
Pattern类定义
public final class Pattern extends Object implementsSerializable正则表达式的编译表示形式。用于编译正则表达式后创建一个匹配模式。
指定为字符串的正则表达式必须首先被编译为此类的实例。然后,可将得到的模式用于创建Matcher对象,依照正则表达式,该对象可以与任意字符序列匹配。执行匹配所涉及的所有状态都驻留在匹配器中,所以多个匹配器可以共享同一模式。
因此,典型的调用顺序是:
Pattern p =Pattern.compile(“a*b”);
Matcher m =p.matcher(“aaaaab”);
boolean b = m.matches();
在仅使用一次正则表达式时,可以方便地通过此类定义matches方法。此方法编译表达式并在单个调用中将输入序列与其匹配。语句:
boolean b =Pattern.matches(“a*b”, “aaaaab”);
等效于上面的三个语句,尽管对于重复的匹配而言它效率不高,因为它不允许重用已编译的模式。
此类的实例是不可变的,可供多个并发线程安全使用。Matcher类的实例用于此目的则不安全。
Pattern类方法详解
1、Pattern complie(String regex):编译正则表达式,并创建Pattern类。
由于Pattern的构造函数是私有的,不可以直接创建,所以通过静态的简单工厂方法compile(String regex)方法来创建,将给定的正则表达式编译并赋予给Pattern类。
2、String pattern():返回正则表达式的字符串形式。
其实就是返回Pattern.complile(Stringregex)的regex参数。示例如下:
String regex =”\\?|\\*”;
Pattern pattern= Pattern.compile(regex);
StringpatternStr = pattern.pattern();//返回\?\*
3、Pattern compile(String regex, int flags)。
方法功能和compile(Stringregex)相同,不过增加了flag参数,flag参数用来控制正则表达式的匹配行为,可取值范围如下:
Pattern.CANON_EQ:启用规范等价。当且仅当两个字符的“正规分解(canonicaldecomposition)”都完全相同的情况下,才认定匹配。默认情况下,不考虑“规范相等性(canonical equivalence)”。
Pattern.CASE_INSENSITIVE:启用不区分大小写的匹配。默认情况下,大小写不敏感的匹配只适用于US-ASCII字符集。这个标志能让表达式忽略大小写进行匹配,要想对Unicode字符进行大小不敏感的匹配,只要将UNICODE_CASE与这个标志合起来就行了。
Pattern.COMMENTS:模式中允许空白和注释。在这种模式下,匹配时会忽略(正则表达式里的)空格字符(不是指表达式里的“\s”,而是指表达式里的空格,tab,回车之类)。注释从#开始,一直到这行结束。可以通过嵌入式的标志来启用Unix行模式。
Pattern.DOTALL:启用dotall模式。在这种模式下,表达式‘.’可以匹配任意字符,包括表示一行的结束符。默认情况下,表达式‘.’不匹配行的结束符。
Pattern.LITERAL:启用模式的字面值解析。
Pattern.MULTILINE:启用多行模式。在这种模式下,‘\^’和‘$’分别匹配一行的开始和结束。此外,‘^’仍然匹配字符串的开始,‘$’也匹配字符串的结束。默认情况下,这两个表达式仅仅匹配字符串的开始和结束。
Pattern.UNICODE_CASE:启用Unicode感知的大小写折叠。在这个模式下,如果你还启用了CASE_INSENSITIVE标志,那么它会对Unicode字符进行大小写不敏感的匹配。默认情况下,大小写不敏感的匹配只适用于US-ASCII字符集。
Pattern.UNIX_LINES: 启用Unix行模式。在这个模式下,只有‘\n’才被认作一行的中止,并且与‘.’、‘^’、以及‘$’进行匹配。
4、int flags():返回当前Pattern的匹配flag参数。
5、String[] split(CharSequence input)。
Pattern有一个split(CharSequenceinput)方法,用于分隔字符串,并返回一个String[]。此外String[] split(CharSequence input, int limit)功能和String[]split(CharSequence input)相同,增加参数limit目的在于要指定分割的段数。
6、static boolean matches(String regex, CharSequenceinput)。
是一个静态方法,用于快速匹配字符串,该方法适合用于只匹配一次,且匹配全部字符串。方法编译给定的正则表达式并且对输入的字串以该正则表达式为模式开展匹配,该方法只进行一次匹配工作,并不需要生成一个Matcher实例。
7、Matcher matcher(CharSequence input)。
Pattern.matcher(CharSequenceinput)返回一个Matcher对象。Matcher类的构造方法也是私有的,不能随意创建,只能通过Pattern.matcher(CharSequence input)方法得到该类的实例。Pattern类只能做一些简单的匹配操作,要想得到更强更便捷的正则匹配操作,那就需要将Pattern与Matcher一起合作。Matcher类提供了对正则表达式的分组支持,以及对正则表达式的多次匹配支持。
Java代码示例:
Pattern p = Pattern.compile(“\\d+”);
