
根据大量的测试统计数据,很多错误是发生在输入或输出范围的边界上,而不是发生在输入/输出范围的中间区域。
因此针对各种边界情况设计测试用例,可以查出更多的错误.具有很强的发现故障缺陷能力。
所谓边界值,是指相对于输入等价类和输出等价类而言,稍高于其最高值或稍低于最低值的一些特定情况。
边界值分析是一种常用的黑盒测试方法,是对等价类划分方法的补充。
(1)边界的类型
边界的类型包括数值、速度、字符、地址、位置、尺寸、数量、空间等,考虑这些数据类型的下述特征∶
第一个和最后一个、最小值和最大值、开始/完成、超过和在内、空/满、最短/最长、最慢和最快、最早和最迟、最高/最低、相邻/最远等。
部分边界值类型测试用例设计取值如表所示。
部分边界值类型测试用例设计取值表


由于边界值分析法是等价类划分法的补充所以,从等价类中选取测试数据时应该将等于或刚刚小于等价类边界的值作为测试数据,而不是选取等价类中的典型值或任意值作为测试数据。
(2)边界值分析方法设计测试用例的原则
① 如果输入条件规定了值的范围,则应取刚达到这个范围的边界的值以及刚风超越这个范围边界的值作为测试输入数据。例如.如果程序的规格说明中规定∶”质量在10公斤至50公斤范围内的邮件,其邮费计算公式为.….”作为测试用例,,应取10及50,还应取10.01、49.99、9.99及50.01等。
②如果输入条件规定了值的个数、则用最大个数、最小个数、比最小个数少一、比最大个数多一的数作为测试数据。例如,一个输入文件应包括1~255个记录,则测试用例可取1和255,还应取0及256 等。
