
此算法的基础是以用户对某种抉择的二项性为基础,每条可记录的数据都是“0-1”的独立事件,符合泊松分布,于是该类数据很容易归类于二项分布里。二项分布计算置信区间有多种计算公式,最常见的是“正太区间”(Normal approximation interval),但它只适用于样本较多的情况(np > 5 且 n(1 − p) > 5),对于小样本,它的准确性很差。Wilson算法正是解决了小样本的准确性问题,Wilson算法的输入是置信度,输出是置信区间,如果要做数据排序对比,则可以选择置信区间的下限数据。
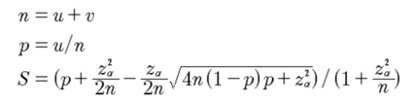

S为威尔逊置信区间算法公式,其中n为样本总数,u为正例数,v为反例数,z表示对应某个置信水平的统计量,一般情况下,在95%的置信水平下,z统计量的值为1.96。举个简单例子,给某个人投票,80票赞成,20票反对,则n为100,u为80,v为20。
正态分布的分位数表:

算法性质:
- 性质:得分S的范围是[0,1),效果:已经归一化,适合排序
- 性质:当正例数u为0时,p为0,得分S为0;效果:没有好评,分数最低;
- 性质:当负例数v为0时,p为1,退化为1/(1 + z^2 / n),得分S永远小于1;效果:分数具有永久可比性;
- 性质:当p不变时,n越大,分子减少速度小于分母减少速度,得分S越多,反之亦然;效果:好评率p相同,实例总数n越多,得分S越多;
- 性质:当n趋于无穷大时,退化为p,得分S由p决定;效果:当评论总数n越多时,好评率p带给得分S的提升越明显;
- 性质:当分位数z越大时,总数n越重要,好评率p越不重要,反之亦然;效果:z越大,评论总数n越重要,区分度低;z越小,好评率p越重要;
Python代码实现:
def wilson_score(pos, total, p_z=0.8): """ 威尔逊得分计算函数 :param pos: 正例数 :param total: 总数 :param p_z: 正太分布的分位数 :return: 威尔逊得分 """ pos_rat = pos * 1. / total * 1. # 正例比率 score = (pos_rat + (np.square(p_z) / (2. * total)) - ((p_z / (2. * total)) * np.sqrt(4. * total * (1. - pos_rat) * pos_rat + np.square(p_z)))) / \ (1. + np.square(p_z) / total) return score应用测试:

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/228979.html原文链接:https://javaforall.net

![r语言熵权法求权重(真实案例完整流程)[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
