
Senet的优点
senet的优点在于增加少量的参数便可以一定程度的提高模型的准确率,是第一个在成型的模型基础之上建立的策略,创新点非常的好,很适合自己创作新模型刷高准确率的一种方法。
Senet的结构


本文的代码讲解是以resnet50讲解,上图便是senet的结构,应用于已经构造完成的resnet模型,只不过在加上了一层se结构的卷积。se结构是在特征图最后进行的,out_channels,作为输入,然后经历整个se结构的卷积处理,这种压缩在膨胀的过程可以看做是不同层特征图数据交融,原本进行1X1的卷积就可以加强非线性和跨通道的信息交互。
Se结构代码
self.se = nn.Sequential( nn.AdaptiveAvgPool2d((1,1)), nn.Conv2d(filter3,filter3//16,kernel_size=1), nn.ReLU(), nn.Conv2d(filter3//16,filter3,kernel_size=1), nn.Sigmoid() ) 整体结构

SE-resnet-50基本跟resnet-50没有变化,唯一变化就是加上了se这个结构,可以参考我之前写的resnet讲解对比学习,代码也基本相同。卷积的重复利用,所以写成一个板块
class Block(nn.Module): def __init__(self, in_channels, filters, stride=1, is_1x1conv=False): super(Block, self).__init__() filter1, filter2, filter3 = filters self.is_1x1conv = is_1x1conv self.relu = nn.ReLU(inplace=True) self.conv1 = nn.Sequential( nn.Conv2d(in_channels, filter1, kernel_size=1, stride=stride,bias=False), nn.BatchNorm2d(filter1), nn.ReLU() ) self.conv2 = nn.Sequential( nn.Conv2d(filter1, filter2, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(filter2), nn.ReLU() ) self.conv3 = nn.Sequential( nn.Conv2d(filter2, filter3, kernel_size=1, stride=1, bias=False), nn.BatchNorm2d(filter3), ) if is_1x1conv: self.shortcut = nn.Sequential( nn.Conv2d(in_channels, filter3, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(filter3) ) self.se = nn.Sequential( nn.AdaptiveAvgPool2d((1,1)), nn.Conv2d(filter3,filter3//16,kernel_size=1), nn.ReLU(), nn.Conv2d(filter3//16,filter3,kernel_size=1), nn.Sigmoid() ) def forward(self, x): x_shortcut = x x1 = self.conv1(x) x1 = self.conv2(x1) x1 = self.conv3(x1) x2 = self.se(x1) x1 = x1*x2 if self.is_1x1conv: x_shortcut = self.shortcut(x_shortcut) x1 = x1 + x_shortcut x1 = self.relu(x1) return x1 全部代码
import torch import torch.nn as nn class Block(nn.Module): def __init__(self, in_channels, filters, stride=1, is_1x1conv=False): super(Block, self).__init__() filter1, filter2, filter3 = filters self.is_1x1conv = is_1x1conv self.relu = nn.ReLU(inplace=True) self.conv1 = nn.Sequential( nn.Conv2d(in_channels, filter1, kernel_size=1, stride=stride,bias=False), nn.BatchNorm2d(filter1), nn.ReLU() ) self.conv2 = nn.Sequential( nn.Conv2d(filter1, filter2, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(filter2), nn.ReLU() ) self.conv3 = nn.Sequential( nn.Conv2d(filter2, filter3, kernel_size=1, stride=1, bias=False), nn.BatchNorm2d(filter3), ) if is_1x1conv: self.shortcut = nn.Sequential( nn.Conv2d(in_channels, filter3, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(filter3) ) self.se = nn.Sequential( nn.AdaptiveAvgPool2d((1,1)), nn.Conv2d(filter3,filter3//16,kernel_size=1), nn.ReLU(), nn.Conv2d(filter3//16,filter3,kernel_size=1), nn.Sigmoid() ) def forward(self, x): x_shortcut = x x1 = self.conv1(x) x1 = self.conv2(x1) x1 = self.conv3(x1) x2 = self.se(x1) x1 = x1*x2 if self.is_1x1conv: x_shortcut = self.shortcut(x_shortcut) x1 = x1 + x_shortcut x1 = self.relu(x1) return x1 class senet(nn.Module): def __init__(self,cfg): super(senet,self).