③将规则①和②应用于输出条件,即设计测试用例使输出值达到边界值及其左右的值。例如,某程序的规格说明要求计算出“每月保险金扣除额为0至1165.25元”,其测试用例可取0.00及1165.24、还可取-0.01及1165.26等。
再如一程序属于情报检索系统,要求每次“最少显示1条、最多显示4条情报摘要”,这时应考虑的测试用例包括1和4,还应包括0和5等。
④如果程序的规格说明给出的输入域或输出域是有序集合,则应选取集合的第一个元素和最后一个元素作为测试用例。
⑤如果程序中使用了一个内部数据结构,则应当选择这个内部数据结构的边界上的值作为测试用例。
⑥分析规格说明,找出其他可能的边界条件。
(3)标准边界值分析
在实际的测试中,标准边界值分析一般取用5个值,即输入变量的最小值(min)、稍大于最小值(min+)、域内任意值(nom,一般为中间值)、稍小于最大值(max-)和最大值(max)来设计测试用例。对于多个变量的情况,只使其中一个变量分别取最小值、稍大于最小值、稍小于最大值和最大值,其他所有变量取正常值(nom)并逐一配对来进行测试。

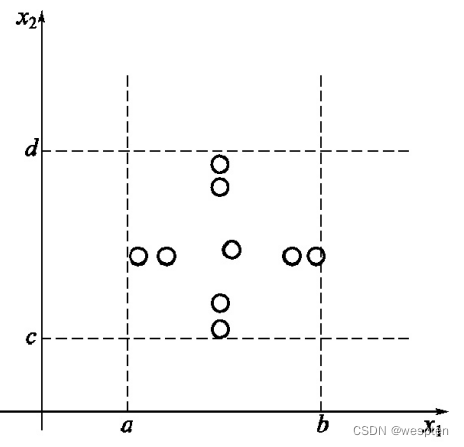
图 标准边界值分析测试用例取值点
一个含有n个变量的程序,保留其中一个变量,让其余变量取正常值,这个被保留的变量依次取为min、min+、nom、max-和max。
对每个变量都重复进行。那么,对于一个n变量的程序,边界值分析测试会产生4n+1个测试用例。
