
python音乐推荐系统
首先对音乐数据集进行数据清洗和特征提取,基于矩阵分解方式来进行音乐推荐。
- 音乐数据处理
读取音乐数据集,并统计其各项指标,选择有价值的信息当做我们的特征 - 基于商品相似性的推荐
选择相似度计算方法,通过相似度来计算推荐结果 - 基于SVD矩阵分解的推荐
使用矩阵分解方法,快速高效得到推荐结果
import pandas as pd import numpy as np import time import sqlite3 data_home = './' 数据提取
提取用户,歌曲,播放量
triplet_dataset = pd.read_csv(filepath_or_buffer=data_home+'train_triplets.txt', sep='\t', header=None, names=['user','song','play_count']) 查看数据大小
triplet_dataset.shape 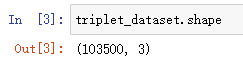

triplet_dataset.info() 查看原始数据
triplet_dataset.head(n=5) 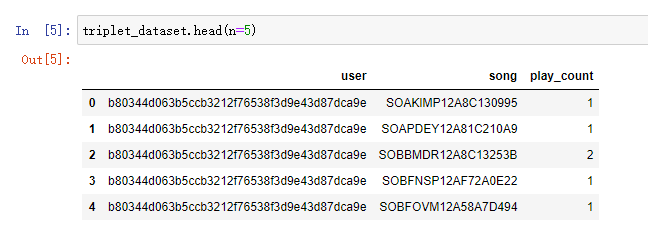
得到每个用户的播放量
对每个用户进行遍历
output_dict = {} with open(data_home+'train_triplets.txt') as f: for line_number, line in enumerate(f): user = line.split('\t')[0] play_count = int(line.split('\t')[2]) if user in output_dict: play_count +=output_dict[user] output_dict.update({user:play_count}) output_dict.update({user:play_count}) output_list = [{'user':k,'play_count':v} for k,v in output_dict.items()] play_count_df = pd.DataFrame(output_list) play_count_df = play_count_df.sort_values(by = 'play_count', ascending = False) 保存中间结果 防止丢失(df格式)
play_count_df.to_csv(path_or_buf='user_playcount_df.csv', index = False) 得到每首歌的播放量
#统计方法跟上述类似 output_dict = {} with open(data_home+'train_triplets.txt') as f: for line_number, line in enumerate(f): #找到当前歌曲 song = line.split('\t')[1] #找到当前播放次数 play_count = int(line.split('\t')[2]) #统计每首歌曲被播放的总次数 if song in output_dict: play_count +=output_dict[song] output_dict.update({song:play_count}) output_dict.update({song:play_count}) output_list = [{'song':k,'play_count':v} for k,v in output_dict.items()] #转换成df格式 song_count_df = pd.DataFrame(output_list) song_count_df = song_count_df.sort_values(by = 'play_count', ascending = False) song_count_df.to_csv(path_or_buf='song_playcount_df.csv', index = False) 查看目前的排行
play_count_df = pd.read_csv(filepath_or_buffer='user_playcount_df.csv') play_count_df.head(n =10) song_count_df = pd.read_csv(filepath_or_buffer='song_playcount_df.csv') song_count_df.head(10) 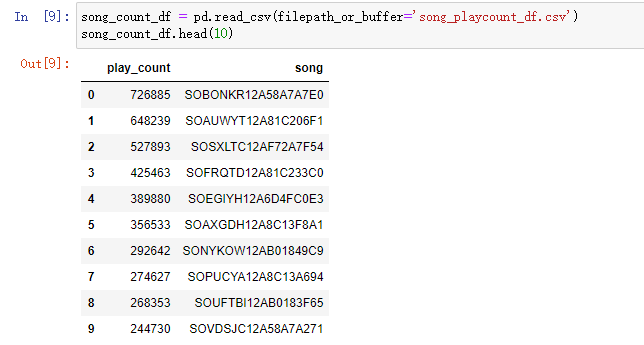
对数据进行清洗
选择十万名用户和3w首歌曲来作为新的数据集
查看这10w名用户的播放量占总体的比例
total_play_count = sum(song_count_df.play_count) print ((float(play_count_df.head(n=).play_count.sum())/total_play_count)*100) play_count_subset = play_count_df.head(n=) 查看3w歌曲的播放量占总体的比例