Matcher m = p.matcher(“22bb23”);
// 返回p也就是返回该Matcher对象是由哪个Pattern对象的创建的
m.pattern();
Pattern类使用示例:
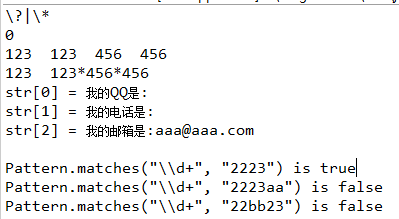
package com.zxt.regex; import java.util.regex.Pattern; public classPatternTest { public static void main(String[] args) { // 使用Pattern.compile方法编译一个正则表达式,创建一个匹配模式 Patternpattern = Pattern.compile("\\?|\\*"); // pattern()函数返回正则表达式的字符串形式返回\?\* StringpatternStr = pattern.pattern(); System.out.println(patternStr); // flags()返回当前Pattern的匹配flag参数,这里并没有定义 int flag = pattern.flags(); System.out.println(flag); // split方法对字符串进行分割 // 123 123 456 456 String[]splitStrs = pattern.split("123?123*456*456"); for (int i = 0; i < splitStrs.length; i++) { System.out.print(splitStrs[i] + " "); } System.out.println(); // 123 123*456*456 String[]splitStrs2 = pattern.split("123?123*456*456",2); for (int i = 0; i < splitStrs2.length; i++) { System.out.print(splitStrs2[i] + " "); } System.out.println(); Patternp = Pattern.compile("\\d+"); String[]str = p.split("我的是:我的电话是:0我的邮箱是:"); for (int i = 0; i < str.length; i++) { System.out.printf("str[%d] = %s\n",i, str[i]); } System.out.println(); // Pattern.matches用给定的模式对字符串进行一次匹配,(需要全匹配时才返回true) System.out.println("Pattern.matches(\"\\\\d+\",\"2223\") is " + Pattern.matches("\\d+", "2223")); // 返回false,需要匹配到所有字符串才能返回true,这里aa不能匹配到 System.out.println("Pattern.matches(\"\\\\d+\", \"2223aa\")is " + Pattern.matches("\\d+", "2223aa")); // 返回false,需要匹配到所有字符串才能返回true,这里bb不能匹配到 System.out.println("Pattern.matches(\"\\\\d+\",\"22bb23\") is " + Pattern.matches("\\d+", "22bb23")); } }
Matcher类定义
public final class Matcher extends Object implementsMatchResult通过调用模式(Pattern)的matcher方法从模式创建匹配器。创建匹配器后,可以使用它执行三种不同的匹配操作:
1、matches方法尝试将整个输入序列与该模式匹配。
2、lookingAt尝试将输入序列从头开始与该模式匹配。
3、find方法扫描输入序列以查找与该模式匹配的下一个子序列。
每个方法都返回一个表示成功或失败的布尔值。通过查询匹配器的状态可以获取关于成功匹配的更多信息。
匹配器在其输入的子集(称为区域)中查找匹配项。默认情况下,此区域包含全部的匹配器输入。可通过region方法修改区域,通过regionStart和regionEnd方法查询区域。区域边界与某些模式构造交互的方式是可以更改的。
此类还定义使用新字符串替换匹配子序列的方法,需要时,可以从匹配结果计算出新字符串的内容。可以先后使用appendReplacement和appendTail方法将结果收集到现有的字符串缓冲区,或者使用更加便捷的replaceAll方法创建一个可以在其中替换输入序列中每个匹配子序列的字符串。
匹配器的显式状态包括最近成功匹配的开始和结束索引。它还包括模式中每个捕获组捕获的输入子序列的开始和结束索引以及该子序列的总数。出于方便的考虑,还提供了以字符串的形式返回这些已捕获子序列的方法。
匹配器的显式状态最初是未定义的;在成功匹配导致IllegalStateException抛出之前尝试查询其中的任何部分。每个匹配操作都将重新计算匹配器的显式状态。匹配器的隐式状态包括输入字符序列和添加位置,添加位置最初是零,然后由appendReplacement方法更新。
可以通过调用匹配器的reset()方法来显式重置匹配器,如果需要新输入序列,则调用其reset(CharSequence)方法。重置匹配器将放弃其显式状态信息并将添加位置设置为零。
此类的实例用于多个并发线程是不安全的。
Matcher类方法详解
1、Matcher类提供了三个匹配操作方法,三个方法均返回boolean类型,当匹配到时返回true,没匹配到则返回false。