不管采用什么语言,变量的min、min+、nom、max-、max值根据语境可以很清楚地确定。如果没有明确地给出边界,例如三角形问题,可以人为设定一个边界。显然边长的下界是1(边长为负没有什么意义)。但如何来确定上界呢?在默认情况下,可以取最大可表示的整型值(某些语言里称为MAXINT),或者根据实际需求的情况确定一个数作为上界,如100或1000等。
(4)健壮性边界值分析
健壮性是指在异常情况下,软件还能正常运行的能力。健壮性测试是标准边界值分析的一种简单扩展。除了变量的min、min+、nom、max-、max这5个边界分析取值外,还要考虑略超过最大值(max+)和略小于最小值(min-)时的情况。健壮性测试的最大价值在于观察处理异常情况,它是检测软件系统容错性的重要手段。

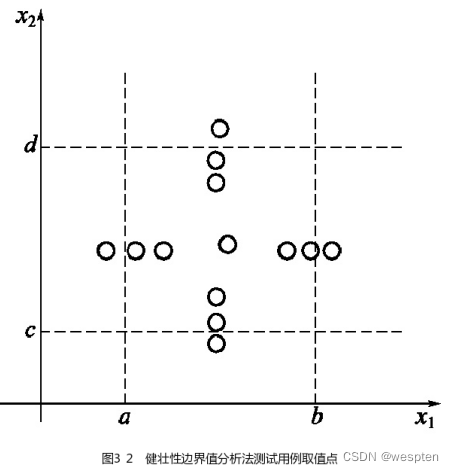
一个含有n个变量的程序,保留其中一个变量,让其余变量取正常值这个被保留的变量依次取为min-、min、min+、nom、max-、
max和max+。对每个变量都重复进行。那么,对于一个n变量的程序,健壮性边界值分析测试会产生6n+1个测试用例。
边界值分析大部分的测试都可直接用于健壮性测试。健壮性测试最有意义的部分不是输入而是输出,观察边界之外的情况如何处理。
对于强类型语言,健壮性测试可能比较困难,比如在C语言中,如果给定一个变量的取值范围,超过这个范围的取值都会产生故障。
3.2.2 边界值分析法测试用例设计举例
(1)实例1∶输入商品数,输出应付钱数
某商店为购买不同数量商品的顾客报出不同的价格,其报价规则如表3 8所示。
不同数量商品对应的单价表