(float(song_count_df.head(n=30000).play_count.sum())/total_play_count)*100 song_count_subset = song_count_df.head(n=30000) 前3W首歌的播放量占到了总体的78.39% 现在已经有了这10W名忠实用户和3W首经典歌曲,接下来我们就要对原始数据集进行过滤清洗,说白了就是在原始数据集中剔除掉不包含这些用户以及歌曲的数据。
取10W个用户,3W首歌
user_subset = list(play_count_subset.user) song_subset = list(song_count_subset.song) 过滤其他用户数据
#读取原始数据集 triplet_dataset = pd.read_csv(filepath_or_buffer=data_home+'train_triplets.txt',sep='\t', header=None, names=['user','song','play_count']) #只保留有这10W名用户的数据,其余过滤掉 triplet_dataset_sub = triplet_dataset[triplet_dataset.user.isin(user_subset) ] del(triplet_dataset) #只保留有这3W首歌曲的数据,其余也过滤掉 triplet_dataset_sub_song = triplet_dataset_sub[triplet_dataset_sub.song.isin(song_subset)] del(triplet_dataset_sub) triplet_dataset_sub_song.to_csv(path_or_buf=data_home+'triplet_dataset_sub_song.csv', index=False) 当前的数据量
triplet_dataset_sub_song.shape 此时样本数量少但是有利于建模,不但可以提高效率还可以提高准确度
triplet_dataset_sub_song.head(n=10) 加入音乐的详细信息(歌手,发布时间,主题等)
conn = sqlite3.connect(data_home+'track_metadata.db') cur = conn.cursor() cur.execute("SELECT name FROM sqlite_master WHERE type='table'") cur.fetchall() track_metadata_df = pd.read_sql(con=conn, sql='select * from songs') track_metadata_df_sub = track_metadata_df[track_metadata_df.song_id.isin(song_subset)] track_metadata_df_sub.to_csv(path_or_buf=data_home+'track_metadata_df_sub.csv', index=False) track_metadata_df_sub.shape 现有的数据
triplet_dataset_sub_song = pd.read_csv(filepath_or_buffer=data_home+'triplet_dataset_sub_song.csv',encoding = "ISO-8859-1") track_metadata_df_sub = pd.read_csv(filepath_or_buffer=data_home+'track_metadata_df_sub.csv',encoding = "ISO-8859-1") triplet_dataset_sub_song.head() 清洗数据集
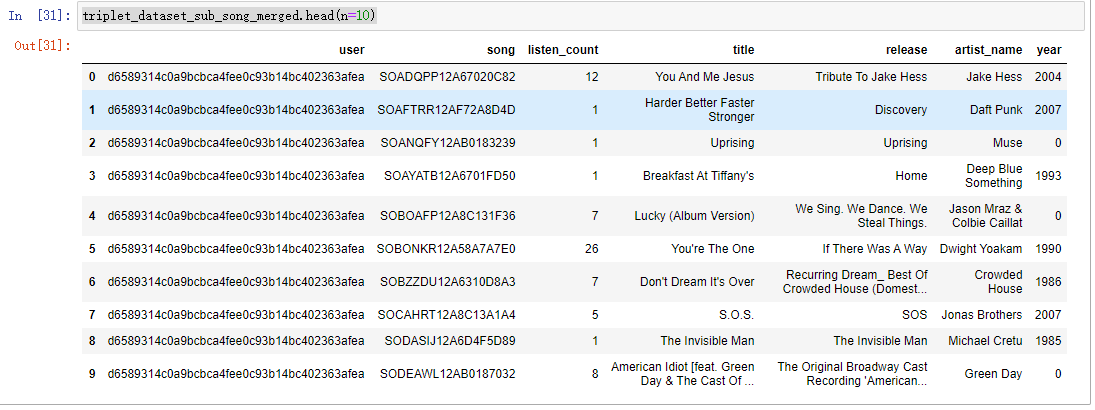
# 去掉无用的信息 del(track_metadata_df_sub['track_id']) del(track_metadata_df_sub['artist_mbid']) # 去掉重复的 track_metadata_df_sub = track_metadata_df_sub.drop_duplicates(['song_id']) # 将这份音乐信息数据和我们之前的播放数据整合到一起 triplet_dataset_sub_song_merged = pd.merge(triplet_dataset_sub_song, track_metadata_df_sub, how='left', left_on='song', right_on='song_id') # 可以自己改变列名 triplet_dataset_sub_song_merged.rename(columns={'play_count':'listen_count'},inplace=True) # 去掉不需要的指标 