
看到研习社有伙伴提问:
其实,这个问题不好回答,也好回答。
一方面,不好回答是因为金融市场分级明显,产品多样化,不同业务场景所需要的风控策略就对应不同,不太好理一套完整的、通用的、标准的说明书;另外,许多部门制定评分卡切分点的策略都是根据经验拍脑袋(我们后面说明)。
另一方面,好回答的原因是金融借贷业务本质相同,核心指标就几个,针对这些业务指标,我们还是可以找到许多通用的评分卡应用流程及大致方案的。
下面,我们就来解决三个问题:
首先,我们回顾下标准评分卡开发流程:
图一:评分卡模型开发流程(图片取材于网络)


图二:标准logistic回归模型开发流程(图片取材于网络)
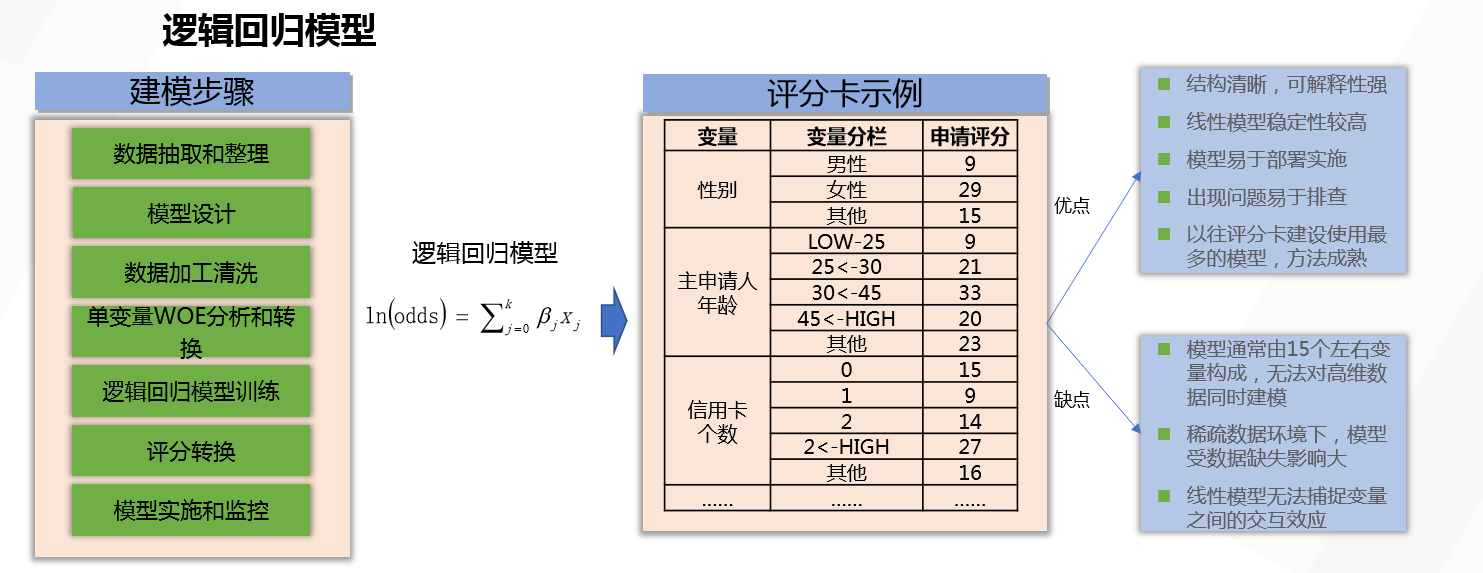
想必小伙伴对模型开发的这套流程已了熟于胸,我们不再缀述。主要来看看使用不同算法得到的结果有哪些?得到的违约概率预测值又是怎么转换为标准score形式的。
一、常见评分卡有哪几种形式?
1)刻度评分卡
①来回顾下logistic函数表达式:
逻辑回归(logistic regression)通过 s i g m o i d sigmoid sigmoid函数 y = 1 / ( 1 + e − z ) y = 1/(1+e^{-z}) y=1/(1+e−z) 将线性回归模型 z = ω T x + b z = \omega ^{T}x+b z=ωTx+b 产生的预测值转换为一个接近0或1的拟合值 y ^ y\hat{} y^
y ^ = 1 1 + e − z y\hat{} = \frac{1}{1+e^{-z}} y^=1+e−z1 = 1 1 + e − ( ω T x + b ) = \frac{1}{1+e^{-(\omega ^{T}x+b)}} =1+e−(ωTx+b)1
上式的 y ^ y\hat{} y^ 可视为事件发生的概率 p ( y = 1 ∣ x ) p(y = 1|x) p(y=1∣x) ,变换后得到:
l n p 1 − p = z = ω T x + b ln\frac{p}{1-p}=z=\omega ^{T}x+b ln1−pp=z=ωTx+b
其中 p 1 − p \frac{p}{1-p} 1−pp 为比率 ( o d d s ) (odds) (odds),即违约概率与正常概率的比值。 l n p 1 − p ln\frac{p}{1-p} ln1−pp 为 l o g i t logit logit 函数,即比率的自然对数。因此,逻辑回归实际上是用比率的自然对数作为因变量的线性回归模型。
l n ( o d d s ) = ω T x + b ln(odds) =\omega ^{T}x+b ln(odds)=ωTx+b
(涉及算法详细推导过程这里不再赘述)
②评分卡设定的分值刻度可以通过将分值表示为比率对数的线性表达式来定义,即可表示为下式:
s c o r e = A − B l n ( o d d s ) score = A − Bln(odds) score=A−Bln(odds)