如买11件需要支付10×30+1×27=327元买35件需要支付10×30+10×27+10×25+5×22=930元。
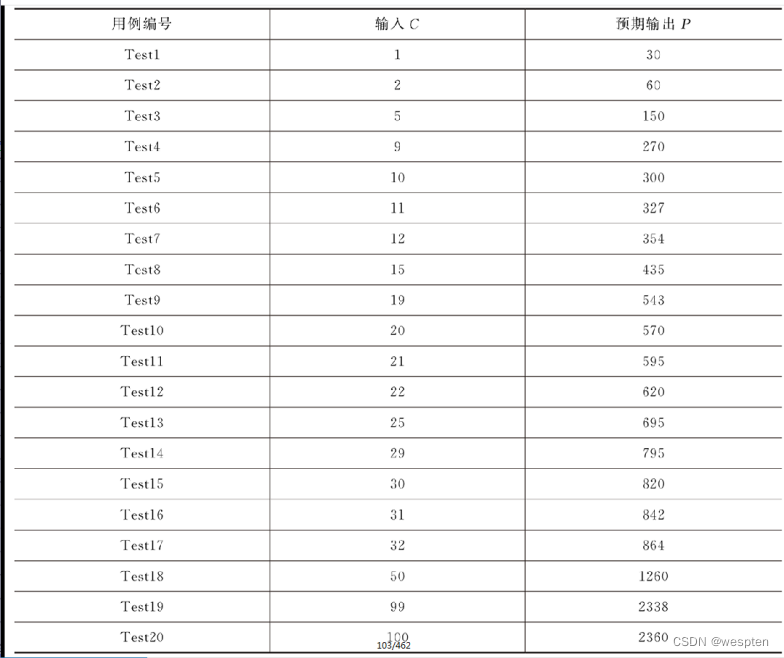
现为该商家开发一个软件,输入为商品数C(1≤C≤100),输出为应付的总价P。
请采用边界值分析法为该软件设计测试用例(不考虑健壮性测试,即不考虑C不在1到100直接或者是非整数的情况)。
分析题目中的条件,可以看到输入商品数C实际上是有4个取值范围,每个取值范围都有最大值和最小值,按照标准边界值分析测试用例设计的方法,,每个范围应该取5个值,测试用例如表3 9所示。
商品输出价格表
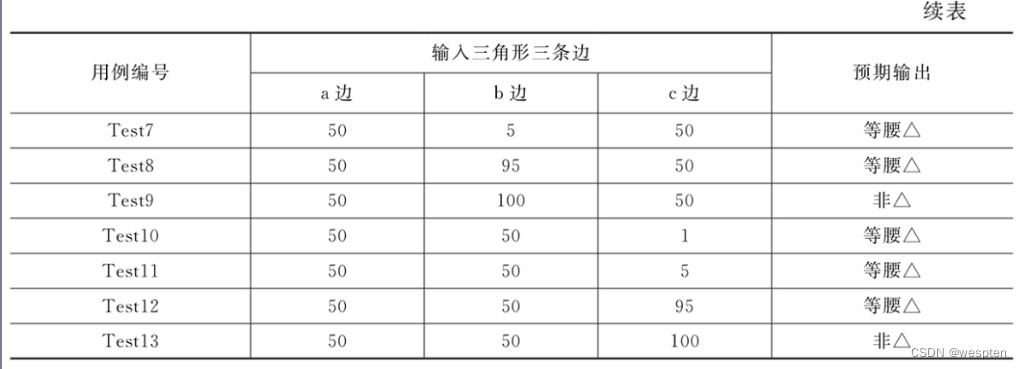
(2)实例2∶三角形问题标准边界值分析法测试用例设计
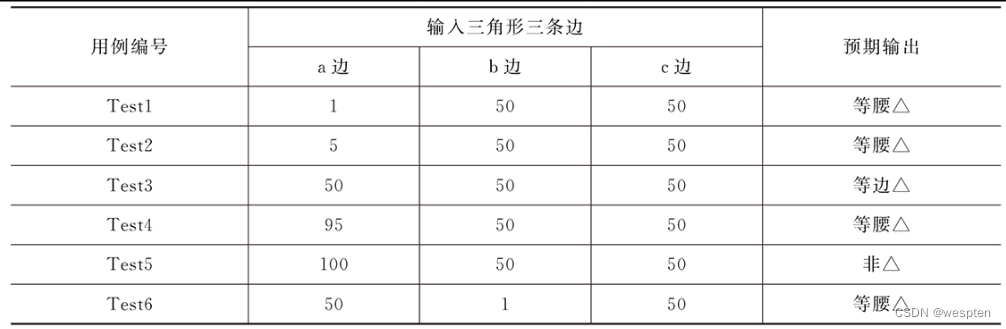
假设三角形的三条边的取值范围为【1,100】,请使用标准边界值法写出测试用例。
边界值分析法只考虑边界值的输入和输出所以对于三角形来说,只考虑三条边的取值,相当于有3个输入。
假设三条边分别为a,b,c,每个边的取值都在1~100间取值,每条边都要取到5个值,按照公式,则一共有4×3+1=13条测试用例。测试用例如下表所示。
三角形问题标准边界值分析法测试用例设计表
(3)实例3∶加法器边界值测试用例设计
加法器程序计算两个数的和,假设两个加数都取1~100之间的数。
请用等价类分析法与健壮性边界值分析法编写测试用例。
