
一、Anchor-based的缺点
- Anchor的设计非常重要,需要小心的调整超参数,以SSD、YOLOV2、V3等为例,超参数的选择对最终结果影响盛大
- 即使仔细的设计了超参数,也难以所有形状的目标
- 为了取得较好的召回率,一般需要选取大量的anchor,再结合FPN结构,正负样本就多了,现存消耗也就比较大
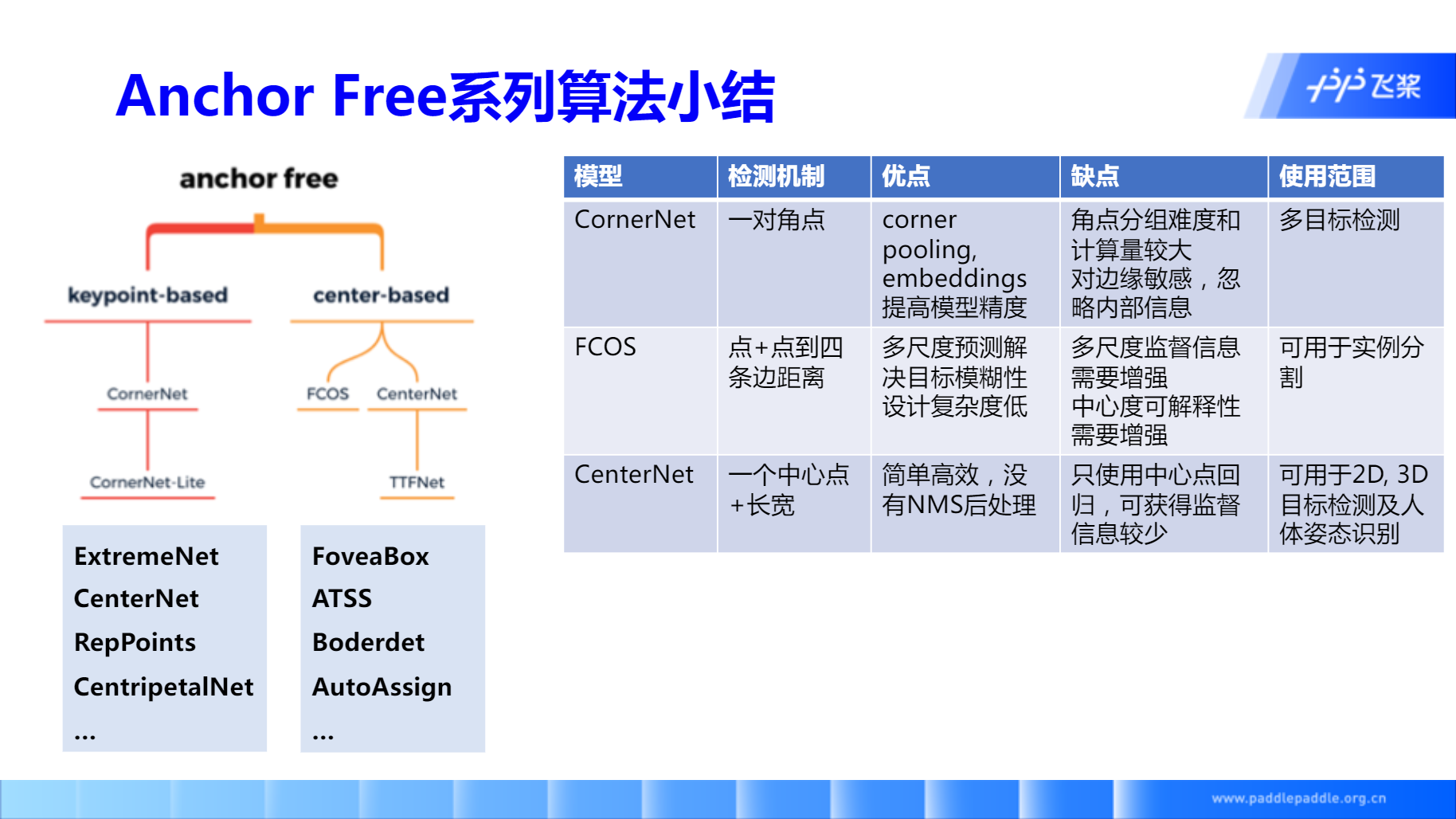
基于以上问题,作者在CornerNet、DenseBox等Anchor-Free后,提出了FCOS。