__init__() classes = cfg['classes'] num = cfg['num'] self.conv1 = nn.Sequential( nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False), nn.BatchNorm2d(64), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1) ) self.conv2 = self._make_layer(64, (64, 64, 256), num[0],1) self.conv3 = self._make_layer(256, (128, 128, 512), num[1], 2) self.conv4 = self._make_layer(512, (256, 256, 1024), num[2], 2) self.conv5 = self._make_layer(1024, (512, 512, 2048), num[3], 2) self.global_average_pool = nn.AdaptiveAvgPool2d((1, 1)) self.fc = nn.Sequential( nn.Linear(2048,classes) ) def forward(self, x): x = self.conv1(x) x = self.conv2(x) x = self.conv3(x) x = self.conv4(x) x = self.conv5(x) x = self.global_average_pool(x) x = torch.flatten(x, 1) x = self.fc(x) return x def _make_layer(self,in_channels, filters, num, stride=1): layers = [] block_1 = Block(in_channels, filters, stride=stride, is_1x1conv=True) layers.append(block_1) for i in range(1, num): layers.append(Block(filters[2], filters, stride=1, is_1x1conv=False)) return nn.Sequential(*layers) def Senet(): cfg = {
'num':(3,4,6,3), 'classes': (10) } return senet(cfg) net = Senet() x = torch.rand((10, 3, 224, 224)) for name,layer in net.named_children(): if name != "fc": x = layer(x) print(name, 'output shaoe:', x.shape) else: x = x.view(x.size(0), -1) x = layer(x) print(name, 'output shaoe:', x.shape) 训练结果展示
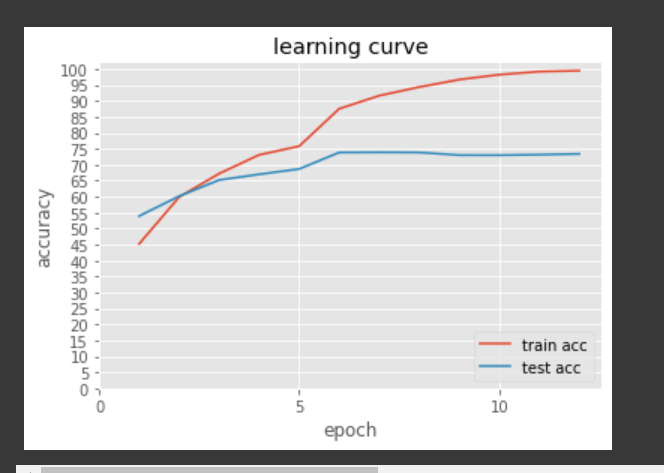
可直接运行的全部代码
import torch from torch import nn import torch import torch.nn as nn import torch import torch.nn as nn class Block(nn.Module): def __init__(self, in_channels, filters, stride=1, is_1x1conv=False): super(Block, self).__init__() filter1, filter2, filter3 = filters self.is_1x1conv = is_1x1conv self.relu = nn.ReLU(inplace=True) self.conv1 = nn.Sequential( nn.Conv2d(in_channels, filter1, kernel_size=1, stride=stride,bias=False), nn.BatchNorm2d(filter1), nn.ReLU() ) self.conv2 = nn.Sequential( nn.Conv2d(filter1, filter2, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(filter2), nn.ReLU() ) self.conv3 = nn.Sequential( nn.Conv2d(filter2, filter3, kernel_size=1, stride=1, bias=False), nn.BatchNorm2d(filter3), ) if is_1x1conv: self.shortcut = nn.Sequential( nn.Conv2d(in_channels, filter3, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(filter3) ) self.se = nn.Sequential( nn.AdaptiveAvgPool2d((1,1)), nn.Conv2d(filter3,filter3//16,kernel_size=1), nn.ReLU(), nn.Conv2d(filter3//16,filter3,kernel_size=1), nn.Sigmoid() ) def forward(self, x): x_shortcut = x x1 = self.conv1(x) x1 = self.conv2(x1) x1 = self.conv3(x1) x2 = self.se(x1) x1 = x1*x2 if self.is_1x1conv: x_shortcut = self.shortcut(x_shortcut) x1 = x1 + x_shortcut x1 = self.relu(x1) return x1 class senet(nn.Module): def __init__(self,cfg): super(senet,self).__init__() classes = cfg['classes'] num = cfg['num'] self.conv1 = nn.Sequential( nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False), nn.BatchNorm2d(64), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1) ) self.conv2 = self._make_layer(64, (64, 64, 256), num[0],1) self.conv3 = self._make_layer(256, (128, 128, 512), num[1], 2) self.conv4 = self._make_layer(512, (256, 256, 1024), num[2], 2) self.conv5 = self._make_layer(1024, (512, 512, 2048), num[3], 2) self.global_average_pool = nn.AdaptiveAvgPool2d((1, 1)) self.fc = nn.Sequential( nn.Linear(2048,classes) ) def forward(self, x): x = self.conv1(x) x = self.conv2(x) x = self.conv3(x) x = self.conv4(x) x = self.conv5(x) x = self.global_average_pool(x) x = torch.flatten(x, 1) x = self.fc(x) return x def _make_layer(self,in_channels, filters, num, stride=1): layers = [] block_1 = Block(in_channels, filters, stride=stride, is_1x1conv=True) layers.append(block_1) for i in range(1, num): layers.append(Block(filters[2], filters, stride=1, is_1x1conv=False)) return nn.Sequential(*layers) def Senet(): cfg = {
