
因子分析基本思想
和主成分分析相似,首先从原理上说,主成分分析是试图寻找原有自变量的一个线性组合,取出对线性关系影响较大的原始数据,作为主要成分。
因子分析,是假设所有的自变量可以通过若干个因子(中间量)被观察到。什么意思呢,举个例子,比如一个学生的考试成绩,语文80,数学95,英语79,物理97,化学94 ,那么我们认为这个学生理性思维较强,语言组织能力较弱。其中理性思维和语言组织能力就是因子。通过这两个因子,我们能够观察到他的偏理科的成绩较高,偏文科的成绩较低。这就是因子分析,通过这点,大家就可以感受到,因子分析和主成分分析是明显不一样的。
因子分析又存在两个方向,一个是探索性因子分析(exploratory factor analysis)。另一个是验证性因子分析(confirmatory factor analysis)。探索性因子分析是不确定一堆自变量背后有几个因子,我们通过这种方法试图寻找到这几个因子。而验证性因子分析是已经假设自变量背后有几个因子,试图通过这种方法去验证一下这种假设是否正确。验证性因子分析又和结构方程模型有很大关系。后面我们会专门的介绍,今天先介绍探索性因子分析。
数学推导


基于 Python 的因子分析
数据是来自行业的10 个相关指标,通过因子分析提取出一些反应不同特征的因子出来。最后根据因子对行业进行排名。
import pandas as pd import numpy as np from pandas import DataFrame,Series from factor_analyzer import FactorAnalyzer datafile = u'D:\\pythondata\\textdata.xlsx' data = pd.read_excel(datafile) data = data.fillna(0)#用0填充空值 fa = FactorAnalyzer() fa.analyze(data, 5, rotation=None)#固定公共因子个数为5个 print("公因子方差:\n", fa.get_communalities())#公因子方差 print("\n成分矩阵:\n", fa.loadings)#成分矩阵 var = fa.get_factor_variance()#给出贡献率 print("\n解释的总方差(即贡献率):\n", var) fa_score = fa.get_scores(data)#因子得分 fa_score.head() #将各因子乘上他们的贡献率除以总的贡献率,得到因子得分中间值 a = (fa.get_scores(data)*var.values[1])/var.values[-1][-1] #将各因子得分中间值相加,得到综合得分 a['score'] = a.apply(lambda x: x.sum(), axis=1) 基于R的因子分析
数据是来自上市公司的财务指标,因此想通过因子分析将财务指标进降维,希望提取出一些反应不同特征的因子出来。最后根据因子对上市公司进行排名。
#设置路径 setwd('D:/Rdata') #清除空间变量 rm(list = ls()) #载入读取excel的包 library(readxl) library(psy) #读取数据 dat.fact <- read_excel(file='MicEcoData.xlsx') head(dat.fact) # A tibble: 6 x 8 资产负债率 总资产增长率B 基本每股收益增长率B 净利润增长率B 营业利润增长率B 每股收益 每股营业收入
1 0. 0. 0.044776 0.026753 0.056436 0.7000 2.054515 2 0. 0. 0. 0. 0. 0.2500 0. 3 0.068507 1. 0. 1. 1. 0.1276 0. 4 0. 0. 1. 2. 2. 0.1902 0. 5 0. 0.083378 -0. -0. -0. 0.0600 0. 6 0. 0.061588 -0. 0. 0. 0.0500 0. # ... with 1 more variables: 销售净利率
#重新命个名 names(dat.fact) <- paste('x', 1:ncol(dat.fact), sep='') #进行因子分析,设置因子个数为两个 factor.result <- factanal(x=dat.fact, factor=2, scores="regression") #查看图 psy::scree.plot(dat.fact) #查看因子分析的各种结果 names(factor.result) [1] "converged" "loadings" "uniquenesses" "correlation" "criteria" "factors" [7] "dof" "method" "rotmat" "scores" "STATISTIC" "PVAL" [13] "n.obs" "call" print(factor.result) Call: factanal(x = dat.fact, factors = 2, scores = "regression") Uniquenesses: x1 x2 x3 x4 x5 x6 x7 x8 0.508 0.005 0.005 0.005 0.005 0.281 0.507 0.710 Loadings: Factor1 Factor2 x1 0.695 x2 0.997 x3 0.997 x4 0.998 x5 0.998 x6 0.846 x7 0.702 x8 0.251 -0.476 Factor1 Factor2 SS loadings 4.054 1.931 Proportion Var 0.507 0.241 Cumulative Var 0.507 0.748 Test of the hypothesis that 2 factors are sufficient. The chi square statistic is 357.17 on 13 degrees of freedom. The p-value is 2.4e-68 >
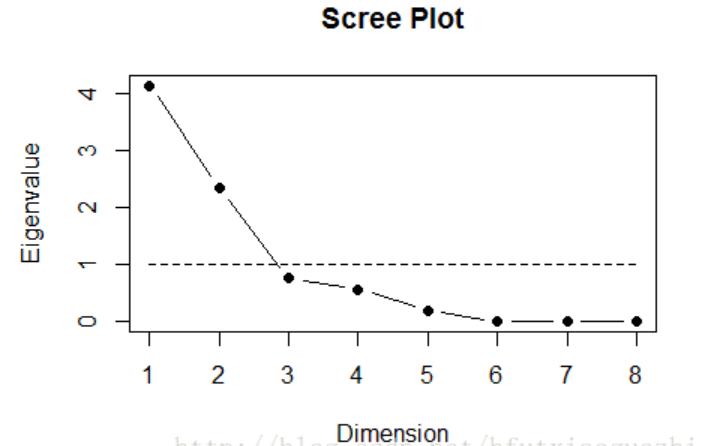
现在经过因子分析已经将原来的8个财务指标进行合并,形成了两个因子,那么这两个因子按照加权合并,就形成了一个指标,通过对这一个指标进行排序,就可以得到上市公司的排名。下面是代码实现 :
# 计算权重 lambdas <- eigen(factor.result$correlation)$value # 就是特指值所占的比例 (w <- lambdas[1:2]/sum(lambdas[1:2])) 0. 0. #计算因子得分 score <- factor.result$scores eva <- score %*% w # 进行排序 eva [,1] [1,] 0. [2,] -0. [3,] -0. [4,] -0. [5,] -0. [6,] -0. [7,] -0. [8,] -0. [9,] 0. [10,] 0.结论
本节带领大家了解了一下,因子分析。通过因子分析主要发掘变量背后存在的潜变量。并且提到了主成分分析与因子分析的不同,主成分分析主要是想寻找原始特征的一个线性组合。这个组合方差要最大。方差最大保证了主要成分的提取。为了计算方便,提出了一些假设,使得主成分分析成为了一个约束优化问题。而因子分析呢,是从假设开始入手,假设原始特征是由于因子的影响产生的,因此可以写出,从这个表达式逐步进行假设求解。当然呢,主成分分析和因子分析有相似的地方,主要就是求解过程中,都很巧妙地和特征值,特征向量挂起关系。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/228245.html原文链接:https://javaforall.net

![mac navicat15 激活码[最新免费获取]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