del(triplet_dataset_sub_song_merged['song_id']) del(triplet_dataset_sub_song_merged['artist_id']) del(triplet_dataset_sub_song_merged['duration']) del(triplet_dataset_sub_song_merged['artist_familiarity']) del(triplet_dataset_sub_song_merged['artist_hotttnesss']) del(triplet_dataset_sub_song_merged['track_7digitalid']) del(triplet_dataset_sub_song_merged['shs_perf']) del(triplet_dataset_sub_song_merged['shs_work']) triplet_dataset_sub_song_merged.head(n=10) 现有的数据
import matplotlib.pyplot as plt; plt.rcdefaults() import numpy as np import matplotlib.pyplot as plt #按歌曲名字来统计其播放量的总数 popular_songs = triplet_dataset_sub_song_merged[['title','listen_count']].groupby('title').sum().reset_index() #对结果进行排序 popular_songs_top_20 = popular_songs.sort_values('listen_count', ascending=False).head(n=20) #转换成list格式方便画图 objects = (list(popular_songs_top_20['title'])) #设置位置 y_pos = np.arange(len(objects)) #对应结果值 performance = list(popular_songs_top_20['listen_count']) #绘图 plt.bar(y_pos, performance, align='center', alpha=0.5) plt.xticks(y_pos, objects, rotation='vertical') plt.ylabel('Item count') plt.title('Most popular songs') plt.show() 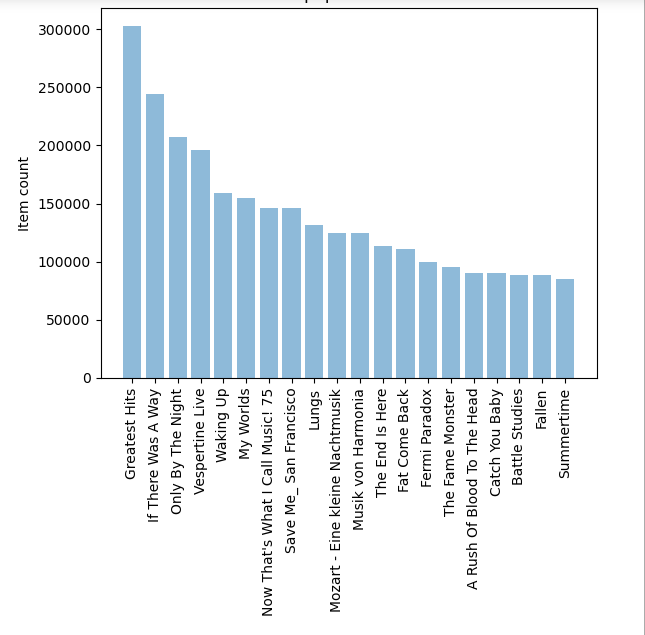
查看最受欢迎的专辑
#按专辑名字来统计播放总量 popular_release = triplet_dataset_sub_song_merged[['release','listen_count']].groupby('release').sum().reset_index() #排序 popular_release_top_20 = popular_release.sort_values('listen_count', ascending=False).head(n=20) objects = (list(popular_release_top_20['release'])) y_pos = np.arange(len(objects)) performance = list(popular_release_top_20['listen_count']) #绘图 plt.bar(y_pos, performance, align='center', alpha=0.5) plt.xticks(y_pos, objects, rotation='vertical') plt.ylabel('Item count') plt.title('Most popular Release') plt.show() 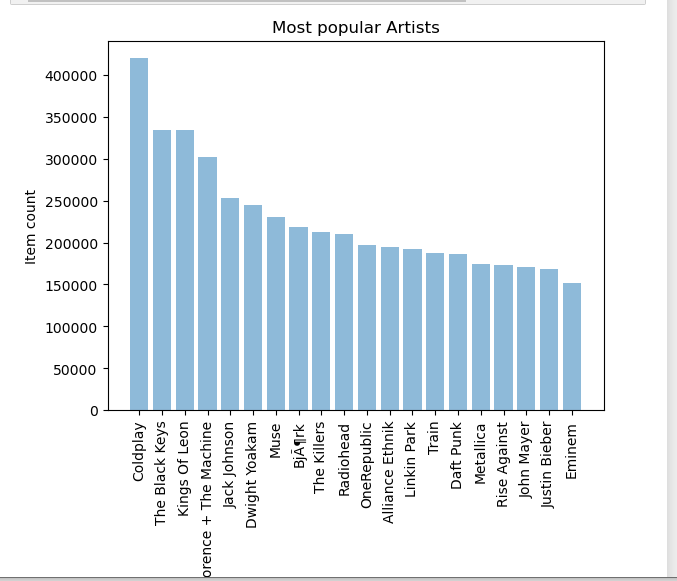
用户播放过歌曲量的分布
user_song_count_distribution = triplet_dataset_sub_song_merged[['user','title']].groupby('user').count().reset_index().sort_values( by='title',ascending = False) user_song_count_distribution.title.describe() x = user_song_count_distribution.title n, bins, patches = plt.hist(x, 50, facecolor='green', alpha=0.75) plt.xlabel('Play Counts') plt.ylabel('Num of Users') plt.title(r'$\mathrm{Histogram\ of\ User\ Play\ Count\ Distribution}\ $') plt.grid(True) plt.show() 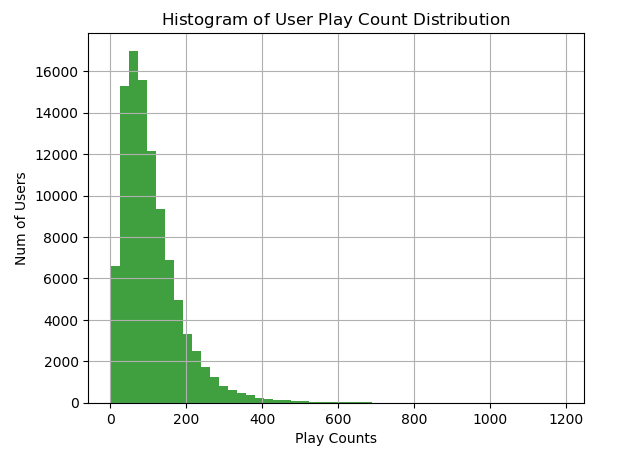