'num':(3,4,6,3), 'classes': (10) } return senet(cfg) import time import torch import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt def load_dataset(batch_size): train_set = torchvision.datasets.CIFAR10( root="data/cifar-10", train=True, download=True, transform=transforms.ToTensor() ) test_set = torchvision.datasets.CIFAR10( root="data/cifar-10", train=False, download=True, transform=transforms.ToTensor() ) train_iter = torch.utils.data.DataLoader( train_set, batch_size=batch_size, shuffle=True, num_workers=4 ) test_iter = torch.utils.data.DataLoader( test_set, batch_size=batch_size, shuffle=True, num_workers=4 ) return train_iter, test_iter def train(net, train_iter, criterion, optimizer, num_epochs, device, num_print, lr_scheduler=None, test_iter=None): net.train() record_train = list() record_test = list() for epoch in range(num_epochs): print("========== epoch: [{}/{}] ==========".format(epoch + 1, num_epochs)) total, correct, train_loss = 0, 0, 0 start = time.time() for i, (X, y) in enumerate(train_iter): X, y = X.to(device), y.to(device) output = net(X) loss = criterion(output, y) optimizer.zero_grad() loss.backward() optimizer.step() train_loss += loss.item() total += y.size(0) correct += (output.argmax(dim=1) == y).sum().item() train_acc = 100.0 * correct / total if (i + 1) % num_print == 0: print("step: [{}/{}], train_loss: {:.3f} | train_acc: {:6.3f}% | lr: {:.6f}" \ .format(i + 1, len(train_iter), train_loss / (i + 1), \ train_acc, get_cur_lr(optimizer))) if lr_scheduler is not None: lr_scheduler.step() print("--- cost time: {:.4f}s ---".format(time.time() - start)) if test_iter is not None: record_test.append(test(net, test_iter, criterion, device)) record_train.append(train_acc) return record_train, record_test def test(net, test_iter, criterion, device): total, correct = 0, 0 net.eval() with torch.no_grad(): print("* test *") for X, y in test_iter: X, y = X.to(device), y.to(device) output = net(X) loss = criterion(output, y) total += y.size(0) correct += (output.argmax(dim=1) == y).sum().item() test_acc = 100.0 * correct / total print("test_loss: {:.3f} | test_acc: {:6.3f}%"\ .format(loss.item(), test_acc)) print("\n") net.train() return test_acc def get_cur_lr(optimizer): for param_group in optimizer.param_groups: return param_group['lr'] def learning_curve(record_train, record_test=None): plt.style.use("ggplot") plt.plot(range(1, len(record_train) + 1), record_train, label="train acc") if record_test is not None: plt.plot(range(1, len(record_test) + 1), record_test, label="test acc") plt.legend(loc=4) plt.title("learning curve") plt.xticks(range(0, len(record_train) + 1, 5)) plt.yticks(range(0, 101, 5)) plt.xlabel("epoch") plt.ylabel("accuracy") plt.show() import torch.optim as optim BATCH_SIZE = 128 NUM_EPOCHS = 12 NUM_CLASSES = 10 LEARNING_RATE = 0.01 MOMENTUM = 0.9 WEIGHT_DECAY = 0.0005 NUM_PRINT = 100 DEVICE = "cuda" if torch.cuda.is_available() else "cpu" def main(): net = net = Senet() net = net.to(DEVICE) train_iter, test_iter = load_dataset(BATCH_SIZE) criterion = nn.CrossEntropyLoss() optimizer = optim.SGD( net.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM, weight_decay=WEIGHT_DECAY, nesterov=True ) lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1) record_train, record_test = train(net, train_iter, criterion, optimizer, \ NUM_EPOCHS, DEVICE, NUM_PRINT, lr_scheduler, test_iter) learning_curve(record_train, record_test) if __name__ == '__main__': main() 本文写的并不全面,se结构有好几种,大家可以看论文类比写出其他的结构
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/228543.html原文链接:https://javaforall.net

![Spring Cloud的架构[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
