
简介
特点
为什么要学习SparkSQL?
DataFrames
RDD和DataFrame的区别


创建DataFrames
1)spark-shell版本
spark中已经创建好了SparkContext和SQLContext对象
2)代码:
spark-shell –master spark://hadoop1:7077 –executor-memory 512m –total-executor-cores 2
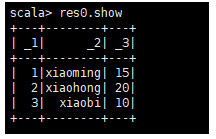
//创建了一个数据集,实现了并行化
val seq= Seq((“1”,“xiaoming”,15),(“2”,“xiaohong”,20),(“3”,“xiaobi”,10))



_1:列名,String当前列的数据类型
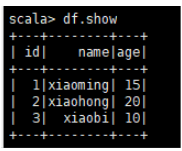
//查看数据 show 算子来打印,show是一个action类型 算子
df.show
DSL 风格语法
1.查询:
df.select("name").show df.select("name","age")..show //条件过滤 df.select("name","age").filter("age >10").show //参数必须是一个字符串,filter中的表达式也需要时一个字符串 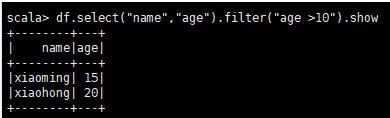
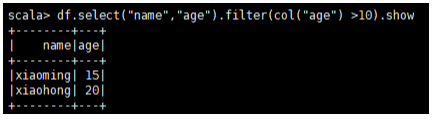
//2.参数是类名col (“列名”)
df.select(“name”,“age”).filter(col(“age”) >10).show
//3.分组统计个数
df.groupBy("age").count().show() 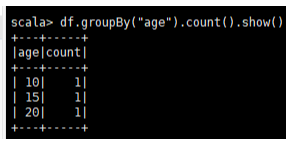
df.printSchema 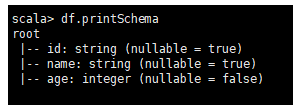