二、FCOS算法框架
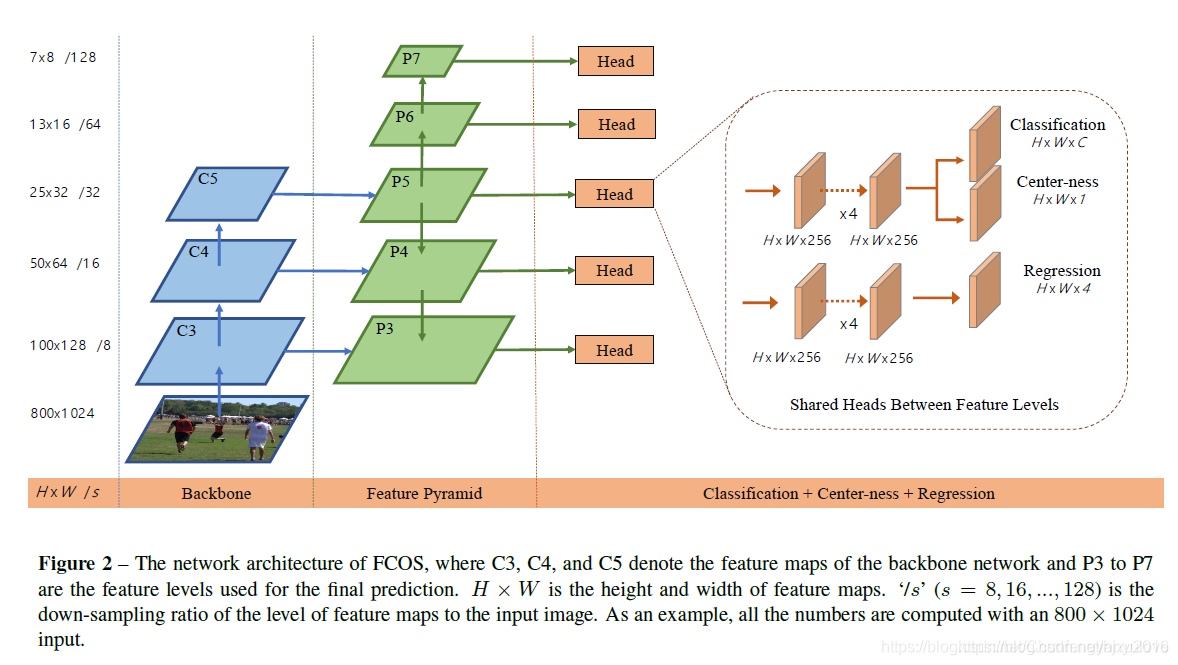

backbone是一个3层的卷积网络(对应图中C3,C4,C5),Pyramid特征金字塔构建完成P3-P7(可自行选择)每个金字塔层对应一个预测头(Head)。
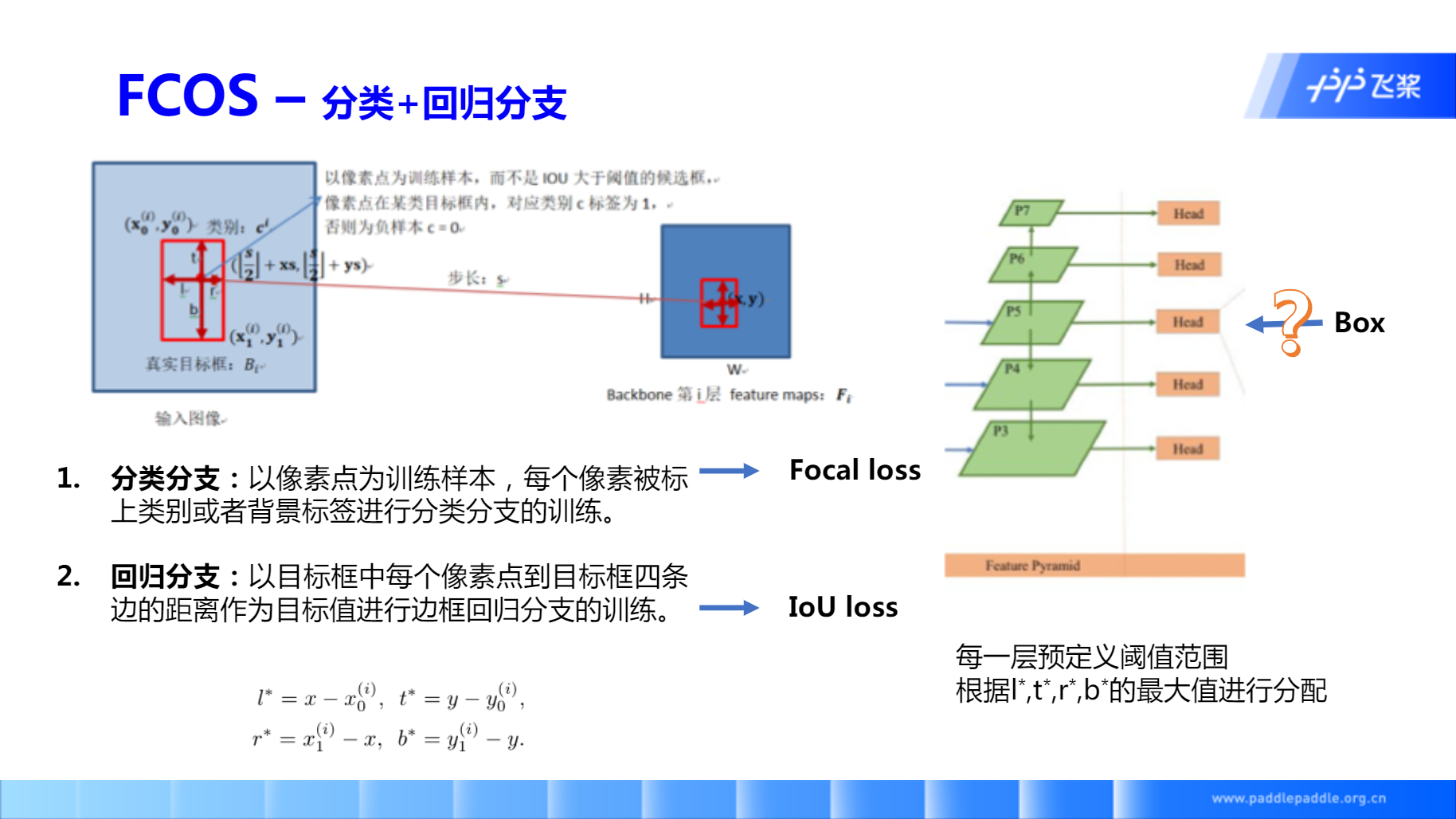
其中Head层分为3个预测分支,1个分类得分(HWC) + 1个位置回归(HW4)+ 1个Center-ness(过滤误检框HW1), C指类别数,H和W为特征图谱的大小。
