
前言
if score < 60: print("不及格") elif score < 70: print("及格") elif score < 80: print("中等") elif score < 90: print("良好") else: print("优秀") | 分数 | 0~59 | 60~69 | 70~79 | 80~89 | 90~100 |
|---|---|---|---|---|---|
| 所占比例 | 5% | 15% | 40% | 30% | 10% |
哈夫曼树(最优二叉树)
定义与原理
树的路径长度
从树中一个节点到另一个节点之间的分支构成两个节点之间的路径,路径上的分支数目称为路径长度。
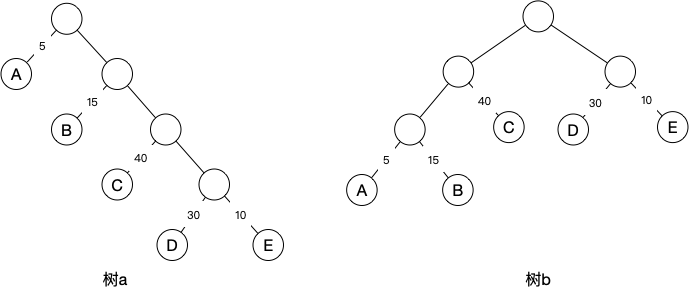

树a的根节点到D节点,路径长度为4。树b的根节点到节点D长度为2。树的路径长度为根节点到各节点的路径长度之和。 树a的树路径长度为1+1+2+2+3+3+4+4=20。树b的树路径长度为1+2+3+3+2+1+2+2=16。
带权路径长度
树的带权路径长度记为WPL(Weighted Path Length of Tree)
节点的带权路径长度为根节点到该节点路径长度与该节点的权的乘积。树的带权路径长度为各叶子节点的带权路径长度之和。
树a的WPL=1×5+2×15+3×40+4×30+4×10=315
树b的WPL=3×5+3×15+2×40+2×30+2×10=220
树的WPL越小,那么树就越优。
构造哈夫曼树
- 将所有权重节点按照权重由小到大进行排序,即:A5,E10,B15,D30,C40
- 将最左的两个节点按照左小右大作为新节点N1的左右两个子节点。N1的权重=5+10=15。
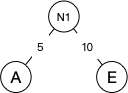
- 将N1替换序列的A和E并加入。重复2步骤,将N1和B作为新节点N2的两个子节点。N2的权重=15+15=30。
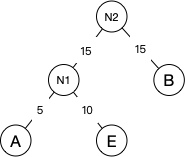
- 然后继续重复2步骤,将N2替换N1和B加入到序列中,并将N2与D作为新节点N3的两个子节点。N3的权重=30+30=60。
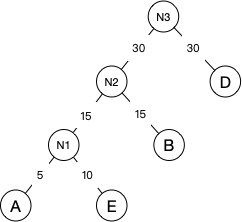
- 然后继续重复2步骤,将N3替换N2和D并加入到序列。将N3和E作为新节点R的两个子节点。因为N3的权重为60,C的权重为40,所以C作为R的左子节点,N3作为右子节点。并且R已经是根节点了,所以最终的哈夫曼树就如下图:
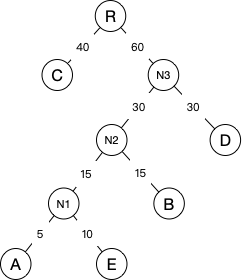
该树的WPL=1×40+2×30+3×15+4×10+4×5=205
比前面的树b的WPL=225还要少15,所以该树就是最优的哈夫曼树了。
我们对创建哈夫曼树步骤总结如下:
- 将给定的n个权值构成n棵只有一个节点的树,并根据权值由小到大进行排序。
- 取最左遍权值最小的两棵树作为左右子树构成一颗新二叉树,新二叉树的权值为两棵字数的权值和。
- 将2步骤构造的新树的两个子树删除,将构造的新树放入序列的最左边。
- 重复2、3步骤,直到所有树合并为一棵树为止。最终的树就是哈夫曼树,也就是最优二叉树。
哈夫曼树生成代码
代码用Python3实现如下:
import functools class TreeNode: def __init__(self, data, weight) -> None: self.data = data # 数据 self.weight = weight # type: int #权重 self.left = None # 左子节点 self.right = None # 右子节点 def __str__(self) -> str: return self.data def cmp(a, b): """ 排序 """ if a.weight > b.weight: return 1 elif a.weight < b.weight: return -1 else: return 0 def gen_huffman_tree(_trees, depth=0): """ 构建哈夫曼树 :param depth: 深度 :param _trees: 树集 """ if depth == 0: print('对' + ','.join([str(item) for item in tree]) + '树集生成哈夫曼树。数据|权重') depth = depth + 1 # 深度+1 if len(_trees) == 1: return _trees[0] _trees = sorted(_trees, key=functools.cmp_to_key(cmp)) left_sub = _trees[0] right_sub = _trees[1] new_node_weight = left_sub.weight + right_sub.weight # 新树权重 # 构建新树 new_node = TreeNode('N%s|%s' % (str(depth), str(new_node_weight)), new_node_weight) new_node.left = left_sub new_node.right = right_sub # 删除最左两个树 _trees.remove(left_sub) _trees.remove(right_sub) # 新树插入到最左序列 _trees.insert(0, new_node) # 递归构建下一个树,直到只剩下一棵树 return gen_huffman_tree(_trees, depth) def layer_order_traverse(_layer_nodes): """ 按层遍历 :param _layer_nodes: 当前层节点集合 :type _layer_nodes: list """ if _layer_nodes is None or len(_layer_nodes) == 0: return _childs = [] # 子集 for _node in _layer_nodes: # 遍历传入的当前层所有节点 print(_node.data, end=',') if _node.left: _childs.append(_node.left) if _node.right: _childs.append(_node.right) layer_order_traverse(_childs) if __name__ == '__main__': tree = [ TreeNode('A|5', 5), TreeNode('B|15', 15), TreeNode('C|40', 40), TreeNode('D|30', 30), TreeNode('E|10', 10) ] huffman_tree = gen_huffman_tree(tree) print('按层遍历哈夫曼树:', end='') layer_order_traverse([huffman_tree]) print('\b' * 1, end='') 对A|5,B|15,C|40,D|30,E|10树集生成哈夫曼树。数据|权重 按层遍历哈夫曼树:N4|100,C|40,N3|60,N2|30,D|30,N1|15,B|15,A|5,E|10 版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/228932.html原文链接:https://javaforall.net