boolean matches()最常用方法:尝试对整个目标字符展开匹配检测,也就是只有整个目标字符串完全匹配时才返回真值。
boolean lookingAt()对前面的字符串进行匹配,只有匹配到的字符串在最前面才会返回true。
boolean find():对字符串进行匹配,匹配到的字符串可以在任何位置。
2、返回匹配器的显示状态:intstart():返回当前匹配到的字符串在原目标字符串中的位置;int end():返回当前匹配的字符串的最后一个字符在原目标字符串中的索引位置;String group():返回匹配到的子字符串。
3、int start(),int end(),int group()均有一个重载方法,它们分别是int start(int i),int end(int i),int group(int i)专用于分组操作,Mathcer类还有一个groupCount()用于返回有多少组。
4、Matcher类同时提供了四个将匹配子串替换成指定字符串的方法:
1)、String replaceAll(Stringreplacement):将目标字符串里与既有模式相匹配的子串全部替换为指定的字符串。
2)、String replaceFirst(Stringreplacement):将目标字符串里第一个与既有模式相匹配的子串替换为指定的字符串。
3)、还有两个方法Matcher appendReplacement(StringBuffersb, String replacement) 和StringBufferappendTail(StringBuffer sb)也很重要,appendReplacement允许直接将匹配的字符串保存在另一个StringBuffer中并且是渐进式匹配,并不是只匹配一次或匹配全部,而appendTail则是将未匹配到的余下的字符串添加到StringBuffer中。
5、其他一些方法:例如Matcherreset():重设该Matcher对象。
Matcher reset(CharSequence input):重设该Matcher对象并且指定一个新的目标字符串。
Matcher region(int start, int end):设置此匹配器的区域限制。
Matcher类使用示例:
package com.zxt.regex; import java.util.regex.Matcher;import java.util.regex.Pattern; public classMatcherTest { public static void main(String[] args) { Patternp = Pattern.compile("\\d+"); // matches()对整个字符串进行匹配 // 返回false,因为bb不能被\d+匹配,导致整个字符串匹配未成功。 Matcherm = p.matcher("22bb23"); System.out.println(m.matches()); m = p.matcher("2223"); // 返回true,因为\d+匹配到了整个字符串 System.out.println(m.matches()); // lookingAt()对字符串前缀进行匹配 m = p.matcher("22bb23"); // 返回true,因为\d+匹配到了前面的22 System.out.println(m.lookingAt()); m = p.matcher("aa2223"); // 返回false,因为\d+不能匹配前面的aa System.out.println(m.lookingAt()); // find()对字符串进行匹配,匹配到的字符串可以在任何位置。 m = p.matcher("22bb23"); System.out.println(m.find()); // true m = p.matcher("aa2223"); System.out.println(m.find()); // true m = p.matcher("aabb"); System.out.println(m.find()); // false // 当匹配器匹配失败时,使用返回匹配器状态的方法将出错,例如:m.start(); m = p.matcher("aa2223bb"); System.out.println(m.find()); // true System.out.println(m.start()); // 2 System.out.println(m.end()); // 6 System.out.println(m.group()); // 2223 p = Pattern.compile("([a-z]+)(\\d+)"); m = p.matcher("aaa2223bb"); // 匹配aaa2223 m.find(); // 返回2,因为有2组 System.out.println(m.groupCount()); // 返回0, 返回第一组匹配到的子字符串在字符串中的索引号 System.out.println(m.start(1)); // 返回3 System.out.println(m.start(2)); // 返回3 返回第一组匹配到的子字符串的最后一个字符在字符串中的索引位置. System.out.println(m.end(1)); // 返回2223,返回第二组匹配到的子字符串 System.out.println(m.group(2)); }}应用实例
1、一个简单的邮箱验证小程序
