
SSD
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法,截至目前是主要的检测框架之一,相比Faster RCNN有明显的速度优势,相比YOLO又有明显的mAP优势(不过已经被CVPR 2017的YOLO9000超越)。
背景
目标检测主流算法分成两个类型:
(1)two-stage方法:RCNN系列
通过算法产生候选框,然后再对这些候选框进行分类和回归
(2)one-stage方法:yolo和SSD
直接通过主干网络给出类别位置信息,不需要区域生成
特点
SSD网络结构
核心设计理念
模型结构
SSD的模型框架主要由三部分组成,以SSD300为例,有VGG-Base Extra-Layers,Pred-Layers。
主干网络
import torch.nn.init as init import torch import torch.nn as nn import torch.nn.functional as F from torch.autograd import Variable from math import sqrt as sqrt from itertools import product as product base = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M', 512, 512, 512], '512': [], } def vgg(cfg, i, batch_norm=False): layers = [] in_channels = i for v in cfg: if v == 'M': layers += [nn.MaxPool2d(kernel_size=2, stride=2)] elif v == 'C': layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)] else: conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1) if batch_norm: layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)] else: layers += [conv2d, nn.ReLU(inplace=True)] in_channels = v pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6) conv7 = nn.Conv2d(1024, 1024, kernel_size=1) layers += [pool5, conv6, nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)] return layers layers=vgg(base[str(300)], 3) print(nn.Sequential(*layers)) Sequential( (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): ReLU(inplace) (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (3): ReLU(inplace) (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (6): ReLU(inplace) (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (8): ReLU(inplace) (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace) (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (13): ReLU(inplace) (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (15): ReLU(inplace) (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=True) (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (18): ReLU(inplace) (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (20): ReLU(inplace) (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (22): ReLU(inplace) (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (25): ReLU(inplace) (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (27): ReLU(inplace) (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (29): ReLU(inplace) (30): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False) (31): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(6, 6), dilation=(6, 6)) (32): ReLU(inplace) (33): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1)) (34): ReLU(inplace) ) 第一次的特征图输出是在(22)处,一共经历3次池化,所以特征图大小是38*38,之后用进行二次maxpool2d 特征图在最后输出应该是10×10的大小,但最后一层的maxpool2d的stride=1所以特征图大小还是19×19
Sequential( (0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1)) (1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)) (2): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1)) (3): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)) (4): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1)) (5): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1)) (6): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1)) (7): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1)) ) 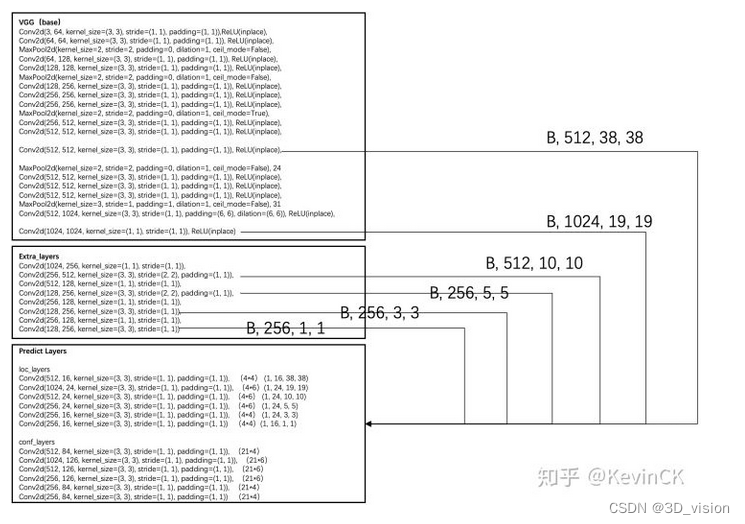

从上图可以看到六个特征图的尺寸:[38, 19, 10, 5, 3, 1],在Predict Layers中可以看到每个特征图中的每个像素点对应的先验框个数为:[4, 6, 6, 6, 4, 4] 。
训练
下载VOC2007,VOC2012数据集进行训练。
数据size为300×300,一共有21个类。
查看官方的mAP为77.7,基本保持了一致。
使用训练后的模型进行推理,推理速度达到了38FPS
结论
优点:
SSD算法的优点应该很明显:运行速度可以和YOLO媲美,检测精度可以和Faster RCNN媲美。
缺点:
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/229774.html原文链接:https://javaforall.net