- Classification采用的是多次二类分类器(C binary
classifier),通俗的将,就是每个特征图后,接一个sigmoid,然后再用focal
loss损失。(Yolov3的分类器也是从softMax转到多次sigmoid) - Regression输出4维向量,分别对应点到上下左右边的距离,训练的时候,loss采用IOU loss

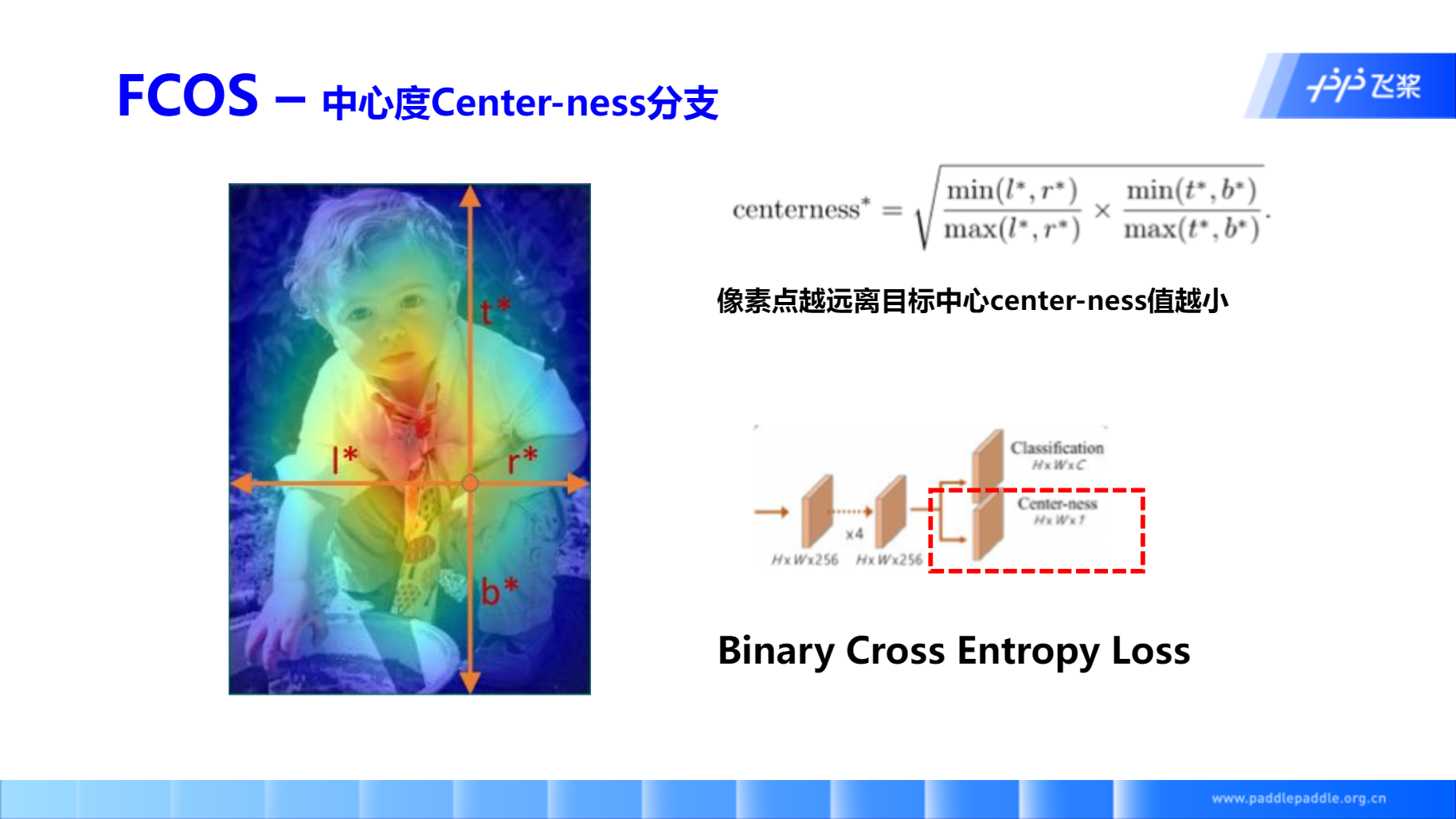