package com.zxt.regex; import java.util.Scanner;import java.util.regex.Matcher;import java.util.regex.Pattern; /* * 一个简单的邮件地址匹配程序 */public classEmailMatch { public static void main(String[] args) throws Exception { Scannersc = new Scanner(System.in); while (sc.hasNext()) { Stringinput = sc.nextLine(); // 检测输入的EMAIL地址是否以非法符号"."或"@"作为起始字符 Patternp = Pattern.compile("^@"); Matcherm = p.matcher(input); if (m.lookingAt()) { System.out.println("EMAIL地址不能以'@'作为起始字符"); } // 检测是否以"www."为起始 p = Pattern.compile("^www."); m = p.matcher(input); if (m.lookingAt()) { System.out.println("EMAIL地址不能以'www.'起始"); } // 检测是否包含非法字符 p = Pattern.compile("[^A-Za-z0-9.@_-~#]+"); m = p.matcher(input); StringBuffersb = new StringBuffer(); boolean result = m.find(); boolean deletedIllegalChars= false; while (result) { // 如果找到了非法字符那么就设下标记 deletedIllegalChars= true; // 如果里面包含非法字符如冒号双引号等,那么就把他们消去,加到SB里面 m.appendReplacement(sb, ""); result = m.find(); } // 此方法从添加位置开始从输入序列读取字符,并将其添加到给定字符串缓冲区。 // 可以在一次或多次调用 appendReplacement 方法后调用它来复制剩余的输入序列。 m.appendTail(sb); if (deletedIllegalChars){ System.out.println("输入的EMAIL地址里包含有冒号、逗号等非法字符,请修改"); System.out.println("您现在的输入为: " + input); System.out.println("修改后合法的地址应类似: " + sb.toString()); } } sc.close(); }}

2、判断身份证:要么是15位,要么是18位,最后一位可以为字母,并写程序提出其中的年月日。
可以使用正则表达式来定义复杂的字符串格式:(\d{17}[0-9a-zA-Z]|\d{14}[0-9a-zA-Z])可以用来判断是否为合法的15位或18位身份证号码。因为15位和18位的身份证号码都是从7位到第12位为身份证为日期类型。这样我们可以设计出更精确的正则模式,提取身份证号中的日期信息。
package com.zxt.regex; import java.util.regex.Matcher;import java.util.regex.Pattern; public classIdentityMatch { public static void main(String[] args) { // 测试是否为合法的身份证号码 String[]id_cards = { "130681198712092019","13068119871209201x","13068119871209201","123456789012345", "12345678901234x","1234567890123"}; // 测试是否为合法身份证的正则表达式 Patternpattern = Pattern.compile("(\\d{17}[0-9a-zA-Z]|\\d{14}[0-9a-zA-Z])"); // 用于提取出生日字符串的正则表达式 Patternpattern1 = Pattern.compile("\\d{6}(\\d{8}).*"); // 用于将生日字符串分解为年月日的正则表达式 Patternpattern2 = Pattern.compile("(\\d{4})(\\d{2})(\\d{2})"); Matchermatcher = pattern.matcher(""); for (int i = 0; i < id_cards.length; i++) { matcher.reset(id_cards[i]); System.out.println(id_cards[i] + " is id cards:" + matcher.matches()); // 如果它是一个合法的身份证号,提取出出生的年月日 if (matcher.matches()) { Matchermatcher1 = pattern1.matcher(id_cards[i]); matcher1.lookingAt(); Stringbirthday = matcher1.group(1); Matchermatcher2 = pattern2.matcher(birthday); if (matcher2.find()) { System.out.println("它对应的出生年月日为:" + matcher2.group(1) + "年" + matcher2.group(2) + "月" +matcher2.group(3) + "日"); } } System.out.println(); } }}

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/229716.html原文链接:https://javaforall.net