其中,A和B是常数。式中的负号可以使得违约概率越低,得分越高。通常情况下,这是分值的理想变动方向,即高分值代表低风险,低分值代表高风险。
常数A和B的值可以通过两个假设代入上式计算得到:
通常,我们设当坏好比相同时,基准坏好比率 ( o d d s 0 ) (odds0) (odds0)对应的基准分值 ( p o i n t s 0 ) (points0) (points0)为:
p o i n t s 0 = A − B l n ( o d d s ) points0 = A – Bln(odds) points0=A−Bln(odds)
当坏好比翻倍时,对应的分数 P D O ( P o i n t s t o D o u b l e t h e O d d s ) PDO(Points to Double the Odds) PDO(PointstoDoubletheOdds)为:
p o i n t s 0 − P D O = A − B l n ( 2 o d d s ) points0 – PDO = A – Bln(2odds) points0−PDO=A−Bln(2odds)
联立两方程,可以得到:
B = P D O / l n ( 2 ) B = PDO/ln(2) B=PDO/ln(2)
A = p o i n t s 0 + B l n ( o d d s ) A = points0 + Bln(odds) A=points0+Bln(odds)
S c o r e = 6.78 − 14.43 l o g ( o d d s ) Score = 6.78 – 14.43log(odds) Score=6.78−14.43log(odds)
③分值分配。将逻辑回归公式代入评分卡分值公式,可以得到:
s c o r e = A − B l n ( o d d s ) = A − B ( ω T + b ) = ( A − B b ) − B ω 1 x 1 − B ω 2 x 2 ⋯ − B ω m x m score = A − Bln(odds) = A − B(\omega _{T}+ b) = (A − Bb)− B\omega _{1}x_{1} − B\omega _{2}x_{2} ⋯− B\omega _{m}x_{m} score=A−Bln(odds)=A−B(ωT+b)=(A−Bb)−Bω1x1−Bω2x2⋯−Bωmxm
其中, ω 1 . . . ω x \omega _{1}…\omega _{x} ω1...ωx为最终进入模型的自变量且已经转换为WOE值, ω i \omega _{i} ωi为逻辑回归的变量系数, b b b为逻辑回归的截距, A , B A,B A,B为上页求得的刻度因子。 B ω i x i B\omega _{i}x_{i} Bωixi为变量 x i x_{i} xi对应的评分, ( A − B b ) (A−Bb) (A−Bb)为基础分也可将基础分值平均分配给各个变量。
这样,我们就可以得到如下图或者如图二中标准刻度评分卡的样式,对应的score便可根据公式顺利求出。(下图数据非真实数据)

