
需要提前了解的知识:KMP, 字典树
由于类比了kmp算法,建议大家可以看一下我的kmp教程,以便于理解kmp(详解)
简介
AC自动机是KMP和trie的结合体。KMP算法适用于单模式串的匹配,而AC自动机适合多模式串的匹配。例如:在一篇文章中我们找一句话可以用KMP,找多句话适用于AC自动机。并且可以这么认为,KMP是AC自动机的特殊情况。
实现AC自动机
算法思路
我们先是用模式串构建了trie树,以单词she, shr, say, her作为例子
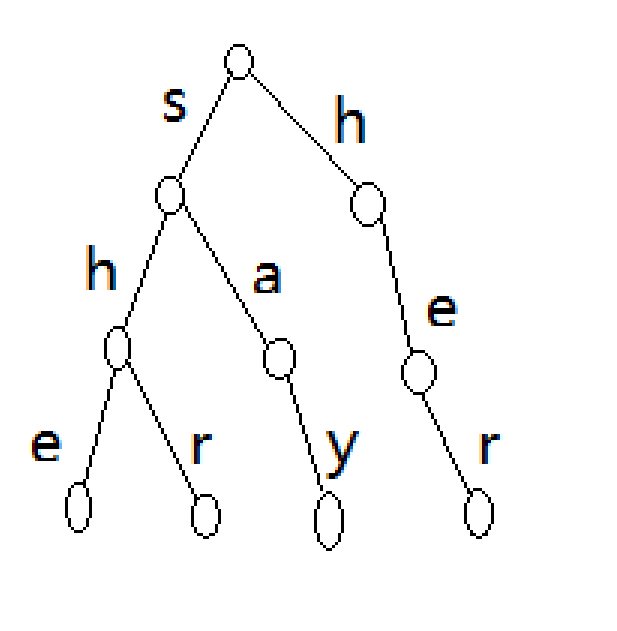

这就是我们构建的trie树了。
在kmp算法中我们构建了一个nex数组(查询表),通过查询表,在我们每次失配的情况下快速移动模式串,从而避免了大量的不必要的比较。
nex[i]的含义以p[i]j结尾的后缀,能够匹配的从1开始非平凡前缀的最大坐标。在AC自动机中的含义也是同样的。
那么我们可以故技重施,为AC自动机也构建一个查询表,在AC自动机中叫失配指针。
同时,在KMP中,初始值nex[0] = nex[1] = 0, 另外如果我们需要求出nex[i],则需要用到nex[0]-nex[i-1],在AC自动机中,如果我们需要求出第i层点的nex值,则需要使用到i-1层(包括)前面的nex值。
由于每次向下求一层的nex,所以用bfs。
举个nex指针的例子:
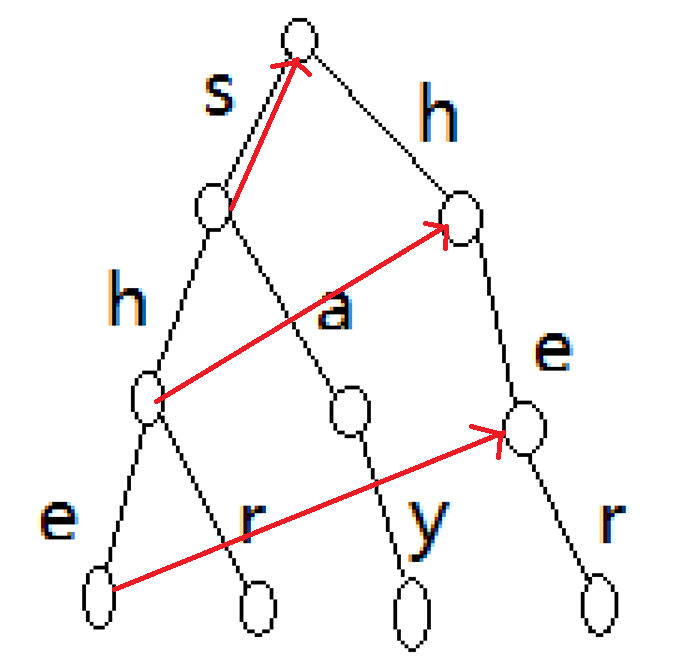
红色代表nex指向,(其中只花了部分点的nex)
以下是构建kmp中nex数组大的代码
void getNex(char p[], int lenp) {
for(int i = 2, j = 0; i <= lenp; i++) {
while(j && p[i] != p[j+1]) j = nex[j]; if(p[i] == p[j+1] ) j++; nex[i] = j; } } 类比代码
void bulid() {
int hh = 0, tt = -1; //第一层和第二层的nex值已经确定 //所以直接将第二层节点的孩子加入队列中就行 //ps:以26个英文字母为例 for(int i = 0; i <26; i++) if(tr[0][i]) q[++tt] = tr[0][i]; while(hh <= tt) {
int t = q[hh++]; for(int i = 0; i < 26; i++) {
int c = tr[t][i];//相当于kmp的i if(!c) continue; int j = nex[t]; while(j && !tr[j][i]) j = nex[j];//当j没有i字母的孩子 if(tr[j][i]) j = tr[j][i]; nex[c] = j; q[++tt] = c;//将c加入队列 } } } 匹配过程
以下是kmp算法的匹配过程
void kmp(char t[], char p[], int lent,int lenp) {
for(int i = 1, j = 0; i <= lent; i++) {
while(j && t[i] != p[j+1]) j = nex[j]; if(t[i] == p[j+1]) j++; if(j == lenp) {
printf("%d\n", i - lenp + 1);//匹配成功的位置 j = nex[j]; } } } 同样类比于kmp的匹配过程,我们同样可以得出AC自动机的匹配过程
//tr中已经储存了需要查询的模式串 //str是文本串 //cnt记录每个点的单词数 //我们需要找到有多少个模式串在文本串中出现过 for(int i = 0, j = 0; str[i]; i++) {
int t = str[i] - 'a'; while(j && !tr[j][t]) j = nex[j]; if(tr[j][t]) j = tr[j][t]; int p = j; //while循环下面解释 while(p) {
res += cnt[p]; cnt[p] = 0; p = nex[p]; } } 这段代码所匹配的是以str[i]为结尾的最长后缀,我们假设文本串为qwher,模式串为he, whe。那么当str[i]为e的时候,我们所匹配的是whe这个模式串,但是由于he是whe的后缀,he也应当出现在文本串中,所以我们需要加上whe的e的nex指针指向的点。