Hive中orderby和sortby的区别?
5.orderby 是全局有序 distribute sort by :局部有序,全局无序
结构表信息:
sqlContext.sql(“desc t_person”).show
以编码的形式来执行sparkSQL
先将工程中的maven添加配置
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.10</artifactId> <version>1.6.3</version> </dependency> 第一种通过反射方式推断
SparkSQLDemo1.scala
import org.apache.spark.rdd.RDD import org.apache.spark.sql.{
DataFrame, SQLContext} import org.apache.spark.{
SparkConf, SparkContext} / * sparkSQL --就是查询 */ object SparkSQLDemo1 {
def main(args: Array[String]): Unit = {
//之前在spark-shell中,sparkContext和SQLContext是创建好的 所以不需要创建 //因为是代码编程,需要进行创建 val conf = new SparkConf().setAppName("SparkSQLDemo1").setMaster("local") val sc =new SparkContext(conf) //创建SQLContext对象 val sqlc = new SQLContext(sc) //集群中获取数据生成RDD val lineRDD: RDD[Array[String]] = sc.textFile("hdfs://hadoop2:8020/Person.txt").map(_.split(" ")) //lineRDD.foreach(x => println(x.toList)) //将获取数据 关联到样例类中 val personRDD: RDD[Person] = lineRDD.map(x => Person(x(0).toInt,x(1),x(2).toInt)) import sqlc.implicits._ //toDF相当于反射,这里若要使用的话,需要导入包 / * DataFrame [_1:int,_2:String,_3:Int] * spark-shell 数据是一个自己生成并行化数据并没有使用样例类来 存数据而是直接使用 * 直接调用toDF的时候,使用就是默认列名 _+数字 数字从1开始逐渐递增 * 可以在调用toDF方法的时候指定类的名称(指定名称多余数据会报错) * * 列名不要多余,也不要少于 * 也就是说列名要和数据一一对应 * * 使用代码编程数据是存储到样例类中,样例类中的构造方法中的参数就是对应的列名 * 所以通过toDF可以直接获取对应的属性名作为列名使用 * 同时也可以自定义列名 * */ val personDF: DataFrame = personRDD.toDF() //val personDF: DataFrame = personRDD.toDF("ID","NAME","AGE") personDF.show() //使用Sql语法 //注册临时表,这个表相当于存储在 SQLContext中所创建对象中 personDF.registerTempTable("t_person") val sql = "select * from t_person where age > 20 order by age" //查询 val res = sqlc.sql(sql) // def show(numRows: Int, truncate: Boolean): Unit = println(showString(numRows, truncate)) //默认打印是20行 res.show() //固化数据 //将数据写到文件中mode是以什么形式写 写成什么文件 / * def mode(saveMode: String): DataFrameWriter = { * this.mode = saveMode.toLowerCase match { * case "overwrite" => SaveMode.Overwrite -复写 * case "append" => SaveMode.Append -- 追加 * case "ignore" => SaveMode.Ignore * case "error" | "default" => SaveMode.ErrorIfExists * case _ => throw new IllegalArgumentException(s"Unknown save mode: $saveMode. " + * "Accepted modes are 'overwrite', 'append', 'ignore', 'error'.") * */ // res.write.mode("append").json("out3") // hdfs://hadoop2:8020/out111") //除了这两种还可以csv模式,json模式 //csv在 1.6.3 spark中需要第三方插件,才能使用能使用,,,,2.0之后自动集成 //这个方法不要使用因为在2.0会被删除 res.write.mode("append").save("hdfs://hadoop2:8020/out111") } case class Person(id:Int,name:String,age:Int) } 第二通过StructType
SparkSQLStructTypeDemo.scala
import org.apache.spark.rdd.RDD import org.apache.spark.sql.{
DataFrame, Row, SQLContext} import org.apache.spark.sql.types.{
IntegerType, StringType, StructField, StructType} import org.apache.spark.{
SparkConf, SparkContext} object SparkSQLStructTypeDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SparkSQLStructTypeDemo").setMaster("local") val sc = new SparkContext(conf) val sqlcontext = new SQLContext(sc) //获取数据并拆分 val lineRDD = sc.textFile("hdfs://hadoop2:8020/Person.txt").map(_.split(" ")) //创建StructType对象 封装了数据结构(类似于表的结构) val structType: StructType = StructType {
List( //列名 数据类型 是否可以为空值 StructField("id", IntegerType, false), StructField("name", StringType, true), StructField("name", IntegerType, false) //列需要和数据对应,但是StructType这种可以: / * 列的数据大于数据,所对应列的值应该是null * 列数是不能小于数据,不然会抛出异常 * StructField("oop", IntegerType, false) * StructField("poo", IntegerType, false) */ ) } //将数据进行一个映射操作 val rowRDD: RDD[Row] = lineRDD.map(arr => Row(arr(0).toInt,arr(1),arr(2).toInt)) //将RDD转换为DataFrame val personDF: DataFrame = sqlcontext.createDataFrame(rowRDD,structType) personDF.show() } } 1.将当前程序打包操作提交到集群,需要做 一定的更改 ,注意path路径 修改为 args(下标)
模式:
spark-submit
–class 类名(类的全限定名(包名+类名))
–master spark://集群:7077
/root/jar包路径
输入数据路径
输出路径数据
JDBC数据源
SparkSql可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,在通过对DataFrame的一系列操作,还可以将数据写到关系型数据库中
spark-shell --master spark://hadoop1:7077 --executor-memory 512m --total-executor-cores 2 --jars /root/mysql-connector-java-5.1.32.jar --driver-class-path /root/mysql-connector-java-5.1.32.jar 将数据写入到Mysql中
import org.apache.spark.rdd.RDD import org.apache.spark.sql.{
DataFrame, Row, SQLContext} import org.apache.spark.sql.types.{
IntegerType, StringType, StructField, StructType} import org.apache.spark.{
SparkConf, SparkContext} object DataFormeInputJDBC {
/* def createSC(AppName:String,Master:String):SparkContext = { } def createSC(AppName:String,Master:String,sc:SparkContext):SQLContext = { }*/ def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("DataFormeInputJDBC").setMaster("local") val sc = new SparkContext(conf) val sqlContext = new SQLContext(sc) //获取数据拆分 val lines = sc.textFile("hdfs://hadoop1:8020/Person.txt").map(_.split(" ")) // StructType 存的表结构 val structType: StructType = StructType(Array(StructField("id", IntegerType, false), StructField("name", StringType, true), StructField("age", IntegerType, true))) //开始映射 val rowRDD: RDD[Row] = lines.map(arr => Row(arr(0).toInt,arr(1),arr(2).toInt)) //将当前RDD转换为DataFrame val personDF: DataFrame = sqlContext.createDataFrame(rowRDD,structType) //创建一个用于写入mysql配置信息 val prop = new Properties() prop.put("user","root") prop.put("password","123") prop.put("driver","com.mysql.jdbc.Driver") //提供mysql的URL val jdbcurl = "jdbc:mysql://hadoop1:3306/mydb1" //表名 val table = "person" //数据库要对,表若不存在会自动创建并存储 //需要将数据写入到jdbc //propertities的实现是HashTable personDF.write.mode("append").jdbc(jdbcurl,table,prop) println("插入数据成功") sc.stop() } } HIVE-on-Spark
hive底层是通过MR进行计算,将其改变为SparkCore来执行
配置步骤
1.在不是高可用集群的前提下,只需要将Hadoop安装目录中的core-site.xml拷贝到spark的配置conf文件目录下即可
2.将hive安装路径下的hive-site.xml拷贝到spark的配置conf配置文件目录下即可
注意:
若是高可用:需要将hadoop安装路径下的core-site,xml和hdfs-site.xml拷到spark的conf目录下
操作完成后建议重启集群
通过sparksql来操作,需要在spark安装路径中sbin目录
启动: spark-sql \ --master spark://hadoop1:7077 \ --executor-memory 512m \ --total-executor-cores 2 \ --jars /root/mysql-connector-java-5.1.32.jar \ --driver-class-path /root/mysql-connector-java-5.1.32.jar 基本操作: 1.创建表: create table person1(id int,name string,age int)row format delimited fields terminated by ' ' 2.加载数据:(本地加载) load data local inpath '/root/Person.txt' into table person1; 3.查询: select * from person1; select name,age from person where age > 20 order by age; 4.删除 drop table person 内部表和外部表
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/228073.html原文链接:https://javaforall.net

![HTML5快速设计网页[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
