x ) = e x p ( ∑ i = 1 l w i f i ( x , y ) ) z ( x ) z ( x ) = ∑ y e x p ( ∑ i = 1 l w i f i ( x , y ) ) \begin{aligned} \widetilde{P}(y|x)= \frac{exp(\sum_{i=1}^lw_if_i(x,y))}{z(x)}\\ z(x)= \sum_y exp(\sum_{i=1}^lw_if_i(x,y)) \end{aligned} P
(y∣x)=z(x)exp(∑i=1lwifi(x,y))z(x)=y∑exp(i=1∑lwifi(x,y)) - [2]若满足终止条件,则结束迭代;否则修正 w w w
w n + 1 = w n + 1 C ln ( P ~ ( f i ) P x ( n ) ( f i ) ) n 为 循 环 迭 代 次 数 \begin{aligned} w^{n+1}=w^{n}+\frac{1}{C}\ln(\frac{\widetilde{P}(f_i)}{P_{x(n)}(f_i)}) \ n为循环迭代次数 \end{aligned} wn+1=wn+C1ln(Px(n)(fi)P
(fi)) n为循环迭代次数
(4)算法结束,确定 w w w,算出每个 p ~ ( y ∣ x ) \widetilde{p}(y|x) p
(y∣x)
迭代终止的条件可以为限定的迭代次数,也可以是对数似然 L ( p ) L(p) L(p)的变化值小于某个阈值 ϵ \epsilon ϵ。
∣ L n + 1 − L n ∣ < ϵ L ( p ) = ∑ x , y p ~ ( x , y ) log p ( y ∣ x ) \begin{aligned} |L_{n+1}-L_n|< \epsilon\\ L(p)=\sum_{x,y}\widetilde{p}(x,y)\log p(y|x) \end{aligned} ∣Ln+1−Ln∣<ϵL(p)=x,y∑p
(x,y)logp(y∣x)
八 python代码实现
- 定义
MaxEnt类,主要属性如下:
import math from collections import defaultdict class MaxEnt: def __init__(self): self._samples = [] # 样本集, 元素是[y,x1,x2,...,xn]的元组 self._Y = set([]) # 标签集合,相当于去重之后的y self._numXY = defaultdict(int) # Key是(xi,yi)对,Value是count(xi,yi) self._N = 0 # 样本数量 self._n = 0 # 特征对(xi,yi)总数量 self._xyID = {
} # 对(x,y)对做的顺序编号(ID), Key是(xi,yi)对,Value是ID self._C = 0 # 样本最大的特征数量,用于求参数时的迭代,见IIS原理说明 self._ep_ = [] # 样本分布的特征期望值 self._ep = [] # 模型分布的特征期望值 self._w = [] # 对应n个特征的权值 self._lastw = [] # 上一轮迭代的权值 self._EPS = 0.01 # 判断是否收敛的阈值 - 加载训练数据
训练数据的格式为“标注+特征”的格式,特征之间以空格分隔。
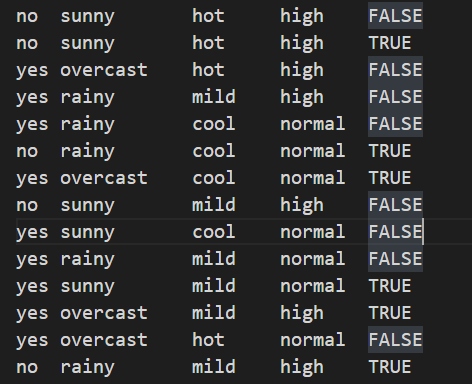
# 加载训练数据 def load_data(self, filename): for line in open(filename, "r", encoding='utf-8'): sample = line.strip().split() if len(sample) < 2: # 至少:标签+一个特征 continue y = sample[0] # 标注 X = sample[1:] # 特征 self._samples.append(sample) # label + features self._Y.add(y) # label for x in set(X): # set给X去重 self._numXY[(x, y)] += 1 - 初始化参数
样本数量、特征对数、特征权重、上一轮迭代的权重初始化为0
# 初始参数 def _initparams(self): self._N = len(self._samples) # 样本数量 self._n = len(self._numXY) # (xi,yi)总数量,没有做任何特征提取操作,直接操作特征 self._C = max([len(sample) - 1 for sample in self._samples]) # 样本最大的特征数量 self._w = [0.0] * self._n # 初始权重设为零 self._lastw = self._w[:] self._sample_ep() # 计算样本期望 - 判断是否收敛
# 判断是否收敛 def _convergence(self): for w, lw in zip(self._w, self._lastw): if math.fabs(w - lw) >= self._EPS: return False return True - 计算z(x)
输入的 X X X为每个标签对应的特征
def _zx(self, X): ZX = 0.0 for y in self._Y: sum = 0.0 for x in X: if (x, y) in self._numXY: # 遍历键(xi,yi) sum += self._w[self._xyID[(x, y)]] ZX += math.exp(sum) return ZX - 初始化样本分布中的特征期望值
每个特征的期望初始化为: 当 前 特 征 数 总 特 征 数 \frac{当前特征数}{总特征数} 总特征数当前特征数为每个特征标记一个ID
def _sample_ep(self): self._ep_ = [0.0] * self._n for i, xy in enumerate(self._numXY): self._ep_[i] = self._numXY[xy] * 1.0 / self._N self._xyID[xy] = i - 计算p(y|x)
def _pyx(self, X): ZX = self._zx(X) results = [] for y in self._Y: sum = 0.0 for x in X: if (x, y) in self._numXY: # 这个判断相当于指示函数的作用 sum += self._w[self._xyID[(x, y)]] pyx = 1.0 / ZX * math.exp(sum) results.append((y, pyx)) return results - 计算模型分布的特征期望
def _model_ep(self): self._ep = [0.0] * self._n for sample in self._samples: X = sample[1:] pyx = self._pyx(X) for y, p in pyx: for x in X: if (x, y) in self._numXY: self._ep[self._xyID[(x, y)]] += p * 1.0 / self._N - 训练数据
设置迭代次数maxiter=100,每轮迭代,保存上一轮权重。
def train(self, maxiter=1000): self._initparams() for i in range(0, maxiter): print("Iter:%d..." % i) self._lastw = self._w[:] # 保存上一轮权值 self._model_ep() # 更新每个特征的权值 for i, w in enumerate(self._w): # 参考GIS迭代公式 self._w[i] += 1.0 / self._C * math.log( self._ep_[i] / self._ep[i]) print(self._w, "数量:", len(self._w)) # 检查是否收敛 if self._convergence(): break - 进行预测
def predict(self, input): X = input.strip().split("\t") prob = self._pyx(X) return prob - 主函数调用
if __name__ == "__main__": maxent = MaxEnt() maxent.load_data(r"./data.txt") maxent.train() # 特征 play outlook temperature humidity windy print(maxent.predict("sunny\thot\thigh\tFALSE")) print(maxent.predict("overcast\thot\thigh\tFALSE")) print(maxent.predict("sunny\tcool\thigh\tTRUE")) print(maxent.predict("")) - 实验结果

参考资料
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/227772.html原文链接:https://javaforall.net