但由于while循环的出现,在比较坏的情况下我们难以接近线性复杂度,而是趋近于o(n^2)的复杂度, 因此我们需要对此优化。也就是优化成为trie图
如何优化成为trie图
消耗时间的部分主要是这一行代码
while(j && !tr[j][t]) j = nex[j]; void bulid() {
int hh = 0, tt = -1; //第一层和第二层的nex值已经确定 //所以直接将第二层节点的孩子加入队列中就行 for(int i = 0; i <26; i++) if(tr[0][i]) q[++tt] = tr[0][i]; while(hh <= tt) {
int t = q[hh++]; for(int i = 0; i < 26; i++) {
int p = tr[t][i]; if(!p) tr[t][i] = tr[nex[t]][i];//如果不存在这个儿子 else//如果存在这个儿子 {
nex[p] = tr[nex[t]][i]; q[++tt] = p; } } } } 同时匹配过程也就可以直接去掉while循环
for(int i = 0, j = 0; str[i]; i++) {
int t = str[i] - 'a'; j = tr[j][t]; int p = j; while(p) {
res += cnt[p]; cnt[p] = 0; p = nex[p]; } } #include <bits/stdc++.h> using namespace std; const int M = 1e6 + 10; const int N = 128; int n; int tr[M][N], nex[M], cnt[M]; int q[M], hh , tt = -1; char str[M]; int idx, res; bool st[M]; void Insert() {
int p = 0; for(int i = 0; str[i]; i++) {
int t = str[i]; if(!tr[p][t]) tr[p][t] = ++idx; p = tr[p][t]; } cnt[p]++; } void init() {
memset(tr, 0, sizeof tr); memset(nex, 0, sizeof nex); memset(cnt, 0, sizeof cnt); idx = res = 0; } void bulid() {
int hh = 0, tt = -1; //第一层和第二层的nex值已经确定 //所以直接将第二层节点的孩子加入队列中就行 for(int i = 0; i < N; i++) if(tr[0][i]) q[++tt] = tr[0][i]; while(hh <= tt) {
int t = q[hh++]; for(int i = 0; i < N; i++) {
int p = tr[t][i]; if(!p) tr[t][i] = tr[nex[t]][i];//如果不存在这个儿子 else//如果存在这个儿子 {
nex[p] = tr[nex[t]][i]; q[++tt] = p; } } } } int main() {
init(); scanf("%d", &n); for(int i = 0; i < n; i++) {
scanf("%s", str); Insert(); } bulid(); scanf("%s", str); for(int i = 0, j = 0; str[i]; i++) {
int t = str[i]; j = tr[j][t]; int p = j; //在访问过一次p后,下一次就没有必要访问了,否则会重复计算,浪费时间。 while(p && st[p] == 0) {
st[p] = 1; res += cnt[p]; cnt[p] = 0; p = nex[p]; } } printf("%d\n", res); return 0; } 发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/232538.html原文链接:https://javaforall.net