正式开始构建推荐系统
import Recommenders as Recommenders from sklearn.model_selection import train_test_split 最简单的就是根据榜单推荐(新用户冷启动问题)
triplet_dataset_sub_song_merged_set = triplet_dataset_sub_song_merged train_data, test_data = train_test_split(triplet_dataset_sub_song_merged_set, test_size = 0.40, random_state=0) train_data.head() 
def create_popularity_recommendation(train_data, user_id, item_id): #根据指定的特征来统计其播放情况,可以选择歌曲名,专辑名,歌手名 train_data_grouped = train_data.groupby([item_id]).agg({user_id: 'count'}).reset_index() #为了直观展示,我们用得分来表示其结果 train_data_grouped.rename(columns = {user_id: 'score'},inplace=True) #排行榜单需要排序 train_data_sort = train_data_grouped.sort_values(['score', item_id], ascending = [0,1]) #加入一项排行等级,表示其推荐的优先级 train_data_sort['Rank'] = train_data_sort['score'].rank(ascending=0, method='first') #返回指定个数的推荐结果 popularity_recommendations = train_data_sort.head(20) return popularity_recommendations recommendations = create_popularity_recommendation(triplet_dataset_sub_song_merged,'user','title') 得到结果
recommendations 基于歌曲相似度的推荐 核心思想
- 计算相似度
首先我们要针对某一个用户进行推荐,那必然得先得到他都听过哪些歌曲,通过这些已被听过的歌曲跟整个数据集中的歌曲进行对比,看哪些歌曲跟用户已听过的比较类似,推荐的就是这些类似的。如何计算呢?例如当前用户听过了66首歌曲,整个数据集中有4879个歌曲,我们要做的就是构建一个[66,4879]的矩阵,其中每一个值表示用户听过的每一个歌曲和数据集中每一个歌曲的相似度。这里使用Jaccard相似系数,矩阵中[i,j]的含义就是用户听过的第i首歌曲这些歌曲被哪些人听过,比如有3000人听过,数据集中的j歌曲被哪些人听过,比如有5000人听过。Jaccard相似系数就要求:

说白了就是如果两个歌曲很相似,那其受众应当是一致的,交集/并集的比例应该比较大,如果两个歌曲没啥相关性,其值应当就比较小了。 上述代码中计算了矩阵[66,4879]中每一个位置的值应当是多少,在最后推荐的时候我们还应当注意一件事对于数据集中每一个待推荐的歌曲都需要跟该用户所有听过的歌曲计算其Jaccard值,例如歌曲j需要跟用户听过的66个歌曲计算其值,最终是否推荐的得分值还得进行处理,即把这66个值加在一起,最终求一个平均值,来代表该歌曲的推荐得分。
选取一部分数据进行推荐
song_count_subset = song_count_df.head(n=5000) user_subset = list(play_count_subset.user) song_subset = list(song_count_subset.song) triplet_dataset_sub_song_merged_sub = triplet_dataset_sub_song_merged[triplet_dataset_sub_song_merged.song.isin(song_subset)] triplet_dataset_sub_song_merged_sub.head() 计算相似度得到推荐结果
import Recommenders as Recommenders train_data, test_data = train_test_split(triplet_dataset_sub_song_merged_sub, test_size = 0.30, random_state=0) is_model = Recommenders.item_similarity_recommender_py() is_model.create(train_data, 'user', 'title') user_id = list(train_data.user)[7] user_items = is_model.get_user_items(user_id) #执行推荐 