①单独等价类划分法∶分析题目要求假设两个加数分别为a、b. 二者的取值范围为【1,100】根据等价类划分原则,等价类表如下表所示。
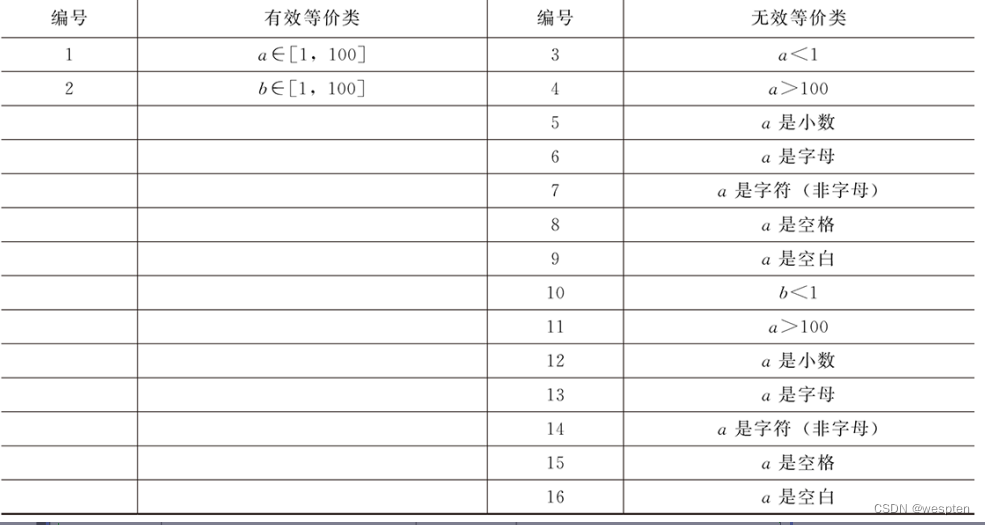
设计等价类测试用例
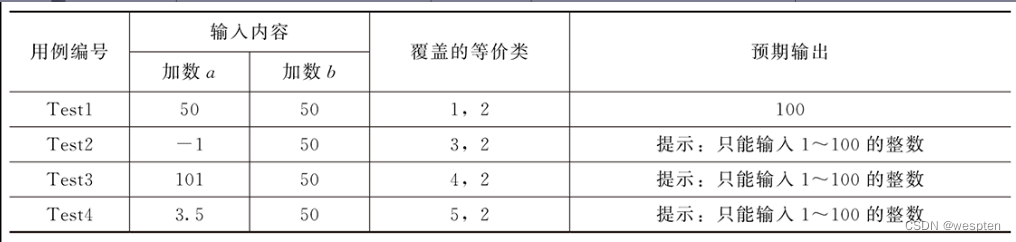
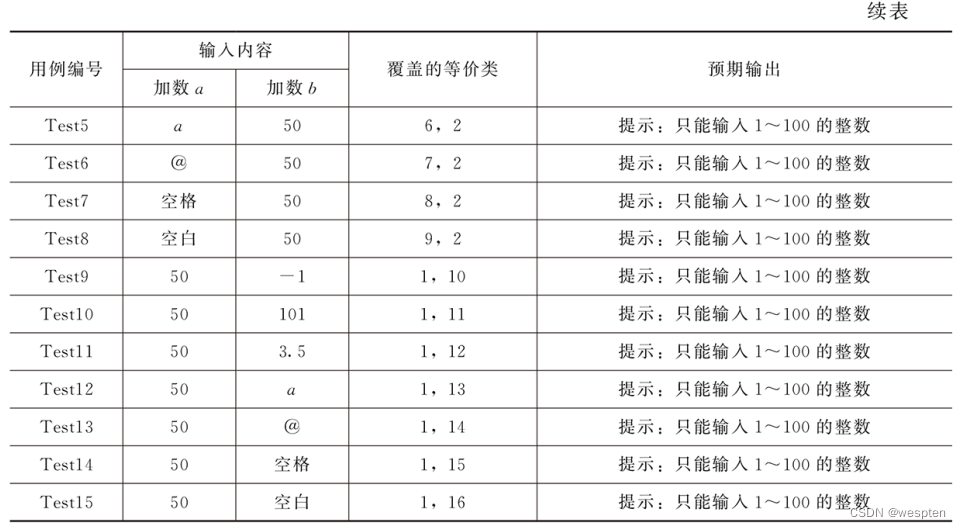
②单独健壮性边界值分析法∶分析题目要求,假设两个加数分别为a,b,二者的取值范围为【1,100】a或b每个取值为7个根据公式,一共为6×2+1=13条,具体测试用例如下表所示。
加法器单独健壮性边界值测试用例表
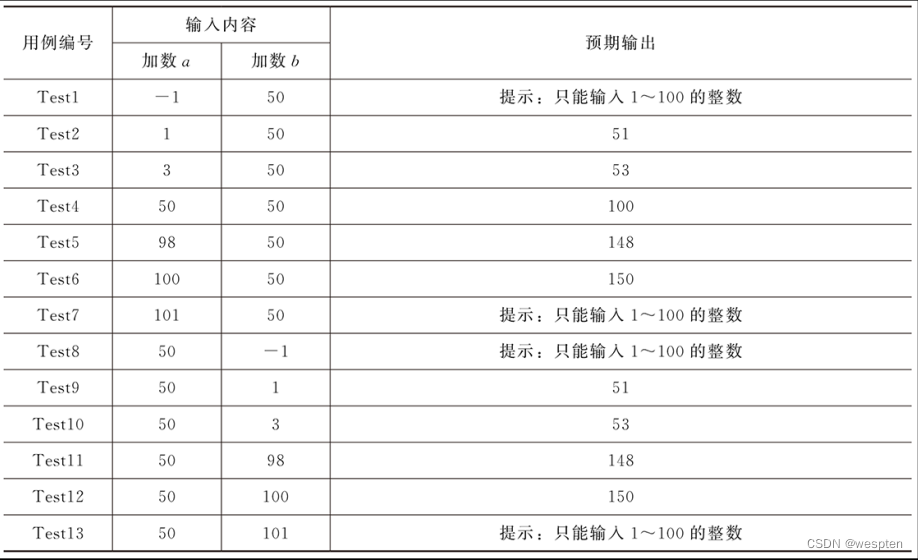
③分析可以发现,表3 12中的无效等价类包含了表3 13的无效输入,表3 13则包含了表3 12中的有效等价类,这样把两张表合并在一起,如表3 14所示,即为加法器等价类分析与健壮性边界值分析的测试用例设计表。
表3 14 加法器等价类分析与健壮性边界值分析的测试用伤设计表
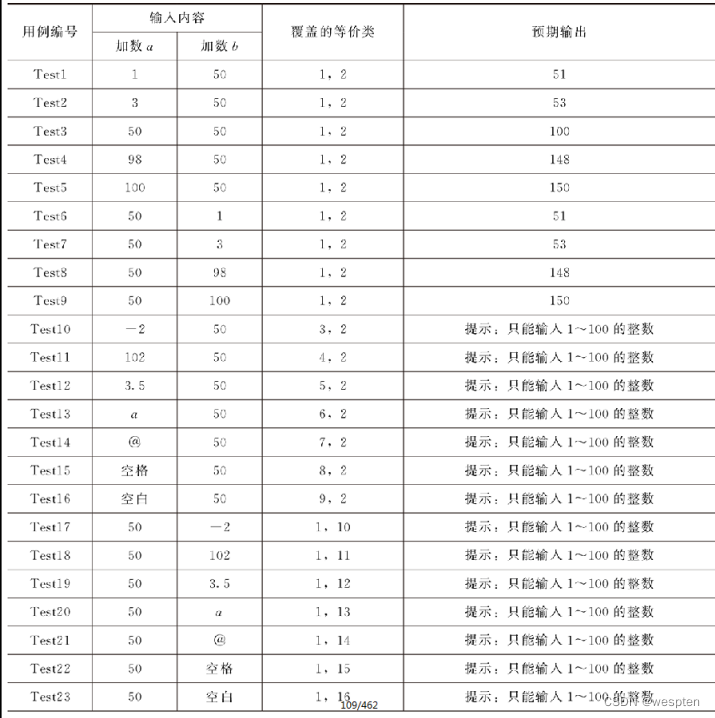
通过对比不难发现,边界值分析法在有效等价类上补充的较多,对于无效等价类来说,补充的较少,其至在类似例题中的取值比较明确的情况下没有补充。
在实际应用中,结合具体情况设计测试用例。



发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/232038.html原文链接:https://javaforall.net