2)概率评分卡
L O G I S T LOGIST LOGIST函数的特点就在于可以将事件发生的概率P约束在0~1区间,本质上也是对线性回归或者其他算法模型做的一种对数转换。
那么,在无法实现标准评分转换的情况下,我们可以直接将概率预测值线性约束到我们想要的评分区间:
s c o r e = A − B ∗ P ( 1 ) score = A-B*P(1) score=A−B∗P(1)
效果如下图:

3)两种评分卡形式的优点:
两种方法本质上没有区别,只是划分的区间不同。
1)刻度评分卡:
2)概率评分卡:
注: 为了方便业务理解和使用,通常,我们会将评分卡的分数基于某种数学转换方式约束到一个完整的区间(cutoff),如:300~850,具体根据业务需求和偏好制定。
二、业务中评分卡的cutoff值如何定?
如下图,得到score之后,我们就有了一份完整的贷后评分数据,包括label字段和score字段。那么,如何切分cutoff呢,哪部分用户拒绝,哪部分用户通过,怎么确定呢?我们需要用到几个业务指标:
大致思路为:把分数降序排列分为一百段,按1%的通过率递增,(或者50段,20段,15段,因样本量和区分度等需求拟定),根据分箱违约率、累计违约率、累计通过率、综合盈利的综合考量,决定业务中比较合适的评分卡cutoff值。
如下示例(非真实数据):

我们可以看到,因为放款成本的问题,如果分数卡太高,绝对亏损。在cutoff卡在527分以上的时候,通过率为60%,此时累计坏账率为9.63%,扭亏为盈。如果分数降低点,坏账依旧可控,那分数卡的越低,通过率越高,盈利就越多。不过,随着分数的降低,坏账比增高,升到一定程度,扭赢为亏。
那么为了保持盈利,我们就需要找最优盈利下的那个cutoff值。(一般综合盈利需要财务部、风险部、运营部协同生产)
在有贷后数据的基础上,业务中的评分卡阈值就是这样产生的。
当然,很多产品上线初期没有足够的贷后数据,那么就可以根据行业标准去推断这个阈值。比如先去调研当下行业整体针对不同产品、不同渠道的通过率、坏账率大概是多少,然后计算综合成本,最后看下要求满足的通过率所对应的评分卡阈值为多少,那么就可以以那个值为标准去做业务,后期持续优化。另外,评分卡阈值的制定,不单纯看数据,经验也很重要,比如:老板看好接下来的市场,也可以提高通过率,虽然意味着高坏账的发生,但也许对应着更高的利润。
我们也可以将评分卡划分更多的意义区间,如:
分别用于风险授信、额度设计、精细化管理等业务中。
3)开发出的评分卡,可以应用于信贷产品的哪些方面?
评分模型可应用于贷前客户引流、审批、授信,贷中客户精细化管理、违约预警,贷后催收响应等环节。
我们可以根据信用周期的需求,开发多种评分模型:
客户筛选评分模型
① 筛选白名单客群
② 提高审批通过率
贷前-申请信用评分模型
贷中-行为评分模型
① 提前预警
② 额度管理
③ 精细化管理
贷后-催收评分模型
① 优化催收策略
② 优化催收人力分配
③ 优化催收力度调节
三、总结
- 今天,我们针对多数同学感兴趣的评分卡阈值设置,做了几点介绍,主要成果如下:
- ① 评分卡的两种方式
- ② 业务中如何切分评分卡阈值
- ③ 评分卡在信贷领域的多种应用场景
- ④ 小伙伴们如果还有其他补充,欢迎评论,或者在公众号留言。
四、番外
对数据分析、机器学习、数据科学、金融风控等感兴趣的小伙伴,需要数据集、代码、行业报告等各类学习资料,可添加微信:wu(记得要备注喔!),也可关注微信公众号:风控圏子(别打错字,是圏子,不是圈子,算了直接复制吧!)

关注公众号后,可联系圈子助手加入如下社群:
- 机器学习风控讨论群(微信群)
- 反欺诈讨论群(微信群)
- python学习交流群(微信群)
- 研习社资料(:)(干货、资料、项目、代码、报告、课件)
相互学习,共同成长。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/230121.html原文链接:https://javaforall.net