- Center-ness层的引入可以进一步降低目标的误检测 主要目标就是找到目标的中心点,即离目标中心越近,输出值越大,反之越小。
中心点目标定义如下,可见最中心的点的centerness为1,距离越远的点,centerness的值越小。

损失函数采用 BCE loss,并且增加在回归损失和分类损失后。
三、FCOS的后处理

- 网络的输出 Classification 乘 center-ness计算出中心点得分。
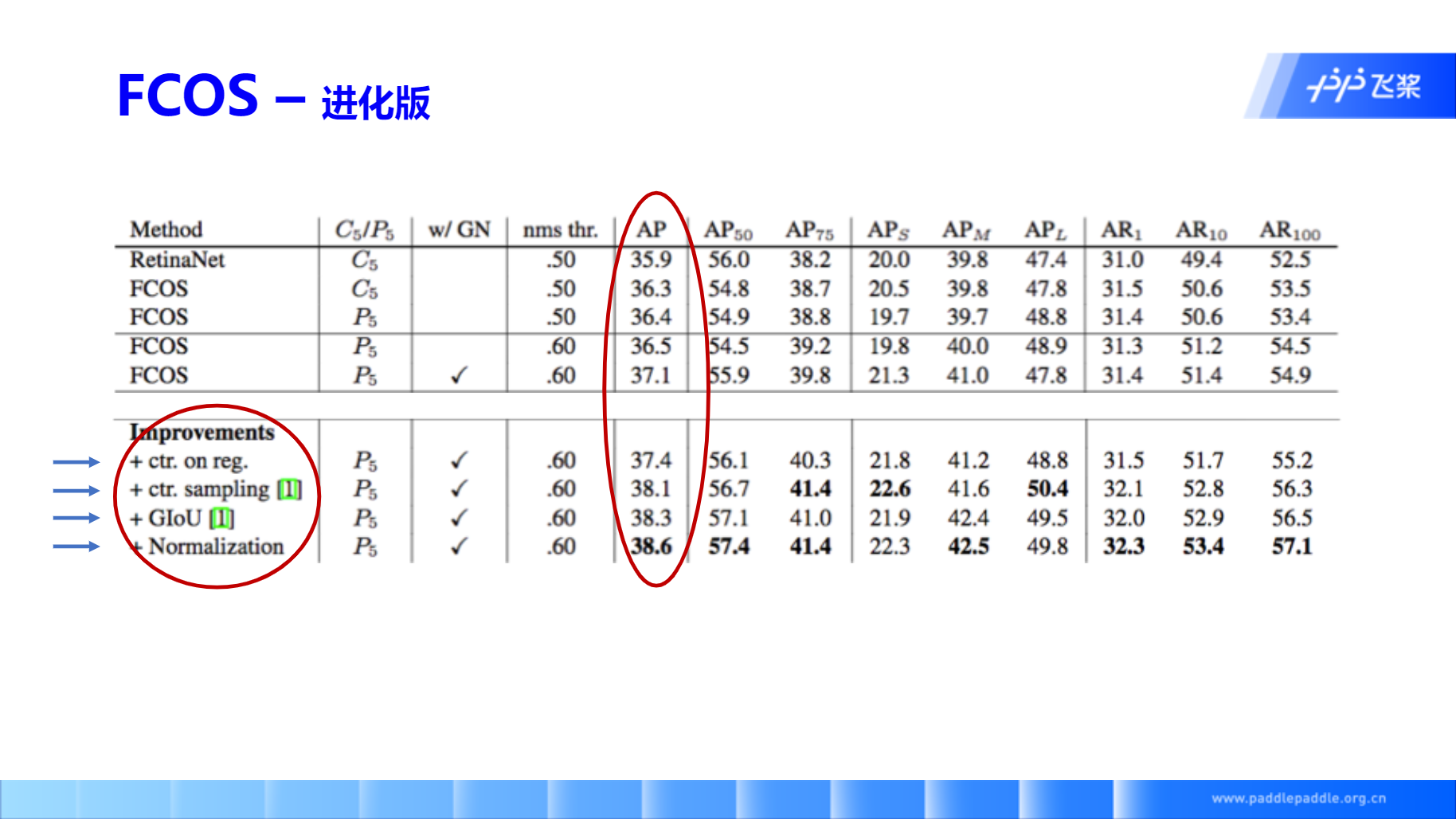
- center-ness的值离检测框中心点越远,值就越低,所以这一步可以过滤一部分误检框,作者选择分类得分大于0.05的作为正样本。也就是乘center-ness值后,越远离中心点的框,得分就越来越低,再接上NMS,可以获取和Anchor-Based不分高下。
附飞桨课件




版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/228274.html原文链接:https://javaforall.net


