
|
首先我来介绍一下什么是文本聚类,最简单的来说文本聚类就是从很多文档中把一些 内容相似的文档聚为一类。文本聚类主要是依据著名的聚类假设:同类的文本相似度较大,而不同类的文本相似度较小。作为一种无监督的机器学习方法,聚 类由于不需要训练过程,以及不需要预先对文本手工标注类别,因此具有一定的灵活性和较高的自动化处理能力,已经成为对文本信息进行有效地组织、摘要和导航 的重要手段,为越来越多的研究人员所关注。一个文本表现为一个由文字和标点符号组成的字符串,由字或字符组成词,由词组成短语,进而形成句、段、节、章、 篇的结构。要使计算机能够高效地处理真是文本,就必须找到一种理想的形式化表示方法,这种表示一方面要能够真实地反应文档的内容(主题、领域或结构等), 另一方面,要有对不同文档的区分能力。目前文本表示通常采用向量空间模型(vector space model,VSM)。 VSM法即向量空间模型(Vector Space Model)法,由Salton等人于60年代末提出。这是最早也是最出名的信息检索方面的数学模型。其基本思想是将文档表示为加权的特征向 量:D=D(T1,W1;T2,W2;…;Tn,Wn),然后通过计算文本相似度的方法来确定待分样本的类别。当文本被表示为空间向量模型的时候,文本的 相似度就可以借助特征向量之间的内积来表示。最简单来说一个文档可以看成是由若干个单词组成的,每个单词转化成权值以后, 每个权值可以看成向量中的一个分量,那么一个文档可以看成是n维空间中的一个向量,这就是向量空间模型的由来。单词对应的权值可以通过TF-IDF加权技 术计算出来。 TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与文本挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的 其中一份文件的重要程 度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式 常被搜索引擎应用,作为文件与用户查询之间相关程度 的度量或评级。除了TF-IDF以外,互联网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。 原理:
以上式子中 ni,j 是该词在文件dj中的出现次 数,而分母则是在文件dj中所 有字词的出现次数之和。 逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
其中
然后
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词 语,保留重要的词语。 例子有很多不同的数学公式可以用来计 算TF-IDF。这边的例子以上述的数学公式来计算。词频 (TF) 是一词语出现的次数除以该文件的总词语数。假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是 0.03 (3/100)。一个计算文件频率 (DF) 的方法是测定有多少份文件出现过“母牛”一词,然后除以文件集里包含的文件总数。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是 10,000,000份的话,其逆向文件频率就是 9.21 ( ln(10,000,000 / 1,000) )。最后的TF-IDF的分数为0.28( 0.03 * 9.21)。TF-IDF权重计算方法经常会和余 弦相似度(cosine similarity)一同使用于向 量空间模型中,用以判断两份文件之间的相 似性。学过向量代数的人都知道,向量实际上是多维空间中有方向的线段。如果两个向量的方向一致,即夹角接近零,那么这两个向量就相近。而要确定两 个向量方向是否一致,这就要用到余弦定理计算向量的夹角了。
当两条文本向量夹角的余弦等于一时,这两个文本完全重复(用这个办法可以删除重复的网页);当夹角的余弦接近于一时,两个文本相似,从而可以归成一类;夹 角的余弦越小,两个文本越不相关。
最后我们在对文本进行聚类时要用到数据挖掘中的Kmeans算法,聚类算法有很多种,这篇文章主要介绍Kmeans算法。K-MEANS算法: 处理流程: 到这里这个文本聚类的小程序的核心思想就讲完了,总的来说大致步骤如 下: (1)对各个文本分词,去除停用词 (2)通过TF-IDF方法获得文本向量的权值(每个文本向量的维数是 相同的,是所有文本单词的数目,这些单词如果有重复那只算一次,所以如果文本越多,向量的维数将会越大) (3)通过K-means算法对文本进行分类 本人的文本小程序的结 果还算令人满意,对下面的实验用例的聚类结果还算是理想,但是每次执行的结果都不一样。其实聚类的结果受好多种因素制约,提取特征的算法,随机初始化函 数,kmeans算法的实现等,都有优化的地方,不信你把输入的数据的顺序改改,聚类结果就不一样了,或者把随机数的种子变一下,结果也不一样,k- means算法加入一些变异系数的调整,结果也不一样,提取特征的地方不用TF/IDF权重算法用别的,结果肯定也不一样。 实验用例: |
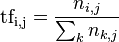


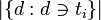
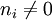





发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/228062.html原文链接:https://javaforall.net