is_model.recommend(user_id) triplet_dataset_sub_song_merged_sum_df = triplet_dataset_sub_song_merged[['user','listen_count']].groupby('user').sum().reset_index() triplet_dataset_sub_song_merged_sum_df.rename(columns={'listen_count':'total_listen_count'},inplace=True) triplet_dataset_sub_song_merged = pd.merge(triplet_dataset_sub_song_merged,triplet_dataset_sub_song_merged_sum_df) triplet_dataset_sub_song_merged.head() 
triplet_dataset_sub_song_merged['fractional_play_count'] = triplet_dataset_sub_song_merged['listen_count']/triplet_dataset_sub_song_merged['total_listen_count'] triplet_dataset_sub_song_merged[triplet_dataset_sub_song_merged.user =='dc0a9bcbca4fee0c93b14bcafea'][['user','song','listen_count','fractional_play_count']].head() from scipy.sparse import coo_matrix small_set = triplet_dataset_sub_song_merged user_codes = small_set.user.drop_duplicates().reset_index() song_codes = small_set.song.drop_duplicates().reset_index() user_codes.rename(columns={'index':'user_index'}, inplace=True) song_codes.rename(columns={'index':'song_index'}, inplace=True) song_codes['so_index_value'] = list(song_codes.index) user_codes['us_index_value'] = list(user_codes.index) small_set = pd.merge(small_set,song_codes,how='left') small_set = pd.merge(small_set,user_codes,how='left') mat_candidate = small_set[['us_index_value','so_index_value','fractional_play_count']] data_array = mat_candidate.fractional_play_count.values row_array = mat_candidate.us_index_value.values col_array = mat_candidate.so_index_value.values data_sparse = coo_matrix((data_array, (row_array, col_array)),dtype=float) data_sparse 上面代码先根据用户进行分组,计算每个用户的总的播放总量,然后用每首歌的播放总量相处,得到每首歌的分值,最后一列特征fractional_play_count就是用户对每首歌曲的评分值。 有了评分值之后就可以来构建矩阵了,这里有一些小问题需要处理一下,原始数据中无论是用户ID还是歌曲ID都是很长一串,这表达起来不太方便,需要重新对其制作索引。
user_codes[user_codes.user =='2a2f776cbac6df64d6cb505e7e834e0b6'] 使用SVD方法进行矩阵分解
矩阵构造好了之后我们就要执行SVD矩阵分解了,这里还需要一些额外的工具包来帮助我们完成计算,scipy就是其中一个好帮手了,里面已经封装好了SVD计算方法。
import math as mt from scipy.sparse.linalg import * #used for matrix multiplication from scipy.sparse.linalg import svds from scipy.sparse import csc_matrix def compute_svd(urm, K): U, s, Vt = svds(urm, K) dim = (len(s), len(s)) S = np.zeros(dim, dtype=np.float32) for i in range(0, len(s)): S[i,i] = mt.sqrt(s[i]) U = csc_matrix(U, dtype=np.float32) S = csc_matrix(S, dtype=np.float32) Vt = csc_matrix(Vt, dtype=np.float32) return U, S, Vt def compute_estimated_matrix(urm, U, S, Vt, uTest, K, test): rightTerm = S*Vt max_recommendation = 250 estimatedRatings = np.zeros(shape=(MAX_UID, MAX_PID), dtype=np.float16) recomendRatings = np.zeros(shape=(MAX_UID,max_recommendation ), dtype=np.float16) for userTest in uTest: prod = U[userTest, :]*rightTerm estimatedRatings[userTest, :] = prod.todense() recomendRatings[userTest, :] = (-estimatedRatings[userTest, :]).argsort()[:max_recommendation] return recomendRatings 在执行SVD的时候需要我们额外指定一个指标K值,其含义就是我们选择前多少个特征值来做近似代表,也就是S矩阵中的数量。如果K值较大整体的计算效率会慢一些但是会更接近真实结果,这个值还需要我们自己来衡量一下
K=50 urm = data_sparse MAX_PID = urm.shape[1] MAX_UID = urm.shape[0] U, S, Vt = compute_svd(urm, K) 选取测试用户
uTest = [4,5,6,7,8,873,23] uTest_recommended_items = compute_estimated_matrix(urm, U, S, Vt, uTest, K, True) 对用户进行推荐
for user in uTest: print("Recommendation for user with user id {}". format(user)) rank_value = 1 for i in uTest_recommended_items[user,0:10]: song_details = small_set[small_set.so_index_value == i].drop_duplicates('so_index_value')[['title','artist_name']] print("The number {} recommended song is {} BY {}".format(rank_value, list(song_details['title'])[0],list(song_details['artist_name'])[0])) rank_value+=1 这里对每一个用户都得到了其对应的推荐结果,并且将结果按照得分值进行排序。
uTest = [27513] #Get estimated rating for test user print("Predictied ratings:") uTest_recommended_items = compute_estimated_matrix(urm, U, S, Vt, uTest, K, True) 计算结果
for user in uTest: print("Recommendation for user with user id {}". format(user)) rank_value = 1 for i in uTest_recommended_items[user,0:10]: song_details = small_set[small_set.so_index_value == i].drop_duplicates('so_index_value')[['title','artist_name']] print("The number {} recommended song is {} BY {}".format(rank_value, list(song_details['title'])[0],list(song_details['artist_name'])[0])) rank_value+=1 
总结: 选择了音乐数据集来进行个性化推荐任务,首先对数据进行预处理和整合,选择两种方法分别完成推荐任务。在相似度计算中根据用户所听过的歌曲在候选集中选择与其最相似的歌曲,存在的问题就是计算时间消耗太多,每一个用户都需要重新计算一遍才能得出推荐结果。在SVD矩阵分解的方法中,首先构建评分矩阵,对其进行SVD分解,然后选择待推荐用户,还原得到其对所有歌曲的估测评分值,最后排序返回结果即可
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/232844.html原文链接:https://javaforall.net


